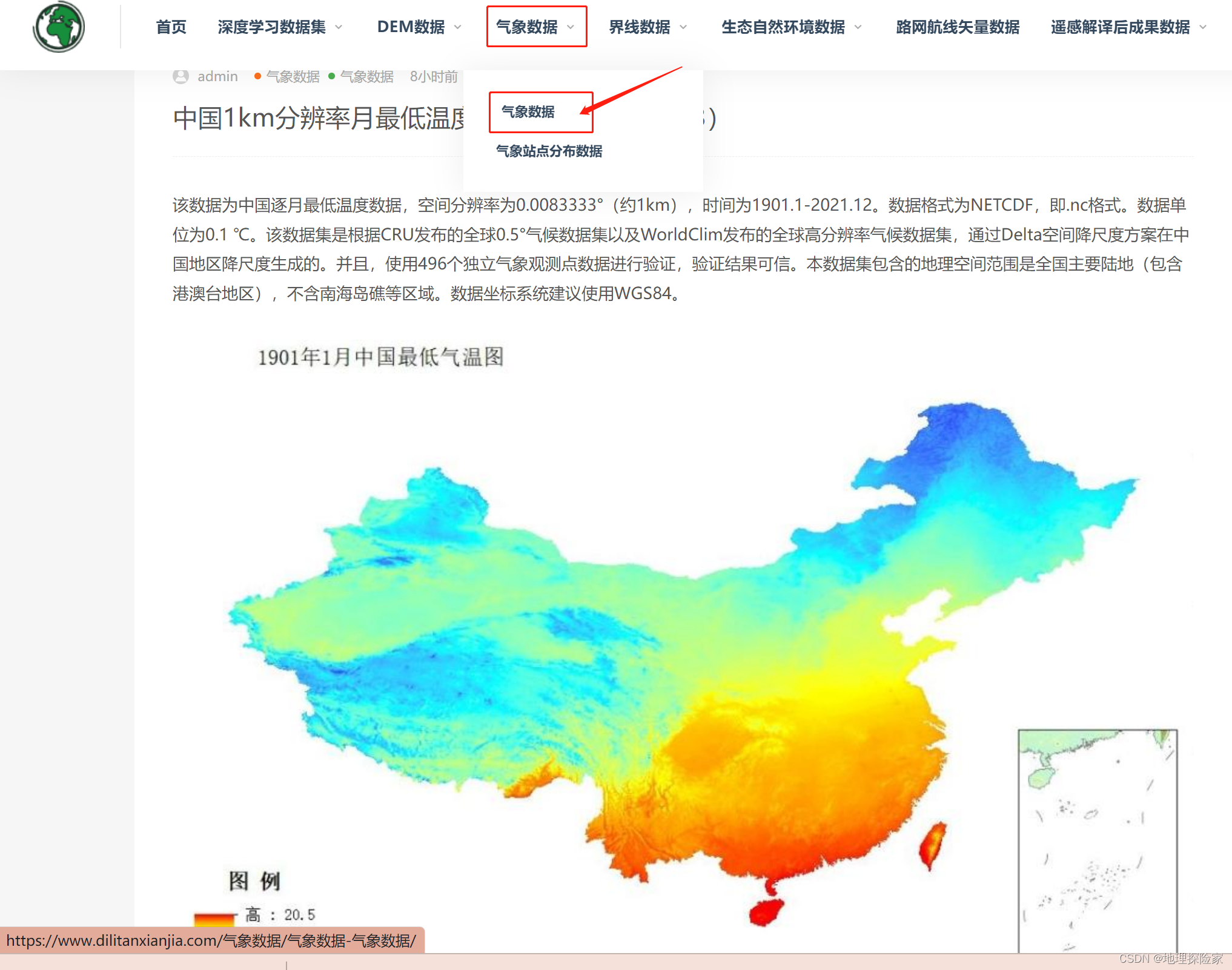
题目
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad" 输出:0 解释:"sad" 在下标 0 和 6 处匹配。 第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:
输入:haystack = "leetcode", needle = "leeto" 输出:-1 解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 104haystack和needle仅由小写英文字符组成
Python
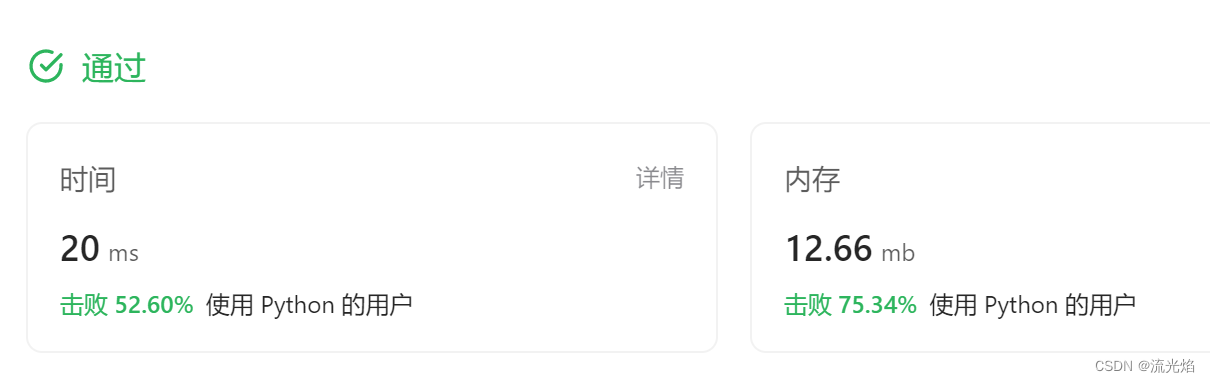
看到这道题的一瞬间,我就想到了Python中的find()函数,所以很快就写好了:
class Solution(object):
def strStr(self, haystack, needle):
return haystack.find(needle)
A=Solution()
haystack ="sadbutsad"
needle ="sad"
print(A.strStr(haystack,needle))
这样虽然简单,但数据不是很好:
C语言
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int strStr(char * haystack, char * needle);
int main()
{
char* haystack ="sadbutsad";
char* needle ="sad";
printf("%d",strStr(haystack,needle));
return 0;
}
//主要函数
int strStr(char * haystack, char * needle)
{
int len1=strlen(haystack),len2=strlen(needle);
for(int i=0;i<=len1-len2;i++)
{
if(haystack[i]==needle[0])
{
if(len2==1)
return i;
int j=1;
for(;j<len2;j++)
{
if(haystack[j+i]!=needle[j])
{
break;
}
}
if(j==len2)
return i;
}
}
return -1;
}但结果不好:
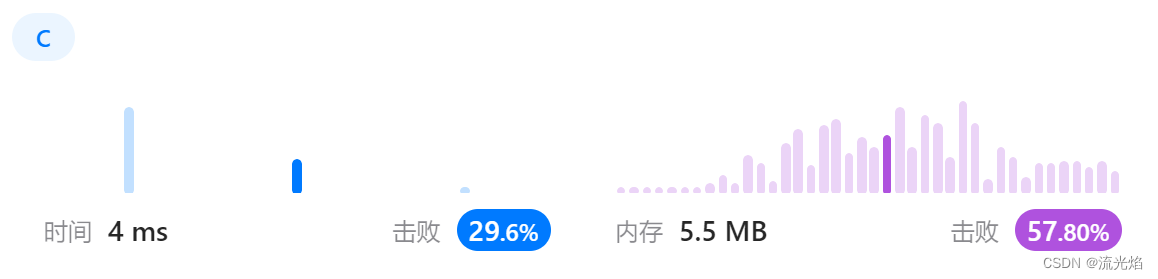
之后,我看了KMP算法,确实巧妙。

我写的C语言代码是在每次 haystack 数组与needle数组比较元素不匹配后,在haystack上移动一位来进行重新比较,进而寻找正确位置。
而KMP算法则是每次移动若干位(根据字符串),进而缩短了时间。
KMP算法代码:
int strStr(char* haystack, char* needle) {
int n = strlen(haystack), m = strlen(needle);
if (m == 0) {
return 0;
}
int pi[m];
pi[0] = 0;
for (int i = 1, j = 0; i < m; i++) {
while (j > 0 && needle[i] != needle[j]) {
j = pi[j - 1];
}
if (needle[i] == needle[j]) {
j++;
}
pi[i] = j;
}
for (int i = 0, j = 0; i < n; i++) {
while (j > 0 && haystack[i] != needle[j]) {
j = pi[j - 1];
}
if (haystack[i] == needle[j]) {
j++;
}
if (j == m) {
return i - m + 1;
}
}
return -1;
}
/*
作者:力扣官方题解
链接:https://leetcode.cn/problems/find-the-index-of-the-first-occurrence-in-a-string/solutions/732236/shi-xian-strstr-by-leetcode-solution-ds6y/
来源:力扣(LeetCode)
*/