文章目录
- 一、CVRP
- 二、MDCVRP
- 2.1 解的编码分析
- 2.2 代码
- 2.3 分割展示
- 三、VRPTW
- 四、MDVRPTW
- 4. 1 解的编码分析
- 4.2 解的代码
- 4.3 结果展示
- 4. 4 MDVRPTW的计算适应度
- 4.5 MDVRPTWd的结果展示图
一、CVRP
见博文《[基因遗传算法]进阶之三:实践CVRP》
二、MDCVRP
参考资料:《Python实现MDCVRP常见求解算法——遗传算法(GA)》
车辆类型单一
车辆容量不小于需求节点最大需求
多车辆基地
各车场车辆总数满足实际需求
2.1 解的编码分析

可以看到第3个图(左下)与第4个图(右下). 每段route的路径是相同的, 区别在于depot不同.只有一个仓库的时候,不需要做选择.而多个仓库的时候,需要对一段route就近选择合适的depot.因此需要定义两个函数:
-
splitRoutes(node_id_list,model) :根据车容量限制要求,分割为多个route.
例如:node_id_list=[3,4,2,0,1,9,8,7,6,5],分割为[ [3,4],[2,0,1,9,8],[7,6,5]] -
selectDepot(route,depot_dict,model): 对每个route选择合适的depot,要求该仓库进出该route的距离最小,且depot可以容纳该车辆(即depot的库存为满).
2.2 代码
- 对route选择合适的depot(多中选一)
## MDCVRP
def selectDepot(route,depot_dict,model):
# 假设route=[2,0,1,9,8],前后都没有depot,只有需求节点的一段序列
# 我们要给这段距离选择一个合适depot
min_in_out_distance=float('inf')#进出route的最小距离
index=None
for _,depot in depot_dict.items():
# 如果depot能够容纳的车的数目>0
if depot.depot_capacity>0:
#当前(选择的)depot到route[0](起点)的距离+routed[-1](终点)到depot的距离
in_out_distance=model.distance_matrix[depot.id,route[0]]+model.distance_matrix[route[-1],depot.id]
# 是否更新 ‘进出route的最小距离'
if in_out_distance<min_in_out_distance:
index=depot.id #记录使(当前)‘距离’的depot的ID号
min_in_out_distance=in_out_distance
if index is None:
print("there is no vehicle to dispatch")#没有车辆去分配
# 在route的首尾插入depot的ID号
route.insert(0,index)
route.append(index)
#对于(已定的)depot,其可容纳的车辆数目减少1个
depot_dict[index].depot_capacity=depot_dict[index].depot_capacity-1
return route,depot_dict
- 对node_id_list(需求节点列表)分割路径
## MDCVRP的分割路径的方法.
def splitRoutes(node_id_list,model):
num_vehicle = 0#存储车的数量,初始为0
vehicle_routes = []#车辆的总路径
route = []#单条路径,如果只有一个depot,直接放入即可.现在是多个,要选择depot
remained_cap = model.vehicle_cap#车的当前容量,初始为满值
depot_dict=copy.deepcopy(model.depot_dict)#depot们的深复制
#设node_id_list=[3,4,2,0,1,9,8,7,6,5]
for node_id in node_id_list:
#当前需求节点:node_id.
if remained_cap - model.demand_dict[node_id].demand >= 0:
# 如果车的当前存货>=节点需求.则路径选择当前节点(放入route中),并完成需求任务
route.append(node_id)
remained_cap = remained_cap - model.demand_dict[node_id].demand
else:
# 如果车不能完成当前节点的任务,则对当前的一段路径就近选择depot
route,depot_dict=selectDepot(route,depot_dict,model)
# 当前路径route已结束,放入总轨迹vehicle_routes中.
vehicle_routes.append(route)
#当前节点作为新route的起点
route = [node_id]
num_vehicle = num_vehicle + 1#数量加1
#新车的当前存货=满货-当前节点的需求
remained_cap =model.vehicle_cap - model.demand_dict[node_id].demand
#对于这段route就近选择合适(可容车)的depot
route, depot_dict = selectDepot(route, depot_dict, model)
vehicle_routes.append(route)
return num_vehicle,vehicle_routes
2.3 分割展示
# 构造初始解
genInitialSol(model)
# 查看个体的基因
print(model.sol_list[0].node_no_seq )
结果:
[4, 71, 10, 31, 75, 89, 19, 32, 70, 92, 54, 90, 80, 13, 41, 74, 21, 37, 99, 85, 16, 30, 50, 3, 52, 0, 34, 29, 11, 60, 49, 1, 91, 69, 24, 57, 81, 26, 46, 79, 38, 2, 72, 97, 27, 35, 28, 94, 62, 56, 20, 7, 51, 88, 67, 47, 66, 64, 63, 83, 36, 95, 45, 40, 44, 58, 5, 6, 86, 39, 14, 53, 96, 77, 73, 33, 48, 87, 9, 76, 12, 55, 59, 68, 65, 22, 93, 82, 61, 23, 84, 43, 15, 42, 18, 98, 25, 8, 17, 78]
node_id_list=model.sol_list[0].node_no_seq #个体的基因的id序列
num_vehicle,vehicle_routes=splitRoutes(node_id_list,model)
print(num_vehicle)
print(vehicle_routes)
结果:
23
[[‘d1’, 4, 71, 10, 31, 75, 89, ‘d1’], [‘d1’, 19, 32, 70, ‘d1’], [‘d1’, 92, 54, 90, ‘d1’], [‘d2’, 80, 13, 41, 74, ‘d2’], [‘d1’, 21, 37, 99, 85, ‘d1’], [‘d1’, 16, 30, 50, 3, 52, ‘d1’], [‘d1’, 0, 34, 29, 11, 60, 49, ‘d1’], [‘d2’, 1, 91, 69, ‘d2’], [‘d1’, 24, 57, ‘d1’], [‘d1’, 81, 26, 46, 79, 38, 2, ‘d1’], [‘d2’, 72, 97, 27, 35, 28, ‘d2’], [‘d2’, 94, 62, ‘d2’], [‘d1’, 56, 20, 7, ‘d1’], [‘d2’, 51, 88, 67, 47, 66, 64, 63, ‘d2’], [‘d2’, 83, 36, 95, 45, ‘d2’], [‘d1’, 40, 44, 58, 5, 6, ‘d1’], [‘d2’, 86, 39, 14, ‘d2’], [‘d2’, 53, 96, ‘d2’], [‘d2’, 77, 73, ‘d2’], [‘d2’, 33, 48, 87, 9, 76, ‘d2’], [‘d2’, 12, 55, 59, ‘d2’], [‘d2’, 68, 65, 22, 93, 82, 61, 23, ‘d2’], [‘d2’, 84, 43, 15, ‘d2’], [‘d2’, 42, 18, 98, 25, 8, 17, 78, ‘d2’]]
三、VRPTW
见参考博文《[基因遗传算法]进阶之四:实践VRPTW》
四、MDVRPTW
这里是对车辆进行了限制?与VRPTW相比,其结构上的变化,应该只是解码过程的变化. 解码后的route_list结构不变,所以后续的求距离时间成本,和计算适应度方法,都是几乎不改变的. 因此,这里重点讨论 如何对MDVRPTW进行解码.
本文参考了《Python实现(MD)VRPTW常见求解算法——遗传算法(GA)》
- 求解MDVRPTW或VRPTW
- 车辆类型单一
- 车辆容量不小于需求节点最大需求
- 车辆路径长度或运行时间无限制
- 需求节点服务成本满足三角不等式
- 节点时间窗至少满足车辆路径只包含一个需求节点的情况
- 多车辆基地或单一
- 各车场车辆总数满足实际需求
4. 1 解的编码分析
4.2 解的代码
- 先计算任意两点间的距离,因为序列的分割需要用到距离和时间距离
# 计算任意两点间的距离
def calDistanceTimeMatrix(model):
# 节点有demand_id_list中的需求节点,有
for i in range(len(model.demand_id_list)):
from_node_id = model.demand_id_list[i]#需求节点1
for j in range(i + 1, len(model.demand_id_list)):
to_node_id = model.demand_id_list[j]#需求节点2
# 求两个节点之间的距离,并保存到矩阵
dist = math.sqrt((model.demand_dict[from_node_id].x_coord - model.demand_dict[to_node_id].x_coord) ** 2
+ (model.demand_dict[from_node_id].y_coord - model.demand_dict[to_node_id].y_coord) ** 2)
model.distance_matrix[from_node_id, to_node_id] = dist
model.distance_matrix[to_node_id, from_node_id] = dist
# 求两个节点之间的时间距离=距离/速度,并保存到时间矩阵
model.time_matrix[from_node_id,to_node_id] = math.ceil(dist/model.vehicle_speed)
model.time_matrix[to_node_id,from_node_id] = math.ceil(dist/model.vehicle_speed)
for _, depot in model.depot_dict.items():
# depot_dict: d1, d2,..分别计算from_node_id与depot的距离
dist = math.sqrt((model.demand_dict[from_node_id].x_coord - depot.x_coord) ** 2
+ (model.demand_dict[from_node_id].y_coord - depot.y_coord) ** 2)
model.distance_matrix[from_node_id, depot.id] = dist
model.distance_matrix[depot.id, from_node_id] = dist
model.time_matrix[from_node_id,depot.id] = math.ceil(dist/model.vehicle_speed)
model.time_matrix[depot.id,from_node_id] = math.ceil(dist/model.vehicle_speed)
- 因为多仓库,在route确定仓库的时候需要选择. 注意,同MDCVRP的没有改变
## MDVRPTW的depot的选择.完全没有改变
def selectDepot(route,depot_dict,model):
min_in_out_distance=float('inf')
index=None
for _,depot in depot_dict.items():
if depot.depot_capacity>0:
in_out_distance=model.distance_matrix[depot.id,route[0]]+model.distance_matrix[route[-1],depot.id]
if in_out_distance<min_in_out_distance:
index=depot.id
min_in_out_distance=in_out_distance
if index is None:
print("there is no vehicle to dispatch")
sys.exit(0)
route.insert(0,index)
route.append(index)
depot_dict[index].depot_capacity=depot_dict[index].depot_capacity-1
return route,depot_dict
- 路径的提取
## MDVRPTW的根据Pred提取路径问题.
# 在VRPTW中只有一个depot,直接加入depot的ID号即可.
#但是现在多个depot,所以要增加一个选择depot的环节.
def extractRoutes(node_id_list,Pred,model):
depot_dict=copy.deepcopy(model.depot_dict)
route_list = []
route = []
label = Pred[node_id_list[0]]
for node_id in node_id_list:
if Pred[node_id] == label:
route.append(node_id)
else:
route, depot_dict=selectDepot(route,depot_dict,model)
route_list.append(route)
route = [node_id]
label = Pred[node_id]
route, depot_dict = selectDepot(route, depot_dict, model)
route_list.append(route)
return route_list
- 序列的分割
##MDVRPTW的路径分割
def splitRoutes(node_id_list,model):
depot=model.depot_id_list[0]#选择depot_id_list中的第一个,作为初始值
V={id:float('inf') for id in model.demand_id_list}
#同VRPTW一样的值函数,初始之设为正无穷
V[depot]=0#初始情况:第一个depot的值函数为0
# 这里设为0,是不区分depotde.只是分割序列,使得某些节点处回到depot.
# 具体选择哪一个,可以在 ‘函数selectDepot’中确定.
Pred={id:depot for id in model.demand_id_list}
# 初始情况:假设所有的需求节点都映射给第一个depot
for i in range(len(node_id_list)):
n_1=node_id_list[i]#序列中的当前节点
demand=0#depot的初始需求
departure=0#depot的初始离开时间
j=i#j,j+1,...查看当前节点后的所有节点可以是后续节点
cost=0
while True:
n_2 = node_id_list[j] #序列i后的某个节点或本身,我将其命名为 检测节点
demand = demand + model.demand_dict[n_2].demand#累计需求
if n_1 == n_2:
# 当前节点=检测节点. 当前节点要返回仓库的时候
#计算车从(当前节点n_1, depot)的最早到达时间
arrival= max(model.demand_dict[n_2].start_time,model.depot_dict[depot].start_time+model.time_matrix[depot,n_2])
#计算从depot离开的最早时间
departure=arrival+model.demand_dict[n_2].service_time+model.time_matrix[n_2,depot]
# 确定优化目标,求距离最小?时间最小?
if model.opt_type == 0:
cost=model.distance_matrix[depot,n_2]*2
else:
cost=model.time_matrix[depot,n_2]*2
else:
n_3=node_id_list[j-1]#检测节点的前一个节点,n1和n2不同
arrival= max(departure-model.time_matrix[n_3,depot]+model.time_matrix[n_3,n_2],model.demand_dict[n_2].start_time)
departure=arrival+model.demand_dict[n_2].service_time+model.time_matrix[n_2,depot]
# 确定成本函数
if model.opt_type == 0:
cost=cost-model.distance_matrix[n_3,depot]+model.distance_matrix[n_3,n_2]+model.distance_matrix[n_2,depot]
else:
cost=cost-model.time_matrix[n_3,depot]+model.time_matrix[n_3,n_2]\
+model.demand_dict[n_2].start_time-departure-model.time_matrix[n_3,depot]+model.time_matrix[n_3,n_2]\
+model.time_matrix[n_2,depot]
if demand<=model.vehicle_cap and departure-model.time_matrix[n_2,depot] <= model.demand_dict[n_2].end_time:
# 累计需求<车的当前存货 且 离开时间<depot的服务结束时间
if departure <= model.depot_dict[depot].end_time:
n_4=node_id_list[i-1] if i-1>=0 else depot
if V[n_4]+cost <= V[n_2]:
# 更新值函数并记录节点映射关系
V[n_2]=V[n_4]+cost
Pred[n_2]=i-1
j=j+1
else:
break
if j==len(node_id_list):
break
route_list= extractRoutes(node_id_list,Pred,model)
return len(route_list),route_list
可能存在的错误: Sol中保存节点ID序列的话. 所在的属性,sol.node_id-list或者是sol.node_no_seq
4.3 结果展示
node_id_list=model.sol_list[0].node_no_seq
route_num,route_list=splitRoutes(node_id_list,model)
print(route_num)
print(route_list)
out:
58
[[‘d1’, 35, 48, ‘d1’], [‘d2’, 87, ‘d2’], [‘d2’, 60, ‘d2’], [‘d2’, 70, 72, ‘d2’], [‘d1’, 43, 33, ‘d1’], [‘d1’, 18, 1, ‘d1’], [‘d2’, 89, ‘d2’], [‘d2’, 56, 63, ‘d2’], [‘d1’, 97, 11, 0, ‘d1’], [‘d3’, 45, ‘d3’], [‘d2’, 7, 13, 79, ‘d2’], [‘d1’, 16, ‘d1’], [‘d2’, 62, ‘d2’], [‘d1’, 31, 51, ‘d1’], [‘d2’, 52, ‘d2’], [‘d2’, 66, 90, ‘d2’], [‘d3’, 95, 76, 88, ‘d3’], [‘d1’, 83, 8, ‘d1’], [‘d1’, 34, 21, ‘d1’], [‘d2’, 58, ‘d2’], [‘d2’, 55, ‘d2’], [‘d3’, 82, 99, 46, ‘d3’], [‘d2’, 59, 68, ‘d2’], [‘d2’, 71, ‘d2’], [‘d1’, 12, 69, ‘d1’], [‘d1’, 92, 22, ‘d1’], [‘d1’, 93, ‘d1’], [‘d2’, 77, 78, ‘d2’], [‘d2’, 81, ‘d2’], [‘d1’, 26, 15, ‘d1’], [‘d2’, 53, ‘d2’], [‘d3’, 64, 28, 20, ‘d3’], [‘d1’, 3, ‘d1’], [‘d1’, 50, ‘d1’], [‘d1’, 4, 49, ‘d1’], [‘d2’, 84, ‘d2’], [‘d1’, 9, ‘d1’], [‘d2’, 75, ‘d2’], [‘d1’, 19, 96, ‘d1’], [‘d1’, 86, 17, 29, ‘d1’], [‘d3’, 39, 91, ‘d3’], [‘d2’, 42, 37, 67, ‘d2’], [‘d1’, 10, ‘d1’], [‘d1’, 36, 47, ‘d1’], [‘d2’, 85, 5, 65, ‘d2’], [‘d3’, 27, ‘d3’], [‘d2’, 54, ‘d2’], [‘d3’, 23, 98, ‘d3’], [‘d3’, 32, ‘d3’], [‘d2’, 80, 61, ‘d2’], [‘d3’, 41, 44, ‘d3’], [‘d2’, 73, 38, ‘d2’], [‘d3’, 14, ‘d3’], [‘d3’, 6, ‘d3’], [‘d3’, 30, 74, ‘d3’], [‘d3’, 40, 57, 25, ‘d3’], [‘d3’, 2, 24, ‘d3’], [‘d3’, 94, ‘d3’]]
4. 4 MDVRPTW的计算适应度
- 计算路径的行驶成本(距离和时间)
def calTravelCost(route_list,model):
timetable_list=[]#每个route的时间列表?
cost_of_distance=0# 距离成本初始设为0
cost_of_time=0# 时间成本初始设为0
# route_list:[[d1,3,4,d1],[d3,2,0,1,9,8,d3],[d2,7,6,5,d2]]
for route in route_list:
timetable=[]
for i in range(len(route)):
if i == 0:
# 节点为起始depot
depot_id=route[i]
next_node_id=route[i+1]
travel_time=model.time_matrix[depot_id,next_node_id]
departure=max(0,model.demand_dict[next_node_id].start_time-travel_time)
#计算depot的离开时间
timetable.append((departure,departure))#起始depot的(到达,离开)时间点
elif 1<= i <= len(route)-2:
#中间的需求节点
last_node_id=route[i-1]#上一个节点的id
current_node_id=route[i]#当前节点的id
current_node = model.demand_dict[current_node_id]#当前节点
travel_time=model.time_matrix[last_node_id,current_node_id]#行驶时间
arrival=max(timetable[-1][1]+travel_time,current_node.start_time)#当前节点的最早到达时间
departure=arrival+current_node.service_time#当前节点的离开时间
timetable.append((arrival,departure))
#累计距离成本
cost_of_distance = cost_of_distance + model.distance_matrix[last_node_id,current_node_id]
#累计时间成本
cost_of_time += model.time_matrix[last_node_id,current_node_id] + current_node.service_time\
+max(current_node.start_time-timetable[-1][1]+travel_time,0)
## (上个节点到当前节点)移动时间+当前节点的服务时间+等待时间
else:
#为终点depot
last_node_id = route[i - 1]#最后一个需求节点
depot_id=route[i]#终点depot
travel_time = model.time_matrix[last_node_id,depot_id]#行驶时间
departure = timetable[-1][1]+travel_time#离开时间
timetable.append((departure,departure))
cost_of_distance +=model.distance_matrix[last_node_id,depot_id]
cost_of_time+=model.time_matrix[last_node_id,depot_id]
timetable_list.append(timetable)
return timetable_list,cost_of_time,cost_of_distance
- 计算种群的适应度
在这里主要选择以距离成本或者时间成本作为目标函数.
def calFitness(model):
max_obj=-float('inf')
best_sol=Sol()
best_sol.obj=float('inf')
# calculate travel distance and travel time
for sol in model.sol_list:
node_id_list=copy.deepcopy(sol.node_id_list)
num_vehicle, route_list = splitRoutes(node_id_list, model)
# travel cost
timetable_list,cost_of_time,cost_of_distance =calTravelCost(route_list,model)
if model.opt_type == 0:
sol.obj=cost_of_distance
else:
sol.obj=cost_of_time
sol.route_list = route_list
sol.timetable_list = timetable_list
sol.cost_of_distance=cost_of_distance
sol.cost_of_time=cost_of_time
if sol.obj > max_obj:
max_obj=sol.obj
if sol.obj < best_sol.obj:
best_sol=copy.deepcopy(sol)
# calculate fitness
for sol in model.sol_list:
sol.fitness=max_obj-sol.obj
if best_sol.obj<model.best_sol.obj:
model.best_sol=copy.deepcopy(best_sol)
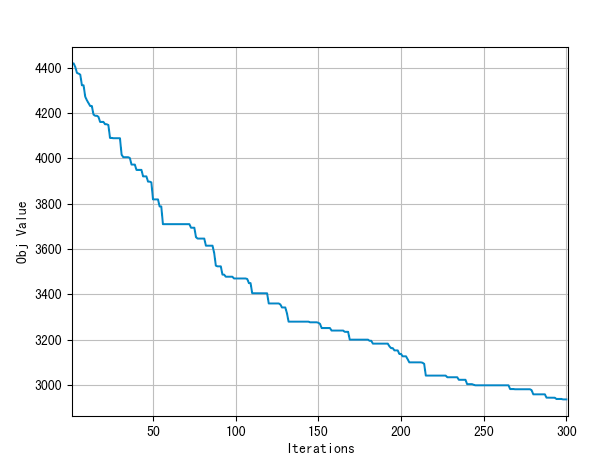
4.5 MDVRPTWd的结果展示图