引入
当查看string类型的变量所占的空间大小时,会发现是16字节(64位机器)。
str := "hello"
fmt.Println(unsafe.Sizeof(str)) // 16
也许你会好奇,为什么是16字节,它的底层存储模型是什么样子的。
源码分析
底层结构
在src/runtime/string.go中,定义了string的结构:
type stringStruct struct {
str unsafe.Pointer
len int
}
string底层结构是一个结构体,它有两个字段:
str unsafe.Pointer: 该字段指向了string底层的byte数组(切片)len int: 该字段确定了string字符串的长度
unsafe.Pointer和int类型的字段分别占用8个字节空间,所以string类型的变量占用16字节(内存对齐后)空间
常规内容
在C语言中,使用'\0'表示字符串的结尾。在Go语言中,使用len这个字段指定了字符串的长度,知道字符串的长度,自然也就知道字符串的结尾在哪。
Go语言中,字符串一经定义,可通过指定下标形式进行访问,但不可修改,即string类型变量中的字符是不可以被修改的。
str := "abcdef"
fmt.Println(str[0]) // 97
str[0] = 'A' // cannot assign to str[0] (value of type byte)
字符串可以被转换成byte切片,可对切片进行修改,但即使修改了byte切片,也不会对原字符串变量造成任何影响。
str := "hello"
arr := []byte(str)
arr[0] = 'H'
fmt.Println(str) // hello
Go中所有字符都是以utf-8格式进行编码的。UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,最初由肯·汤普逊和罗布·派克提出。在处理字符串时,通常你不知道字符串中每个字符到底占用1个字节还是2~4个字节的空间。在需要索引字符串中的某个字符时,通常会将字符串类型强制转换为[]rune类型。
rune类型
rune类型是int32类型的别名。
定义位置位于src/builtin/builtin.go
// int32 is the set of all signed 32-bit integers.
// Range: -2147483648 through 2147483647.
type int32 int32
...
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
rune用于区分字符值和整数值,当然如果你任性,偏要使用int32类型来保存1个字符,那也不是不可以的,但是显得十分不专业(土、屯、low)。
str := "hello 你好"
str1 := []byte(str)
str2 := []rune(str)
fmt.Println(len(str1)) // 12
fmt.Println(len(str2)) // 8
fmt.Println(string(str1[6])) // ä
fmt.Println(string(str2[6])) // 你
分别打印两个序列
fmt.Println(str1) // [104 101 108 108 111 32 228 189 160 229 165 189]
fmt.Println(str2) // [104 101 108 108 111 32 20320 22909]
str对应的内存结构如下:
stringStruct:
str ---- len----12
|
-----------------
| h | 0 <- 104
| e | 1 <- 101
| l | 2 <- 108
| l | 3 <- 108
| o | 4 <- 111
| | 5 <- 32
| 你 | 6 <- 228 ---------- utf-8---------------
| | 7 <- 189 |
| | 8 <- 160------------20320---------------
| 好 | 9 <- 229------------utf-8---------------
| | 10 <- 165 |
| | 11 <- 189-----------22909----------------
-----------------
将byte切片强转成string后,修改byte切片,不会对强转后的string造成影响
bs := []byte("hello")
str := string(bs) // hello
fmt.Println(str)
bs = []byte("world")
fmt.Println(str) // hello
string的运行时源码位于 src/runtime/string.go中
// The constant is known to the compiler.
// There is no fundamental theory behind this number.
const tmpStringBufSize = 32
type tmpBuf [tmpStringBufSize]byte
打开该文件,第一眼,你看见了这俩货。 tmpBuf这个32字节长度的byte数组类型,其实是在string类型变量做拼接(concat)时使用的。如果几个字符串长度加在一起小于等于32字节,那么go运行时就直接将其在栈中拼接(借助tmpBuf指针变量),否则就要去堆中开辟合理的空间,再进行拼接了。
字符串拼接
对于不同个数的字符串拼接,选取不同的字符串拼接函数
func concatstring2(buf *tmpBuf, a0, a1 string) string {
return concatstrings(buf, []string{a0, a1})
}
func concatstring3(buf *tmpBuf, a0, a1, a2 string) string {
return concatstrings(buf, []string{a0, a1, a2})
}
func concatstring4(buf *tmpBuf, a0, a1, a2, a3 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3})
}
func concatstring5(buf *tmpBuf, a0, a1, a2, a3, a4 string) string {
return concatstrings(buf, []string{a0, a1, a2, a3, a4})
}
他们都调用了concatstrings函数
// concatstrings implements a Go string concatenation x+y+z+...
// The operands are passed in the slice a.
// If buf != nil, the compiler has determined that the result does not
// escape the calling function, so the string data can be stored in buf
// if small enough.
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0 // 所有字符串的总长度
count := 0 // 字符串的个数
for i, x := range a {
n := len(x)
if n == 0 { // 当前字符串长度为0,continue
continue
}
if l+n < l { // 长度溢出时
throw("string concatenation too long")
}
l += n // 长度 + n
count++ // 字符串个数+1
idx = i // 当前index
}
if count == 0 {
return ""
}
// If there is just one string and either it is not on the stack
// or our result does not escape the calling frame (buf != nil),
// then we can return that string directly.
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx] // 如果只有一个字符串,缓冲区不为空,或不在栈上,直接返回
}
s, b := rawstringtmp(buf, l) // 传入默认缓冲区,和字符串总长度, 返回字符串的和字符串中str对应的底层切片
for _, x := range a {
copy(b, x) // 将所有字符拷贝进字符串的底层切片 拼接的核心逻辑
b = b[len(x):]
}
return s
}
func rawstringtmp(buf *tmpBuf, l int) (s string, b []byte) {
if buf != nil && l <= len(buf) { // 字符串总长度 <= 默认缓冲区大小
b = buf[:l] // 对默认缓冲区进行截取
s = slicebytetostringtmp(&b[0], len(b)) // 对返回值的s 的len进行赋值,并将s 的str 绑定到buf
} else {
s, b = rawstring(l) // 对返回值的s的len进行赋值,并将s的str绑定到在堆空间新开辟的地址上
}
return
}
// slicebytetostringtmp returns a "string" referring to the actual []byte bytes.
//
// Callers need to ensure that the returned string will not be used after
// the calling goroutine modifies the original slice or synchronizes with
// another goroutine.
//
// The function is only called when instrumenting
// and otherwise intrinsified by the compiler.
//
// Some internal compiler optimizations use this function.
// - Used for m[T1{... Tn{..., string(k), ...} ...}] and m[string(k)]
// where k is []byte, T1 to Tn is a nesting of struct and array literals.
// - Used for "<"+string(b)+">" concatenation where b is []byte.
// - Used for string(b)=="foo" comparison where b is []byte.
func slicebytetostringtmp(ptr *byte, n int) (str string) {
if raceenabled && n > 0 {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
abi.FuncPCABIInternal(slicebytetostringtmp))
}
if msanenabled && n > 0 {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
if asanenabled && n > 0 {
asanread(unsafe.Pointer(ptr), uintptr(n))
}
stringStructOf(&str).str = unsafe.Pointer(ptr)
stringStructOf(&str).len = n
return
}
在堆内存重新分配空间
// rawstring allocates storage for a new string. The returned
// string and byte slice both refer to the same storage.
// The storage is not zeroed. Callers should use
// b to set the string contents and then drop b.
func rawstring(size int) (s string, b []byte) {
p := mallocgc(uintptr(size), nil, false)
stringStructOf(&s).str = p
stringStructOf(&s).len = size
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}
画个图描述一下
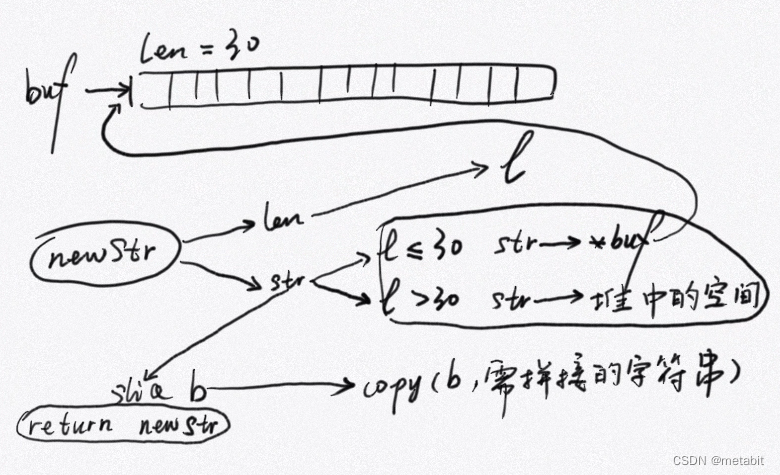
字符串拼接的核心逻辑是:计算所要拼接的字符串长度,将长度赋值给待返回字符串底层的len字段;分配合理的存储空间(栈上或堆上),将存储空间的指针赋值给待返回字符串底层的str字段,返回栈上或堆上存储空间的切片,对切片使用copy内置函数进行填充,即对字符串的str字段进行拼接。
用代码模拟一下
array := [30]byte{}
str := *(*string)(unsafe.Pointer(&struct {
str unsafe.Pointer
len int
}{
str: unsafe.Pointer(&array),
len: len(array),
}))
fmt.Println(str)
fmt.Println(len(str))
copy(array[:], "hello world") //
fmt.Println(str) // 30
copy(array[12:], "你好世界") // hello world
fmt.Println(str) // hello world你好世界
强制转换byte切片到string——string([]byte)
// slicebytetostring converts a byte slice to a string.
// It is inserted by the compiler into generated code.
// ptr is a pointer to the first element of the slice;
// n is the length of the slice.
// Buf is a fixed-size buffer for the result,
// it is not nil if the result does not escape.
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) {
if n == 0 {
// Turns out to be a relatively common case.
// Consider that you want to parse out data between parens in "foo()bar",
// you find the indices and convert the subslice to string.
return ""
}
if raceenabled {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
abi.FuncPCABIInternal(slicebytetostring))
}
if msanenabled {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
if asanenabled {
asanread(unsafe.Pointer(ptr), uintptr(n))
}
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if goarch.BigEndian { // 大端存储
p = add(p, 7)
}
stringStructOf(&str).str = p // str 赋指针
stringStructOf(&str).len = 1 // len 赋字符个数
return
}
var p unsafe.Pointer
if buf != nil && n <= len(buf) { // slice长度 <= 30 则借助buf空间在栈内赋值
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false) // 分配可被gc的空间
}
stringStructOf(&str).str = p
stringStructOf(&str).len = n
memmove(p, unsafe.Pointer(ptr), uintptr(n)) // 移动ptr指向的底层数组中的n个字符到新的空间p
return
}
如果只有一个字符,检查大端或小端后,直接赋值返回即可
如果sice的长度<=30,则不用开辟堆空间,直接借助buf在栈内操作
如果slice的长度>30,则分配堆空间
对新分配的空间赋值,返回
string 强转 byte slice —— []byte(string)
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
string长度 <= 30 借助buf,否则在堆中创建空间,使用 copy 复制原值即可
[]rune(string)
func stringtoslicerune(buf *[tmpStringBufSize]rune, s string) []rune {
// two passes.
// unlike slicerunetostring, no race because strings are immutable.
n := 0
for range s { // 统计字符个数
n++
}
var a []rune
if buf != nil && n <= len(buf) { //
*buf = [tmpStringBufSize]rune{}
a = buf[:n]
} else {
a = rawruneslice(n)
}
n = 0
for _, r := range s {
a[n] = r
n++
}
return a
}
不需要竞态检测,因为string是不可变的
统计字符个数
在栈内(借助原有的buf)或堆内完成空间分配
逐个赋值
返回
string([]rune)
func slicerunetostring(buf *tmpBuf, a []rune) string {
if raceenabled && len(a) > 0 {
racereadrangepc(unsafe.Pointer(&a[0]),
uintptr(len(a))*unsafe.Sizeof(a[0]),
getcallerpc(),
abi.FuncPCABIInternal(slicerunetostring))
}
if msanenabled && len(a) > 0 {
msanread(unsafe.Pointer(&a[0]), uintptr(len(a))*unsafe.Sizeof(a[0]))
}
if asanenabled && len(a) > 0 {
asanread(unsafe.Pointer(&a[0]), uintptr(len(a))*unsafe.Sizeof(a[0]))
}
var dum [4]byte
size1 := 0
for _, r := range a {
size1 += encoderune(dum[:], r) // 返回该rune类型占用多少byte
}
s, b := rawstringtmp(buf, size1+3)
size2 := 0
for _, r := range a {
// check for race 竞态检测
if size2 >= size1 {
break
}
size2 += encoderune(b[size2:], r)
}
return s[:size2]
}
剩下几个函数,都比较简单,暂不做分析。