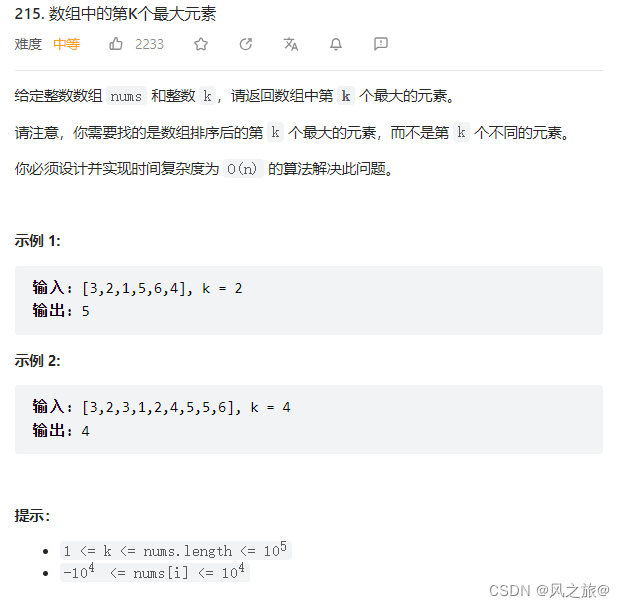
题目链接:力扣
解题思路:
方法一:基于快速排序
因为题目中只需要找到第k大的元素,而快速排序中,每一趟排序都可以确定一个最终元素的位置。
当使用快速排序对数组进行降序排序时,那么如果有一趟排序过程中,确定元素的最终位置为k-1(索引从0开始),那么,该元素就是第k大的元素。
具体思想下:
- 利用快排,对数组num[left,...,right]进行降序排序,在一趟排序过程中,可以确定一个元素的最终位置p,将数组划分为三部分,num[left,...,p-1],nums[p],nums[p+1,right],并且满足
- num[left,...,p-1] >= nums[p]
- num[p+1,right] <=nums[p]
- 即p位置以前的元素是数组中比p位置元素大的元素(此时p位置以前的元素不一定有序,但是肯定都大于等于p位置的元素),而num[p]是第p+1大的元素
- 因为需要找到的是第k大的元素:
- 如果k < p,那么第k大的元素肯定在num[left,...,p-1]内,这个时候只需要对右半部分区间进行快排
- 如果k > p,那么第k大的元素肯定在nums[p+1,right]区间内,这个时候只需要对左半部分区间进行快排
- 如果 p= k-1,那么nums[p]就是第k大的元素
- 注意这种方式并不要求最终数组中的元素有序,每次只会对左半部分或者右半部分进行快排,减少了一半的快排调用
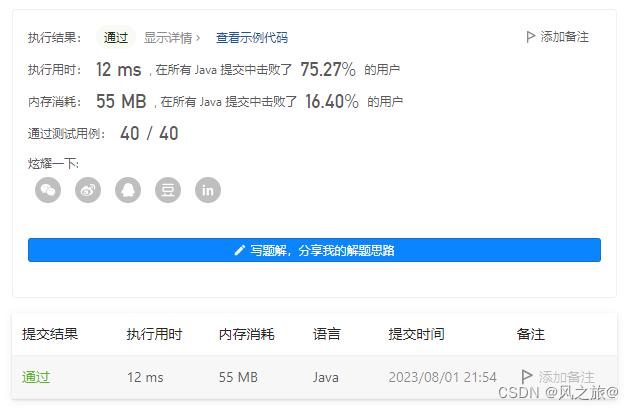
AC代码:
class Solution {
public static int findKthLargest(int[] nums, int k) {
return quickSortFindK(nums, 0, nums.length - 1, k);
}
public static int quickSortFindK(int[] nums, int left, int right, int k) {
//选取枢轴元素
int pivot = nums[left];
int low = left;
int high = right;
while (low < high) {
while (low < high && nums[high] <= pivot)
high--;
nums[low] = nums[high];
while (low < high && nums[low] >= pivot)
low++;
nums[high] = nums[low];
}
//low(或者right)就是这趟排序中枢轴元素的最终位置
nums[low] = pivot;
if (low == k - 1) {
return pivot;
} else if (low > k - 1) {
return quickSortFindK(nums, left, low - 1, k);
} else {
return quickSortFindK(nums, low + 1, right, k);
}
}
} 
快速排序的最好时间复杂度是O(nlogn),最坏时间复杂度为O(n^2),平均时间复杂度为O(nlogn)
快速排序在元素有序的情况下效率是最低。
不过可以通过在某些情况下,快速排序可以达到期望为线性的时间复杂度,即O(n),也就是在每次排序前随机的交换两个元素(个人理解可能是为了让元素变乱,不那么有序,越乱越快,算法导论中在9.2 期望为线性的选择算法进行了证明,还没有学习,先在此记录下),它的时间代价的期望是 O(n)
具体代码实现,就是在排序前,加上下面的代码
//随机生成一个位置,该位置的范围为[left,right]
//然后将该位置的元素与最后一个元素进行交换,让数组变得不那么有序,
//放置出现有序的情况下快排的时间复杂度退化为o(n^2)
int randomIndex = random.nextInt(right - left + 1) + left;
int tem = nums[randomIndex];
nums[randomIndex] = nums[right];
nums[right] = tem;AC代码:
class Solution {
static Random random = new Random();
public static int findKthLargest(int[] nums, int k) {
return quickSortFindK(nums, 0, nums.length - 1, k);
}
public static int quickSortFindK(int[] nums, int left, int right, int k) {
int randomIndex = random.nextInt(right - left + 1) + left;
int tem = nums[randomIndex];
nums[randomIndex] = nums[right];
nums[right] = tem;
int pivot = nums[left];
int low = left;
int high = right;
while (low < high) {
while (low < high && nums[high] <= pivot)
high--;
nums[low] = nums[high];
while (low < high && nums[low] >= pivot)
low++;
nums[high] = nums[low];
}
nums[low] = pivot;
if (low == k - 1) {
return pivot;
} else if (low > k - 1) {
return quickSortFindK(nums, left, low - 1, k);
} else {
return quickSortFindK(nums, low + 1, right, k);
}
}
}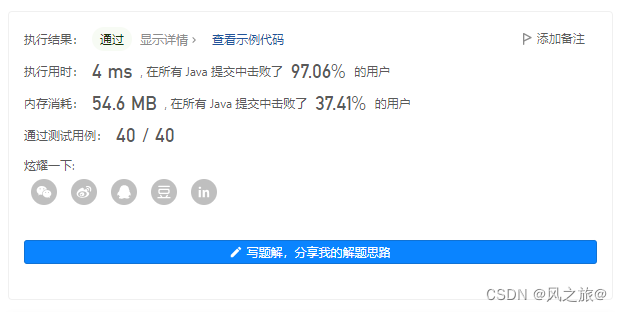
时间上确实有了一些提升
解法二:堆排序。
建立小根堆,最后让小根堆里的元素个数保持在k个,那么此时栈顶的元素就是k个元素中最小的,即第k大的元素
可以通过优先级队列来模拟小根堆
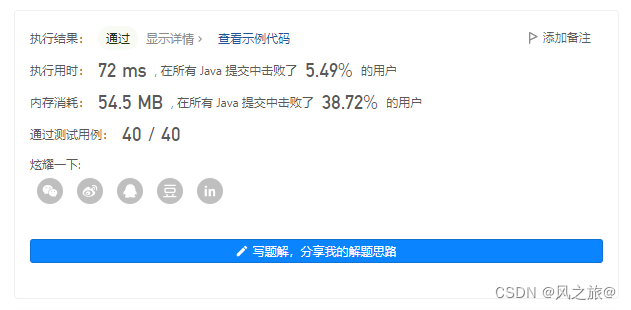
AC代码
class Solution {
public int findKthLargest(int[] nums, int k) {
PriorityQueue<Integer> queue = new PriorityQueue<>();
for (int num : nums) {
//已经有k个元素了,当前元素比堆顶元素还小,不可能是第k大的元素,跳过
if (queue.size()==k&&queue.peek()>=num){
continue;
}
queue.offer(num);
}
while (queue.size()>k){
queue.poll();
}
return queue.peek();
}
}
解法三:大根堆
- 对于区间[0,n]建立大根堆后,此时堆顶元素nums[0]为最大值,可以将堆顶元素与最后一个元素交换,即将最大值移动到数组最后,
- 然后将[0,n-1]区间调整为大根堆,此时堆顶nums[0]就是第二大的值,将堆顶元素与倒数第二个元素交换,即倒数第二大的值移动到数组倒数第二个位置
- 然后将[0,n-2]区间调整为大根堆...
- 调整 k-1此后的大根堆,此时的堆顶元素就是第k大的元素
大根堆可以使用优先级队列实现,传递一个降序的比较器。
这里复习下堆排序,手动写了一个大根堆
AC代码:
class Solution {
public static int findKthLargest(int[] nums, int k) {
createHeap(nums);
for (int i = nums.length - 1; i > nums.length - k; i--) {
int tem = nums[0];
nums[0] = nums[i];
nums[i] = tem;
heapAdjust(nums, 0, i - 1);
}
return nums[0];
}
//建初堆
public static void createHeap(int[] nums) {
for (int i = nums.length / 2 - 1; i >= 0; i--) {
heapAdjust(nums, i, nums.length-1);
}
}
/*
调整成大根堆
nums[begin+1,end]已经是大根堆,
将nums[begin,end]调整为以nums[begin]为根的大根堆
*/
public static void heapAdjust(int[] nums, int begin, int end) {
int tem = nums[begin];
for (int i = 2 * begin + 1; i <= end; i = i * 2 + 1) {
if (i+1 <= end && nums[i] < nums[i+1])
//j为左右子树中较大的子树的下标
i++;
//tem大于左右子树,已经是大根堆,退出
if (tem >= nums[i])
break;
nums[begin] = nums[i];
//更新待插入的位置
begin = i;
}
//tem应该存放的位置
nums[begin] = tem;
}
}