目录
一、Redis 是怎么存储数据的?
二、Redis 具体是按照什么样的策略来实现持久化的?
2.1、RDB(Redis Database)
2.1.1、触发机制
2.1.2、bgsave 命令处理流程
2.1.3、RDB 文件的处理
2.1.4、演示效果
1)手动执行 bgsave
2)自动执行 bgsave
3)观察 bgsave 执行文件替换效果
4)实操问题:如果把 rdb 文件故意改坏了,会咋样?
2.1.5、RDB 的优缺点
2.2、AOF(append only file)
2.2.1、开启 aof 功能
2.2.2、刷新缓冲区策略
2.2.3、重写机制(rewrite)
2.2.4、AOF 重写流程
2.3、混合持久化
一、Redis 是怎么存储数据的?
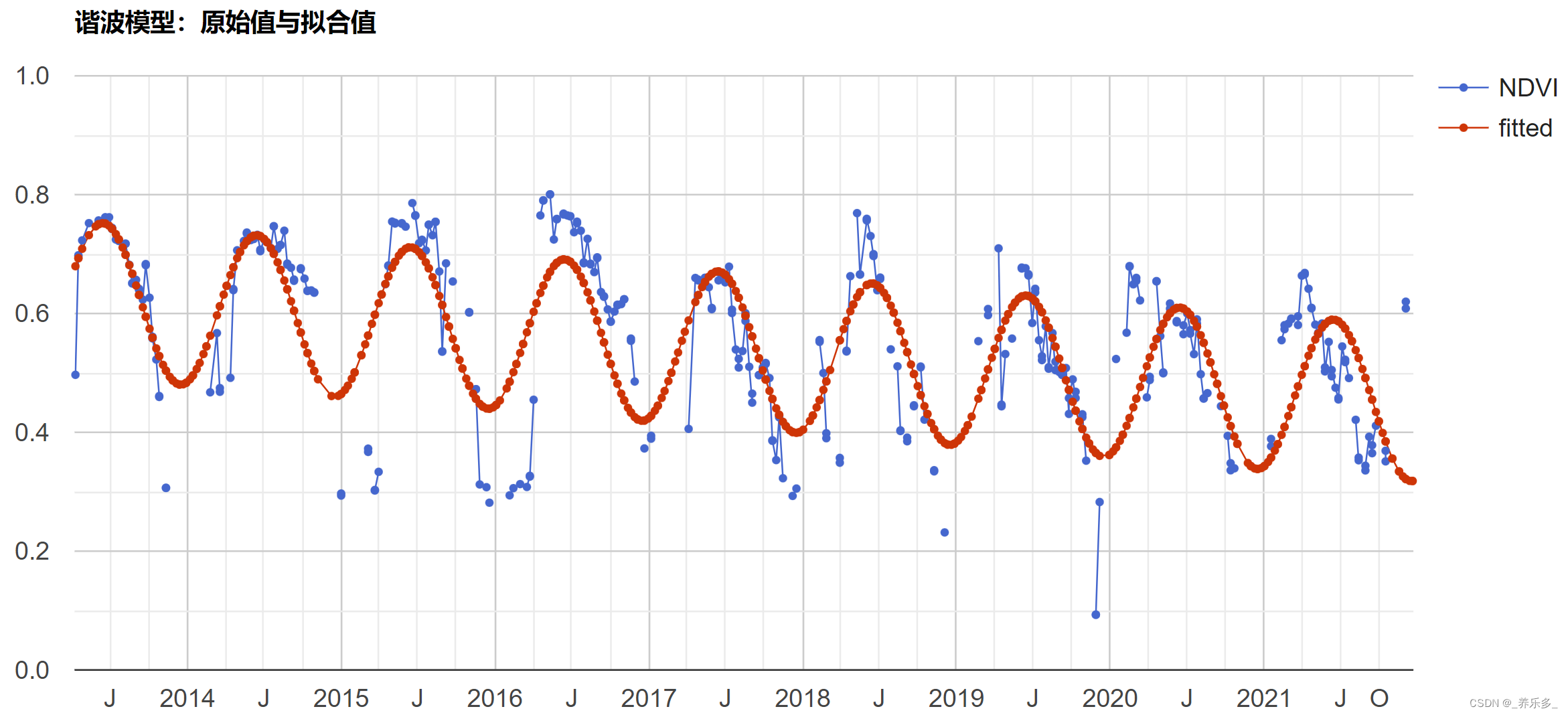
Redis 为了考虑速度和数据的持久化,采取内存 + 硬盘的方式存储存储数据,并且这两份数据理论上是相同的(实际上可能存在小的差异,具体看如何进行持久化)。
具体的,如下:
- 当需要插入一个新的数据的时候,就需要吧这个数据,同时写入到内存和硬盘(这里有很多种存储策略);
- 当查询某一个数据的时候,直接从内存读取;
- 硬盘中的数据知识在 redis 重启的时候,用来恢复内存中的数据.
这样做的代价就是消耗了更多的内存空间(同一份数据,存储两份),但是毕竟硬盘比较便宜,这样的开销并不会带来太多的成本.
二、Redis 具体是按照什么样的策略来实现持久化的?
Redis 持久化是通过两种策略实现的,一种是 定期备份——RDB(Redis DataBase),另一种是 实时备份——AOF(Append Only File).
2.1、RDB(Redis Database)
RDB 会定期把 Redis 内存中的所有数据,以二进制的形式都写入硬盘,生成一个“快照”.(生成一个 rdb 文件,放在 redis 的工作目录中)
“快照”:这就像是某个案发现场,警察来了,拉上警戒线,然后警察们就开始忙碌的拍照,记录现场,后续就可以根据这些记录的照片来还原出现场当时发生了什么~
Redis 给内存中当前存储的这些数据,赶紧拍照,生成一个文件,存储在硬盘中~
2.1.1、触发机制
“定期”具体来说,又有两种方式:
1.手动触发
程序员通过 redis 客户端,执行特定的命令,来触发快照的生成:
save:执行 save 的时候,redis 就会全力以赴的进行“快照生成”操作,此时就会阻塞 redis 的其他客户端命令,导致类似于 keys * 的后果,也因此一般不建议使用.
dgsave:dg(background 后面),也就是后台处理的意思,不会影响到 Redis 服务器处理其他客户端的请求和命令.
Ps:这后台处理是怎么做到的?难道是多进程么?并非如此,实际上这是一个 并发编程 的场景,此处 redis 使用的是 “多进程” 的方式来完成并发编程。实现 bgsave.
2.自动触发
自动触发是需要在 Redis 的配置文件中设置的,让 Redis 每隔多长时间 / 每产生多少次修改就触发.
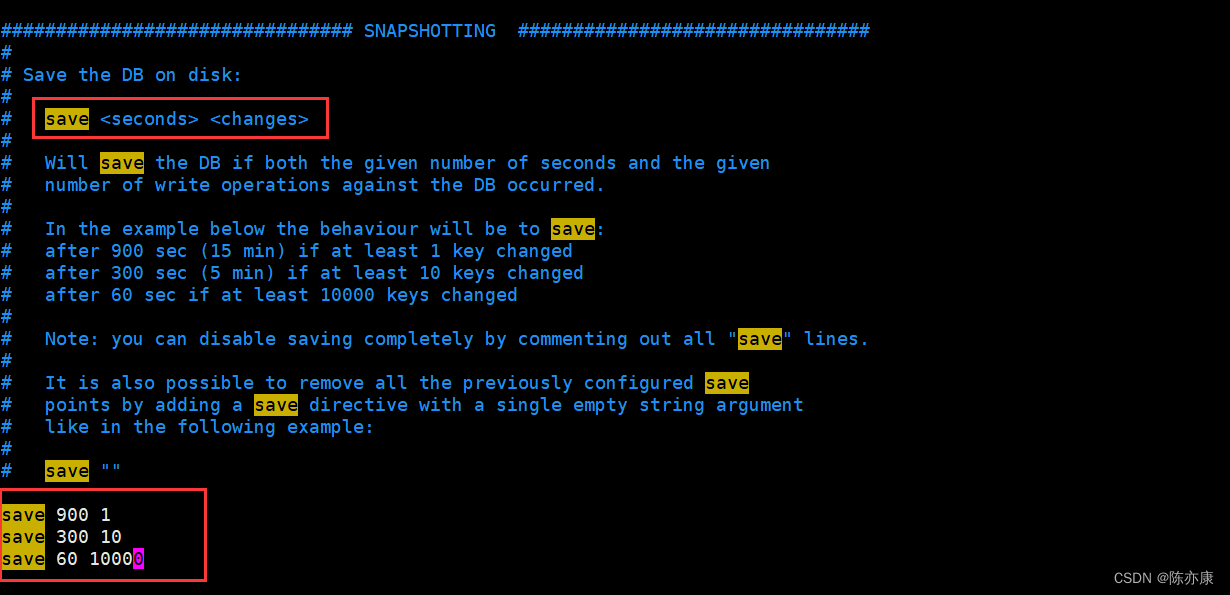
此处的数值都是可以进行修改的,虽然可以自由配置,但是修改这些数据要有一个基本原则:申城一次 rdb 快照,成本是比较高的,不能让这个操作执行太频繁.(因此上述配置中,save 60 10000 就表示两次生成 rdb 之间的间隔最少必须要 60s 内进行了 10000 次修改).
2.1.2、bgsave 命令处理流程
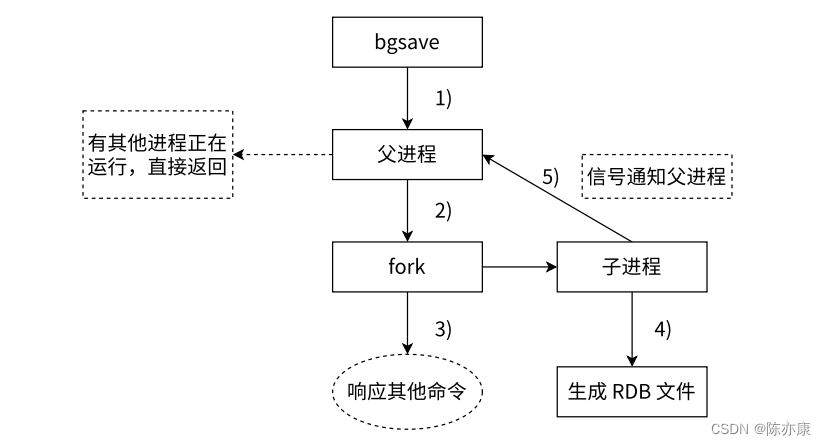
bgsave 操作流程是通过 fork 创建子进程,让子进程来完成持久化操作~ 持久化就会把要生成的快照数据先保存到一个临时文件中,当这个快照生成完后,再删除之前的 rdb 文件,把新生成临时 rdb 文件名字改成刚才的删除的 rdb 文件的名字,然后使用新的文件替换旧的文件(rdb 对于 fork 之后的新数据,就置之不理了,这里要对比着 aof 来看).
Ps:如果使用 save 命令,是不会触发 子进程 & 文件替换 逻辑,他会直接再当前进程中,往刚才同一个文件中写入数据.
2.1.3、RDB 文件的处理
通过 rdb 机制会在 redis 工作目录下,把内存中的数据,以压缩的形式(需要消耗一定的 cpu 资源,但是能节省存储空间),保存到一个二进制文件中,后续 redis 服务器重启,就会尝试去加载这个 rdb 文件,如果发现格式错误,就会加载失败(这个文件咱不去动他,也有可能会因为网络传输文件,遭到破坏)。
Ps:redis 也因此提供了 rdb 文件的检查工具——redis-check-rdb
2.1.4、演示效果
1)手动执行 bgsave
这里我们打开 redis 客户端,插入新的 key,手动执行 bgsave.
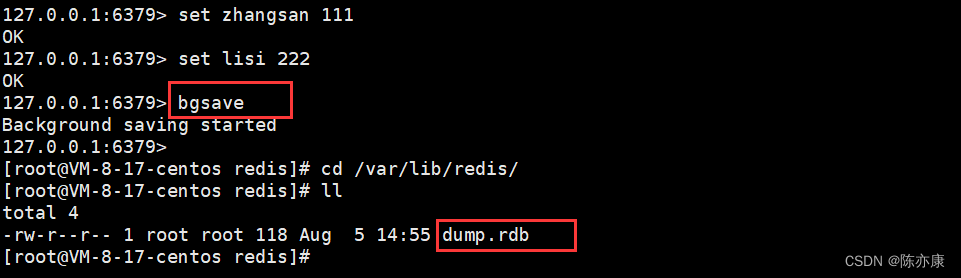
这里数据比较少,bgsave 瞬间就执行完了,立即查看 dump.rdb 文件就有结果,以后数据量多了,执行 bgsave 就要消耗一定的时间,立即查看不一定就是生成完毕.
接着就可以在 dump.rdb 快照中查看二进制数据

之后,使用 service redis-server restart 命令(一定要有符号链接)重启 redis 服务器,就可以看到 redis 服务器在重启的时候加载了rdb 文件的内容,恢复了之前的状态.
2)自动执行 bgsave
如果通过正常流程重新启动或者关闭 redis 服务器,此时 redis 服务器就会在退出的时候,自动触发 rdb 操作!但是如果异常重启(kill -9 或者 服务器断点),此时 redis 服务器来不及生成 rdb,造成数据丢失.
Ps:redis 生成快照也可以有多种方式
1)到达配置文件中 save 执行条件
2)通过 shutdown 命令(redis 里的一个命令)关闭 redis 服务器,也会触发.
3)redis 进行主从赋值的时候,主节点也会自动生成 rdb 快照,然后把 rdb 快照文件内容传输给从节点(后面细说).
在配置文件中的 save 修改以后,一定要重启服务器,才能生效!
如果想要立即生效,也可以通过命令的方式进行修改~
3)观察 bgsave 执行文件替换效果
bgsave 创建子进程完成持久化操作会把数据写到新文件中,然后替换掉旧文件,这个过程是可以观察到的——使用 linux 的 stat 命令,查看文件 inode 编号.
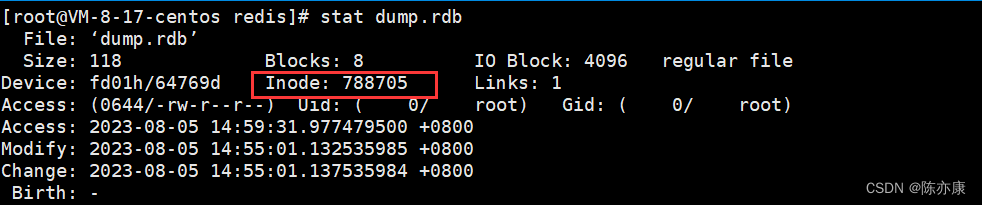
执行 bgsave 后:
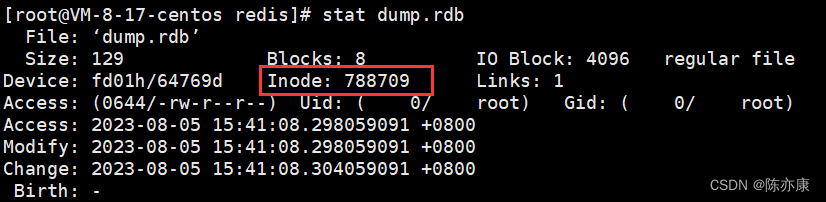
Linux 文件系统:
文件系统经典的组织方式,主要是把整个文件系统分成了三个大的部分
1.超级块:存放一些管理信息.
2.inode 区:存放 inode 结点,每个文件都会分配一个 inode 数据结构,包含了文件的各种元数据.
3.block 区:存放文件的数据内容.
4)实操问题:如果把 rdb 文件故意改坏了,会咋样?
ms:有实操过么?遇到什么问题吗?
Ps:手动把 rdb 文件内容改坏,前提是一定要通过 kill 进程的方式,然后启动 redis 服务器,如果通过 service redis-server restart 重启,就会在 redis 服务器退出的时候,重新生成 rdb 快照,就把刚刚改坏的文件替换掉了~
当我们把 rdb 文件内容改坏了,有可能服务器并没有受到什么影响,能正常启动,还能获取到一些 key,但是这里具体 redis 会咋样,取决于 rdb 文件坏的地方在哪(rdb 文件是二进制的,因此损坏后,交给 redis 去使用结果是不可预期的,可能能启动,但数据有问题,也有可能 redis 服务器直接启动失败)~
如果是文件末尾改坏了,对前面的内容没有啥影响,但如果是中间位置,可就不一定了,可能服务器就无法正常启动了~
当然 redis 也提供了 rdb 文件的检查工具,可以通过检查工具检查 rdb 文件格式是否符合要求,运行的时候,加入 rdb 文件作为命令行参数,此时就是以检查工具的方式来运行,不会真的启动 redis.
2.1.5、RDB 的优缺点
- RDB 是⼀个紧凑压缩的⼆进制⽂件,代表 Redis 在某个时间点上的数据快照。⾮常适⽤于备份,全量复制等场景。⽐如每 6 ⼩时执⾏ bgsave 备份,并把RDB⽂件复制到远程机器或者⽂件系统中
- Redis 加载 RDB 恢复数据远远快于AOF 的⽅式。
- RDB ⽅式数据没办法做到实时持久化 / 秒级持久化。因为 bgsave 每次运⾏都要执⾏ fork 创建⼦进程,属于重量级操作,频繁执⾏成本过⾼。
- RDB ⽂件使⽤特定⼆进制格式保存,Redis 版本演进过程中有多个 RDB 版本,兼容性可能有⻛险。
RDB 最大的问题,就是不能实时的持久化保存数据,在两次生成快照之间,实时的数据可能会随着异常重启而丢失.
2.2、AOF(append only file)
AOF(Append Only File)持久化:以文本文件的方式记录每次 redis 操作的命令,通过一些特殊的符号作为分隔符,来最命令做区分(具体规则,不用研究),重启时再重新执⾏ AOF ⽂件中的命令达到恢复数据的目的.
2.2.1、开启 aof 功能
aof默认是关闭状态的,通过修改配置文件,来开启 aof 功能~
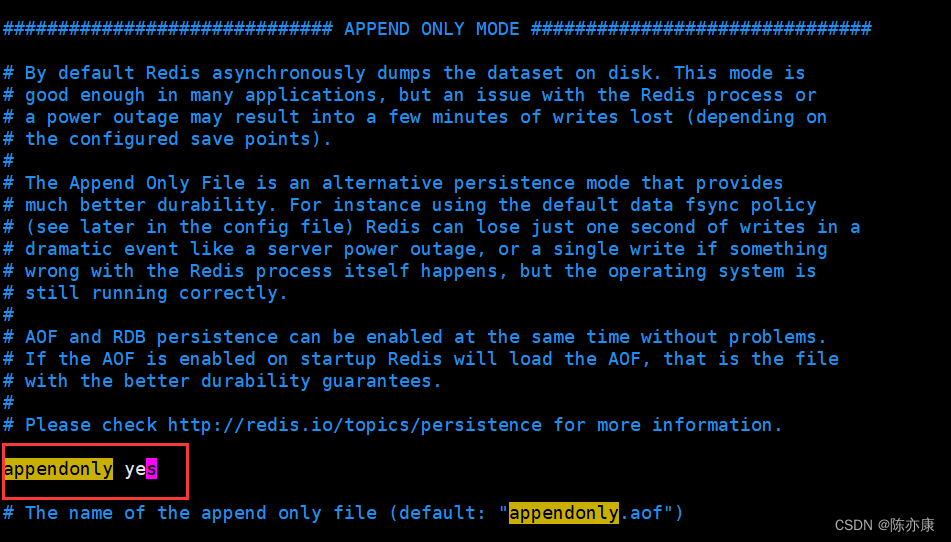
Ps:开启 aof 的时候,rdb 就不生效了,启动时不再读取 rdb 内容.
2.2.2、刷新缓冲区策略
引入 AOF 后,又要写内存又要写硬盘,还能和之前一样快了吗?
实际上,是没有影响的!!!原因如下
1.AOF 机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累到一定数量的时候,再统一写入硬盘。
Ps:这里的缓冲区大大降低了写硬盘的次数~ 就好比我有 100 个请求,本来是分 100 次 一个一个写入,而现在只需要一次就可以把 100 个请求写入硬盘.
2. AOF 每次是把新的操作命令顺序写入原有文件的末尾,输入顺序写入,这样的方式相比于随机访问的速度要快很多的.
值得注意的是,写入缓冲区里,本质还是再内存中,如果这个时候主机断电,进程挂了,缓冲区的数据就丢失了~ 这里类似于 mysql 事务的隔离级别,要有一定的取舍~
redis 给出了一些选项,让我们可以根据实际情况来决定怎么取舍——缓冲区刷新策略:
刷新频率越高,数据的可靠性就越高,但是性能影响就越大。
刷新频率越低,数据的可靠性就越低,但是性能影响就越小。
1. always 每操作一次就保存一次:频率是最高的,数据可靠性最高,性能最低.
2. everysec 每秒保存一次:频率低一些,数据可靠性降低,性能会提高.
3. no 跟随系统的同步策略:频率最低,数据可靠性最低,性能是最高的.
2.2.3、重写机制(rewrite)
AOF 文件持续增长,体积越来越大,影响到 redis 下次启动的启动时间,这怎么办呢?
实际上, aof 中的文件,有一些内容是冗余的,比如如下操作

因此 redis 就存在一个机制,能针对 aof 文件进行 整理 操作,剔除其中的冗余操作,合并一些操作,达到给 aof 文件瘦身的效果.
他就是——重写机制,这个机制就类似于大学学分制度:
这次你挂科了,学分扣一些~
这次你参加公益活动了,学分加一些~
....
随着时间推移,教务系统上会记录很多东西,不方便了,就对上述内容进行一个统计,算出一个总分,再继续记录.
2.2.4、AOF 重写流程
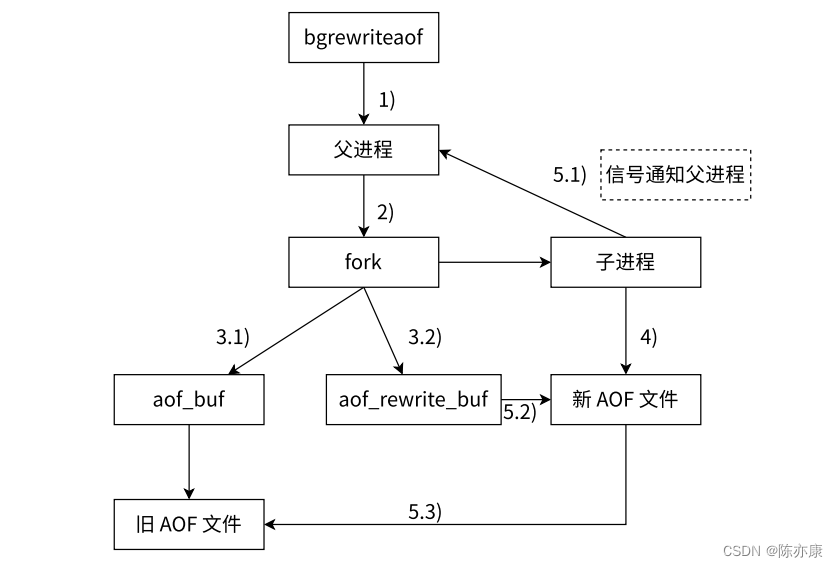
2、4)发生重写时,会通过 fork 创建子进程,创建的一瞬间,子进程就继承了当前父进程的内存状态,子进程只需要把内存中当前的数据(内存这里的数据已经是整理之后的模样了),获取出来,以文本格式写入到一个新的 aof 文件中.
1、2、3.1)此时父进程仍然负责接收新的请求,把这些请求产生的 aof 数据先写入到缓冲区,再刷新到旧的 aof 文件里。
2、3.2)上述操作之后,子进程里的内存数据是父进程 fork 之前的状态,fork 之后新来的请求,对内存的修改,子进程是不知道的,因此父进程这里又准备了一个 aof_rewrite_buf 缓冲区,专门存放 fork 之后接收到的数据(这里 rdb 对于 fork 之后的新数据,就置之不理了).
5.1、5.2)子进程这边,把 aof 数据写完之后,会通过 信号 通知以下父进程,父进程再把 aof_rewrite_buf 缓冲区中的内容也写入到新的 AOF 文件中.
5.3)最后就可以使用新的 aof 替换旧的 aof 文件了~
有几个特殊情况,如下:
1.如果执行 bgrewriteaof 的时候,当前 redis 已经正在进行 aof 重写了,会怎么样?
此时,不会再执行 aof 重写,直接返回.
2.如果执行 bgrewriteaof 的时候,发现当前 redis 在生成 rdb 文件的快照,会怎么样呢?
此时,aof 重写操作就会等待,等到 rdb 快照完毕之后,在进行 aof 重写.
Ps:现在的系统中,系统的资源一般都是比较充裕的, aof 的开销也不算事,因此一般来说, aof 的使用场景要多一些~
想到一个问题:子进程写完新的 aof 文件,最后要替代掉父进程继续在写的这个旧 aof 文件,那这个即将消失的 aof 文件还有什么意义?
这是一个好问题,我们可以去考虑一些极端的情况,假设在重写的过程中,重写了一半,服务器挂了,子进程内存的数据就会丢失,新的 aof 文件内容还不完整,所以如果父进程不坚持写旧的 aof 文件,重启旧没法保证数据的完整性了.
2.3、混合持久化
aof 按照文本的方式写入文件,但是文本写入成本是比较高的,redis 就引入了 “混合持久化” 的方式,结合了 rdb 和 aof 的特点~
在开启混合持久化的情况下, aof 重写时会把 redis 的持久化数据,以 RDB 的格式写入到新的 AOF 文件的开头,之后的数据再以 AOF 的格式化追加的文件的末尾,这样做,既可以避免因 aof 文件较大影响 redis 启动速度,又能防止 rdb 导致的一段时间内的数据丢失.
在配置文件中,上图中的这个选项为 yes 表示开启混合持久化(修改配置项后,记得重启服务器).
Ps:当 redis 同时存在 aof 文件和 rdb 快照的时候,以 aof 为主,rdb 就直接被忽略了~