📫作者简介:小明java问道之路,专注于研究 Java/ Liunx内核/ C++及汇编/计算机底层原理/源码,就职于大型金融公司后端高级工程师,擅长交易领域的高安全/可用/并发/性能的架构设计与演进、系统优化与稳定性建设。
📫 热衷分享,喜欢原创~ 关注我会给你带来一些不一样的认知和成长。
🏆 CSDN博客专家/后端领域优质创作者/内容合伙人、InfoQ签约作者、阿里云专家/签约博主、51CTO专家 🏆
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
专栏系列(点击解锁)
学习路线(点击解锁)
知识定位
🔥MySQL从入门到精通🔥
MySQL从入门到精通
全面讲解MySQL知识与实战
🔥计算机底层原理🔥
深入理解计算机系统CSAPP
构件计算机体系和计算机思维
Linux内核源码解析
围绕Linux内核讲解计算机底层原理与并发
🔥数据结构与企业题库精讲🔥
数据结构与企业题库精讲
结合工作经验深入浅出,适合各层次,笔试面试算法题精讲
🔥互联网架构分析与实战🔥
企业系统架构分析实践与落地
行业前沿视角,专注于技术架构升级路线、架构实践
互联网企业防资损实践
金融公司的防资损方法论、代码与实践。
本文目录
本文导读
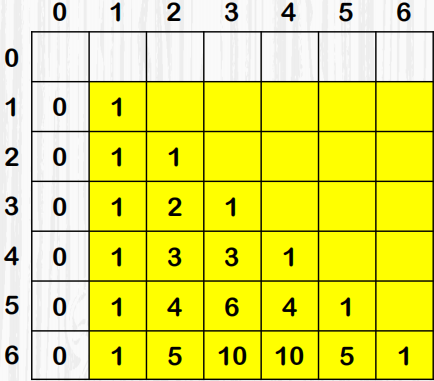
一、什么是跳表
1、跳表的原理
2、跳表的特点
3、跳表在Redis中的使用
二、Redis的跳表实现原理
三、跳表在Redis中的应用
总结
本文导读
本文介绍Redis跳表与实现源码解析,包括什么是跳表,跳表的数据结构原理、特点,到Redis源码中的跳表实现。
一、什么是跳表
1、跳表的原理
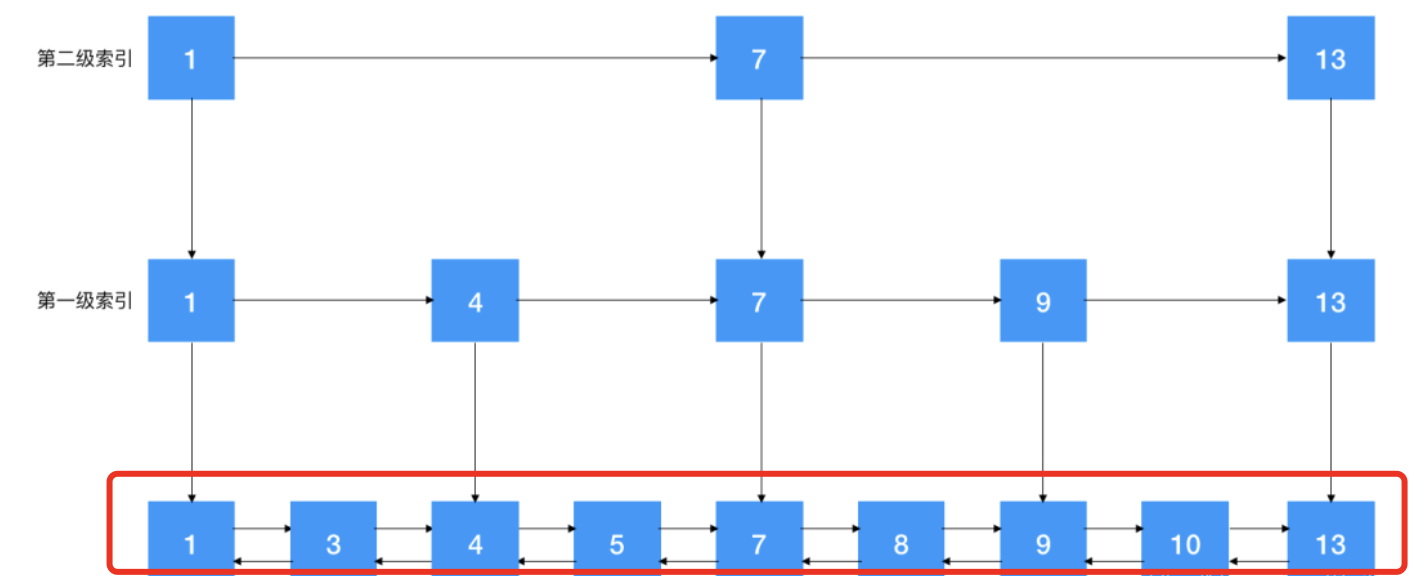
跳表(skiplist)是一种有序的数据结构,它可以通过维护指向每个节点中其他节点的多个指针来快速访问节点。简单来说,跳表是通过向双向链接列添加多个索引而形成的。
与双向链接列表相比,它支持快速搜索、更新和删除,因此适用于需求灵活的场景。
对于双向链表,即使存储在链接列表中的数据是有序的,如果我们想在其中找到某个数据,它也只能从头到尾遍历链接列表,反之亦然。这样搜索效率将非常低,时间复杂度将非常高,达到O(n)。

跳表在搜索某个数据时,首先在索引中找到一个较大的范围,然后再放到原始链接列表中进行精确搜索。因为在添加一层索引后,搜索节点的次数减少了,因此搜索效率大大提高,是典型的空间换时间。
当链表长度相对较大时,索引构建效率将显著提高。第一级链表不是单向链表,而是有序的双向链表。为了以相反的顺序获得范围中的元素。
2、跳表的特点
1、跳表结合了链表和类似的二分搜索思想;
2、结构有很多层,由原始链接列表和一些通过“跳转”生成的链表组成;
3、每一层都是一个有序的链表,最低级别(级别1)的链接列表包含所有元素。“跳跃”越高,元素(索引)越少;上链表是下链表的子序列;
4、搜索时,搜索顺序从上到下缩小;
5、每个节点包含两个指针,一个指向同一链接列表中的下一个元素,另一个指向下一级别的元素。
3、跳表在Redis中的使用
Redis使用跳表作为有序集合 zset 的底层实现之一。如果有序集合包含大量元素,或者如果有序集合中元素的成员是相对较长的字符串,Redis将使用跳表作为有序集合的底层实现。
二、Redis的跳表实现原理
Redis的跳表由两个结构定义:zskiplistNode和zskiplist。
zskiplistNode结构用于表示跳表节点
zskiplist结构用于存储关于跳表节点的信息,例如节点数量,以及指向页眉节点和页脚节点的指针。

上图绿色部分就是的是 zskiplist 结构
Header:指向跳表的头节点。通过该指针程序定位头节点的时间复杂度为O(1);
Tail:指向跳表的尾部节点。通过该指针程序定位尾部节点的时间复杂度为O(1);
Level:记录当前跳表中级别最大的节点的级别(不包括表头节点的级别);使用该属性,可以获得时间复杂度为O(1)内具有最高层高度的节点的层数
Length:记录跳表的长度,即当前包含在跳表中的节点数(不包括头节点)。使用此属性,程序可以在O(1)时间复杂度内返回跳表的长度。
typedef struct zskiplistNode {
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
// 后退指针
struct zskiplistNode *backward;
// 分值
double score;
// 成员对象
robj *obj;
} zskiplistNode;zskiplistNode 结构 包含以下属性:
Level:节点的每一层都标记有L1、L2、L3等。L1表示第一层,L2表示第二层,依此类推。每一层有两个属性:前向指针和跨度。前向指针用于访问表末尾的其他节点。跨度记录前向指针指向的节点与当前节点之间的距离(跨度越大,距离越远)。在上图中,行上带有数字的箭头表示向前指针,该数字表示跨度。当程序从页眉遍历到页脚时,访问将跟随层的前向指针。
Backward:标记为BW的节点的向后指针,指向当前节点的前一个节点。当程序从页脚遍历到页眉时,使用返回指针
Score:每个节点的1、2、3是该节点保存的得分,节点根据其保存的分数从小到大排列。
Obj:每个节点中的 obj 是节点保存的成员对象。
typedef struct zskiplist {
// header和tail指针分别指向跳表的表头和表尾节点
// 程序定位表头节点和表尾节点的复杂度为O(1)。
structz skiplistNode *header, *tail;
// length属性来记录节点的数量,O(1)复杂度内返回跳表的长度。
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist;三、跳表在Redis中的应用
Redis使用跳表作为 zset 的底层实现之一,跳表在Redis中的唯一作用也就是对该数据类型的实现。
如果有序集合包含大量元素,或者如果有序集合中元素的成员是相对较长的字符串,Redis将使用跳表作为有序集合键的底层实现。
原因是跳表向链接列表添加了多级索引,以提高搜索效率。然而,它是一种空间到时间的方案,这将不可避免地带来一个问题——索引占用内存。
Redis读取内存中的数据,不涉及IO。由于读取内存中的数据所花费的时间是从磁盘IO读取数据所花费时间的百万分之一,因此它使用了一个跳表,并使用了空间换时间,这一点易于实现,可以提高查询效率。
原始链接列表可能存储大型对象,而索引节点只需要存储键值和几个指针,不需要存储对象。因此,当节点本身较大或元素数量较大时,其优点将不可避免地被放大,而其缺点可以被忽略。
总结
本文介绍Redis跳表与实现源码解析,包括什么是跳表,跳表的数据结构原理、特点,到Redis源码中的跳表实现。