注:本文是对 https://www.bilibili.com/video/BV1CU4y1N7Sh 的实践。
关于如何搭建Hadoop集群,请参考我另一篇文档。
环境
- CentOS 7.7
- JDK 8
- Hadoop 3.3.0
- Hive 3.1.2
准备
确认Hadoop的 etc/hadoop/core-site.xml 文件包含如下配置:
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
确认Hadoop集群运行良好。
安装MySQL
只需在node1上安装。步骤如下:
查询并卸载Centos7自带的mariadb:
[root@node1 ~]# rpm -qa|grep mariadb
mariadb-libs-5.5.64-1.el7.x86_64
[root@node1 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
[root@node1 ~]#
再次查询,确认已卸载。
把MySQL的压缩包 mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 放到 /export/software/mysql 目录下,并解压:
tar -xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar
安装 libaio :
yum -y install libaio
安装MySQL:
rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm
初始化MySQL:
mysqld --initialize
更改属性:
chown mysql:mysql /var/lib/mysql -R
启动MySQL:
systemctl start mysqld.service
查看密码:
cat /var/log/mysqld.log
在结果中查找如下内容:
2022-12-12T06:21:57.689895Z 1 [Note] A temporary password is generated for root@localhost: d&O_ayymf5eA
本例中,密码为 d&O_ayymf5eA 。
登录MySQL:
mysql -u root -p
输入刚才的密码,进入MySQL命令行。
更改密码为 hadoop :
alter user user() identified by "hadoop";
授权远程访问:
use mysql;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
FLUSH PRIVILEGES;
退出MySQL命令行:
exit;
注:启动/停止/查看mysqld状态:
systemctl stop mysqld
systemctl status mysqld
systemctl start mysqld
设置开机自启动:
systemctl enable mysqld
查看设置开机自启动是否成功:
[root@node1 mysql]# systemctl list-unit-files | grep mysqld
mysqld.service enabled
mysqld@.service disabled
部署
把Hive的压缩包放到node1的 /export/server 目录并解压:
tar -zxvf apache-hive-3.1.2-bin.tar.gz
解决Hive与Hadoop之间guava版本差异:
cd /export/server/apache-hive-3.1.2-bin/
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
把 apache-hive-3.1.2-bin/conf 目录下的 hive-env.sh.template 文件改名为 hive-env.sh ,并修改该文件,添加如下内容:
export HADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib
在同一目录下新建 hive-site.xml 文件,内容如下:
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
把MySQL的JDBC驱动 mysql-connector-java-5.1.32.jar 放到Hive的 lib 目录下。
初始化元数据:
bin/schematool -initSchema -dbType mysql -verbos
注:如果前一步里没有更新 guava-19.0.jar 为 guava-27.0-jre.jar ,则这里会报一个 NoSuchMethodError 的错误,如下:
[root@node1 apache-hive-3.1.2-bin]# bin/schematool -initSchema -dbType mysql -verbos
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1380)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1361)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:448)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
初始化成功后,MySQL里会生成 hive3 数据库,其中有74张表:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive3 |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use hive3;
mysql> show tables;
+-------------------------------+
| Tables_in_hive3 |
+-------------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
......
| WM_TRIGGER |
| WRITE_SET |
+-------------------------------+
74 rows in set (0.00 sec)
在HDFS创建Hive的存储目录:
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
注:这一步我没做。后来看了一下, /tmp 是已有的。 /user/hive/warehouse 会在创建第一个DB的时候自动创建。
启动metastore服务:
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
注:如果想要设置log为debug级别,则加上 --hiveconf hive.root.logger=DEBUG,console 。
启动hiveserver2服务:
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
注:启动metastore服务后,等一会儿再启动hiveserver2服务。
两个服务都启动后,可以通过 jps 查看Java进程:
[root@node1 apache-hive-3.1.2-bin]# jps
128897 RunJar
129121 Jps
91060 DataNode
126459 RunJar
92090 ResourceManager
92284 NodeManager
90863 NameNode
可见,多了两个 RunJar 进程。之后可随时检查,确保这两个进程还在工作。
以上操作都是在node1上进行的。
Hive可以直接通过命令行连接metastore,但是不推荐这么做,官方推荐做法是通过 beeline 客户端连接hiveserver2,后者再连接到metastore。
虽然Hive是部署在node1上的,但是通过 beeline 客户端,也可以在其它机器上连接。比如,我们把node1上的Hive目录复制到node3上(主要是为了复制 beeline 客户端)。
scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/
然后在node3上,通过 beeline 客户端来连接node1上的Hive:
/export/server/apache-hive-3.1.2-bin/bin/beeline
命令行提示符如下:
beeline>
在命令行通过以下命令,连接到node1的Hive上:
! connect jdbc:hive2://node1:10000
输入用户名 root ,密码为空(直接回车):
命令行提示符如下:
0: jdbc:hive2://node1:10000>
现在,就可以运行各种数据库命令了,比如:
show databases;
use <DB name>;
show tables;
当然,也可以用第三方工具来连接Hive数据库,比如 DataGrid 、 Dbeaver 、 SQuirrel SQL Client 等,和连接MySQL、Db2等数据库类似,不再赘述。
Hive数据库操作
创建数据库和表
创建数据库:
create database test1212;
注:其对应的HDFS目录为 /user/hive/warehouse/test1212.db ,如果之前没有手工创建 /user/hive/warehouse 目录,此时就会自动创建。
使用该数据库:
use test1212;
创建表:
create table t1(name string, sex string, age int) row format delimited fields terminated by "\t";
注:其对应的HDFS目录为 /user/hive/warehouse/test1212.db/t1 。
注意,本例中指定使用 \t (制表符)作为字段之间的分隔符。如果没有指定分隔符,则默认使用 \001 字符。
查询表:
select * from t1;
......
+----------+---------+---------+
| t1.name | t1.sex | t1.age |
+----------+---------+---------+
+----------+---------+---------+
No rows selected (1.663 seconds)
此时表为空。
向表中导入数据
方法1:直接通过HDFS传文件
例如,文本文件 t1.txt 内容如下:
zhangsan male 20
lisi female 19
wangwu male 33
注意,各个字段之间是用 \t 分隔的。
把该文件传到HDFS中表 t1 对应的目录下,即 /user/hive/warehouse/test1212.db/t1 :
hadoop fs -put /export/data/t1.txt /user/hive/warehouse/test1212.db/t1/
如下图:
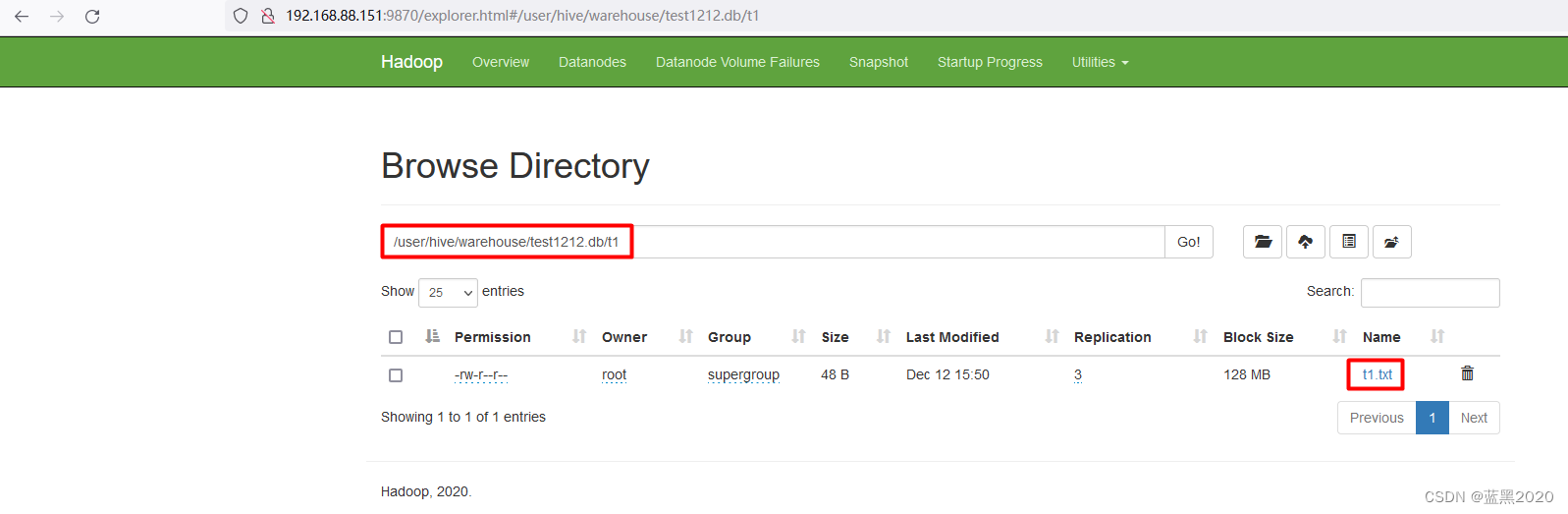
查询表 t1 :
select * from t1;
......
+-----------+---------+---------+
| t1.name | t1.sex | t1.age |
+-----------+---------+---------+
| zhangsan | male | 20 |
| lisi | female | 19 |
| wangwu | male | 33 |
+-----------+---------+---------+
3 rows selected (1.007 seconds)
可见,表和文件已经关联了。
注:该方法比较暴力,一般不推荐直接这么做。
方法2:通过LOAD命令传文件
LOAD 命令的语法为:
LOAD DATA [LOCAL] INPATH '<path>' [OVERWRITE] INTO TABLE <tablename>;
需要注意的是 LOCAL 关键字。
指定LOCAL关键字
若指定 LOCAL 关键字,则是从hiveserver2服务器端的本地文件系统加载。比如:
创建表 t2 :
create table t2(name string, sex string, age int) row format delimited fields terminated by "\t";
通过LOAD命令,加载本地文件:
LOAD DATA LOCAL INPATH '/export/data/t1.txt' INTO TABLE t2;
查询表 t2 :
select * from t2;
......
+-----------+---------+---------+
| t2.name | t2.sex | t2.age |
+-----------+---------+---------+
| zhangsan | male | 20 |
| lisi | female | 19 |
| wangwu | male | 33 |
+-----------+---------+---------+
3 rows selected (0.218 seconds)
需要注意的是,我们是在node3的beeline客户端运行命令的,beeline客户端连接的是node1的hiveserver2服务,所以这里的 LOCAL 指定的是node1的本地文件系统。也就是说, /export/data/t1.txt 是node1的文件系统路径。
不指定LOCAL关键字
如果不指定 LOCAL ,则默认是从HDFS文件系统加载。比如:
创建表 t3 :
create table t3(name string, sex string, age int) row format delimited fields terminated by "\t";
上传文件到HDFS的根目录下:
hadoop fs -put /export/data/t1.txt /
此时,该文件在HDFS的路径为 /t1.txt 。
通过LOAD命令,加载HDFS文件:
LOAD DATA INPATH '/t1.txt' INTO TABLE t3;
查询表 t3 :
select * from t3;
......
+-----------+---------+---------+
| t3.name | t3.sex | t3.age |
+-----------+---------+---------+
| zhangsan | male | 20 |
| lisi | female | 19 |
| wangwu | male | 33 |
+-----------+---------+---------+
3 rows selected (0.203 seconds)
注意:加载HDFS文件是移动操作,原来的文件就没了。
方法3:插入数据
通过SQL语句,可以直接向表中插入数据,例如:
insert into t3 values ('zhaoliu', 'female', 22);
但是,这么做的成本很高,我试了一下,该操作花了246秒。
通过 http://192.168.88.151:8088 ,可以看到实际上底层是一个MapReduce的任务:
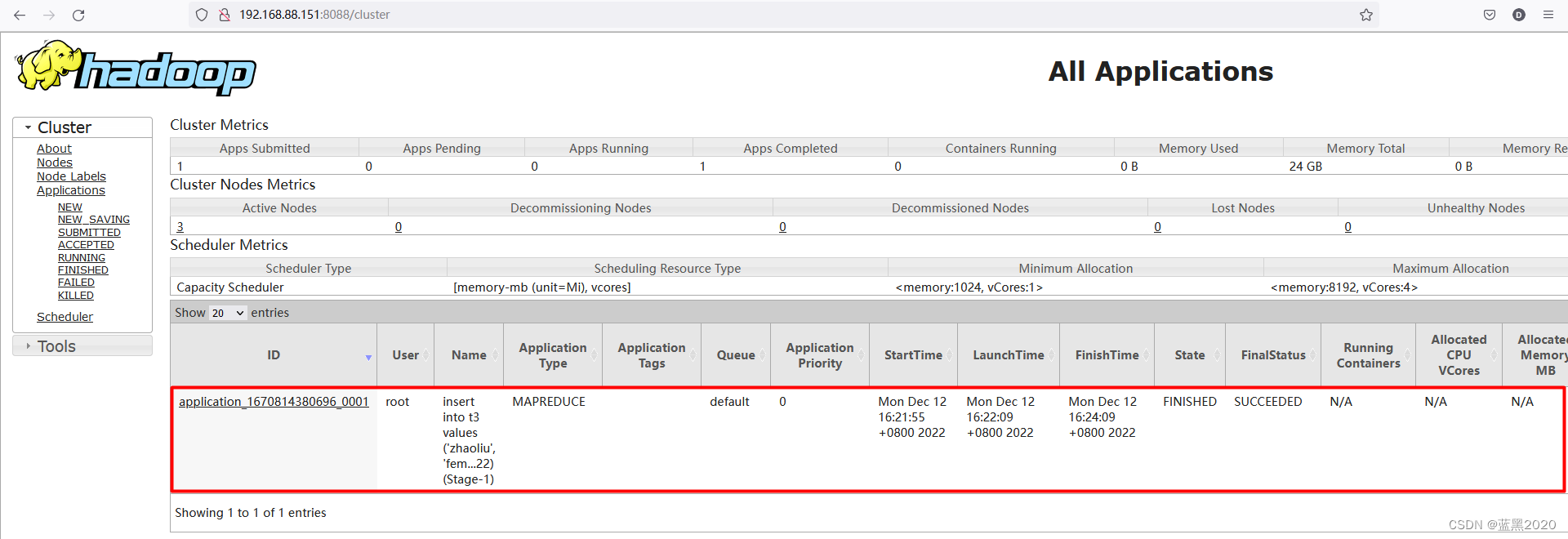
插入单条记录的成本非常高,因此更常见的操作是 insert into xxx select xxx from xxx where xxx 和 create table xxx as select xxx from xxx where xxx (即CTAS)。
查询数据
SELECT xxx FROM xxx WHERE xxx
其它像 distinct , group by , having , order by , limit 、 join 等关键字,也都一样,不再赘述。



![[激光原理与应用-50]:《激光焊接质量实时监测系统研究》-1-绪论 (模式识别)](https://img-blog.csdnimg.cn/img_convert/47e58687be93f68d6b3ffa267d0f1695.jpeg)

![[附源码]JAVA毕业设计疫情防控期间人员档案追演示录像下(系统+LW)](https://img-blog.csdnimg.cn/61044905b528425fbac7588531168695.png)