前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐

无聊的时候做了一个搜索文章的软件,有没有更加的方便快捷不知道,好玩就行了
环境使用
-
Python 3.8
-
Pycharm
模块使用
-
import requests
-
import tkinter as tk
-
from tkinter import ttk
-
import webbrowser
第三方模块安装方法:
win + R 输入cmd 输入安装命令 pip install 模块名
(如果你觉得安装速度比较慢, 你可以切换国内镜像源)

👇 👇 👇 更多精彩机密、教程,尽在下方,赶紧点击了解吧~
素材、视频教程、完整代码、插件安装教程我都准备好了,直接在文末名片自取就可
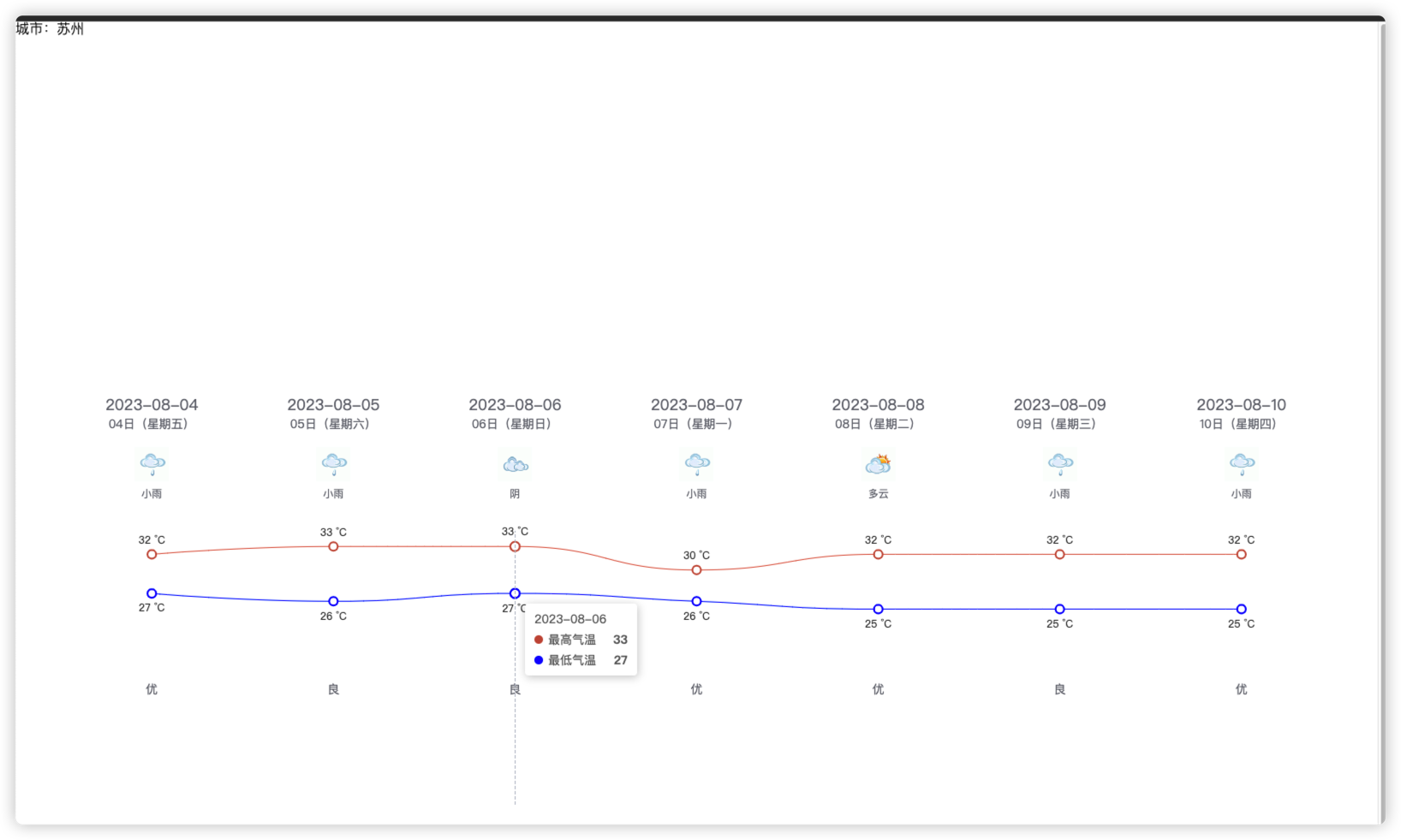
最终效果

界面实现代码
导入模块
import tkinter as tk
from tkinter import ttk
创建窗口
root = tk.Tk()
root.title('问题搜索')
root.geometry('900x700+100+100')
root.iconbitmap('search.ico')
root.mainloop()
标题图片
img = tk.PhotoImage(file='封面.png')
tk.Label(root, image=img).pack()
搜索框
search_frame = tk.Frame(root)
search_frame.pack(pady=10)
search_va = tk.StringVar()
tk.Label(search_frame, text='问题描述:', font=('黑体', 15)).pack(side=tk.LEFT, padx=5)
tk.Entry(search_frame, relief='flat', width=30, textvariable=search_va).pack(side=tk.LEFT, padx=5, fill='both')
tk.Button(search_frame, text='搜索一下', font=('黑体', 12), relief='flat', bg='#fe6b00').pack(side=tk.LEFT,padx=5)
内容显示界面
tree_view = ttk.Treeview(root, show="headings")
tree_view.column('num', width=1, anchor='center')
tree_view.column('title', width=150, anchor='w')
# 完整源码需要的+wx:qian97378免费领
tree_view.column('author', width=10, anchor='center')
tree_view.column('date', width=10, anchor='center')
tree_view.column('link', width=30, anchor='center')
tree_view.heading('num', text='序号')
tree_view.heading('title', text='标题')
tree_view.heading('author', text='作者')
tree_view.heading('date', text='发布时间')
tree_view.heading('link', text='链接')
tree_view.pack(fill=tk.BOTH, expand=True, pady=5)
内容效果代码
def search(word):
search_list = []
num = 0
for page in range(1, 4):
url = 'https://so.csdn.net/api/v3/search'
data = {
'q': word,
't': 'all',
'p': page,
's': '0',
'tm': '0',
'lv': '-1',
'ft': '0',
'l': '',
'u': '',
'ct': '-1',
'pnt': '-1',
'ry': '-1',
'ss': '-1',
'dct': '-1',
'vco': '-1',
'cc': '-1',
'sc': '-1',
'akt': '-1',
'art': '-1',
'ca': '-1',
'prs': '',
'pre': '',
'ecc': '-1',
'ebc': '-1',
'urw': '',
'ia': '1',
'dId': '',
'cl': '-1',
'scl': '-1',
'tcl': '-1',
'platform': 'pc',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
完整源码需要的+wx:qian97378免费领
for index in response.json()['result_vos']:
title = index["title"].replace('<em>', '').replace('</em>', '')
dit = {
'num': num,
'title': title,
'author': index['nickname'],
'date': index['create_time_str'],
'link': index['url'],
}
num += 1
search_list.append(dit)
return search_list
def show(search_list):
# 往树状图中插入数据
for index, stu in enumerate(search_list):
tree_view.insert('', index + 1,
values=(stu['num'], stu['title'], stu['author'], stu['date'], stu['link']))
def click():
key_word = search_va.get()
if key_word:
search_list = search(word=key_word)
# 往树状图中插入数据
show(search_list)
# 单击 获取当前点击行的值
def tree_view_click(event):
# 遍历选中的元素
for item in tree_view.selection():
# 获取选中元素的值
item_text = tree_view.item(item, "values")
# 打印选中元素的值
# print(item_text)
webbrowser.open(item_text[-1])
尾语
感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。