🔥🔥 欢迎来到小林的博客!!
🛰️博客主页:✈️林 子
🛰️博客专栏:✈️ 数据结构与算法
🛰️社区 :✈️ 进步学堂
🛰️欢迎关注:👍点赞🙌收藏✍️留言
这里写目录标题
- 堆的性质
- 堆的实现
- 堆的声明
- 普通构造和析构的实现
- 插入函数push
- 什么是向上调整????
- push函数代码
- 移除节点函数pop
- 什么是向下调整?
- pop代码
- top函数
- 引入仿函数
堆的性质
1.堆是一颗完全二叉树。
2.堆的每一个父节点都大于等于或小于等于它的子节点。
所有父节点都大于等于子节点的堆叫大堆。
所有父节点都小于等于子节点的堆叫小堆。
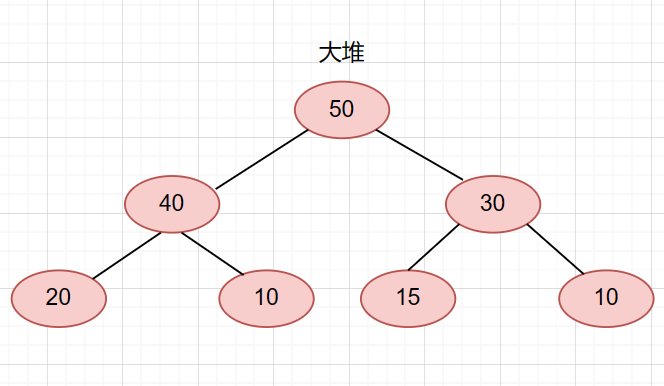
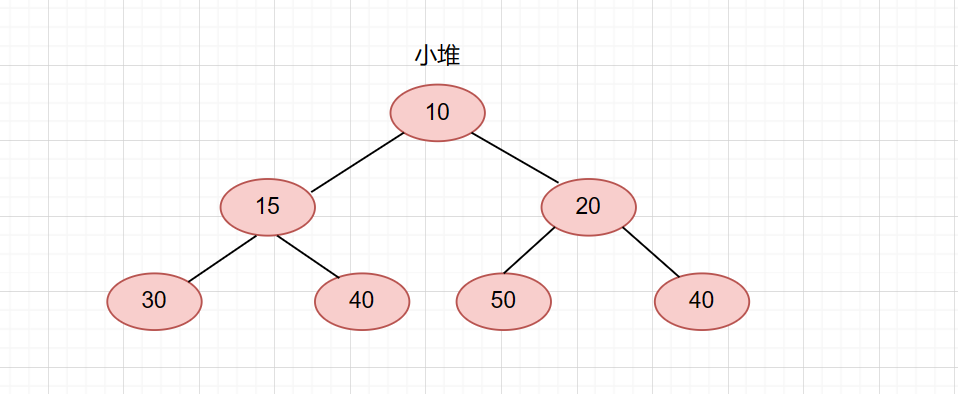
堆的实现
我们可以用链表或者数组的形式来实现堆。如果用链表来实现堆的话,那么我们需要定义一个二叉树节点的结构体。并至少要包括左孩子,右孩子,存储的值三个结构体成员。例如:
struct HeapNode
{
HeapNode* _left; //左孩子
HeapNode* _right; //右孩子
int _val; //存储的值
};
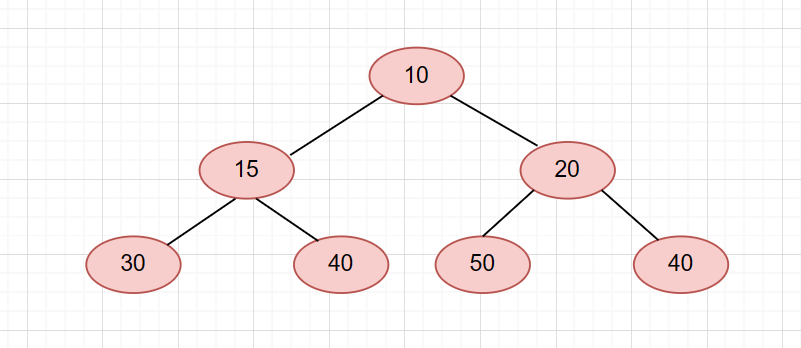
而这也意味着一个节点至少必须包含了三个成员,这对空间是一种消耗。那么我们可以用数组来实现堆。因为堆是一个完全二叉树。那么用数组实现就不会存在中间有空间浪费的情况,也可以用父节点的下标 * 2 + 1计算出左孩子的下标。也可以用(子节点 - 1 ) / 2 来计算出其父节点的下标。我们把下面这个堆抽象成一个数组。
template<class T,class Functor = Less<T>>
class Heap
{
public:
T* _hp;
size_t _size;
size_t _capacity;
用数组存储的话,那么它的逻辑图应该是这样的。
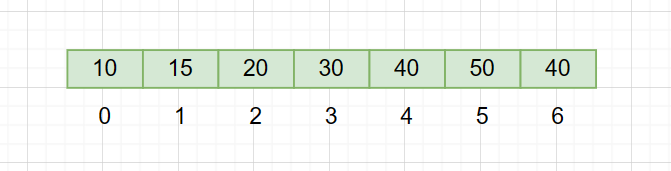
以20这个节点为例,它的下标是2,那么它的父节点所在的位置就是(2 - 1) / 2。也就是10的位置。它的左孩子则是2*2 + 1,也就是5这个位置。右节点则是 2 * 2 + 2。
我们理清楚了堆如何在数组中存储堆。那么我们就可以开始实现堆了。
堆的声明
我们创建一个堆的类。并引用模板,因为堆存储的值的类型是不确定的。而堆需要提供以下几个成员。
成员变量:
T* _hp : 指向堆内存(非此数据结构的堆)的一块空间,存储的是当前堆中的数据。
size_t _size : 记录堆的大小,也是下一次push时的下标位置
size_t _ capacity : 记录堆的容量,如果和_size相等,则说明需要扩容了
成员函数:
Heap(size_t capacity = 16); 构造函数,采用了缺省参数。也可以用户手动传入一个参数,指明堆的容量。
~Heap(); 析构函数,对当前对象动态资源的销毁
template<class T>
class Heap
{
private:
T* _hp;
size_t _size;
size_t _capacity;
public:
Heap(size_t capacity = 16);
~Heap();
}
普通构造和析构的实现
我们的构造函数只需要为_hp开辟空间,并初始化 _size 和 _capacity即可。析构函数直接释放 _hp即可。
构造函数
Heap(size_t capacity = 16):_capacity(capacity),_size(0){
_hp = new T[_capacity];
}
析构函数
~Heap() {
delete _hp;
_size = _capacity = 0;
}
插入函数push
那么我们要往堆中插入数据怎么办,我们可以写个push函数来为堆插入数据。 那么在写这个函数之前,我们要知道堆是如何push的。
堆的push过程:
1.把插入的值放入数组的末尾(也是堆的最后一个叶节点)
2.对这个节点进行向上调整
什么是向上调整????
就是让当前节点与它的父亲进行比较,我们拿大堆来说,如果父节点比当前节点小。那么就交换这两个节点,一直循环直到父节点比当前节点到或者当前节点已经是根节点时才结束。 举两个例子,我们有一个大堆。
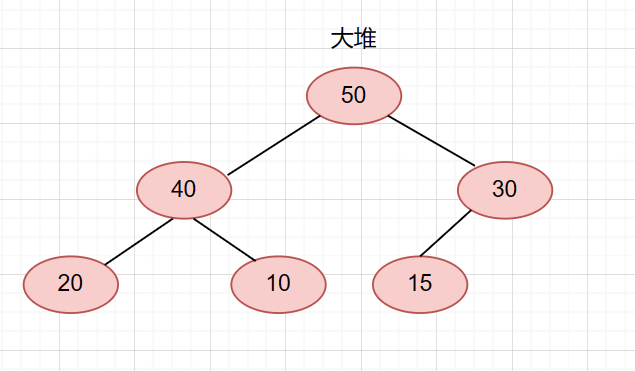
这时候我们要新增一个节点,35,那么我们先把它加在末尾。
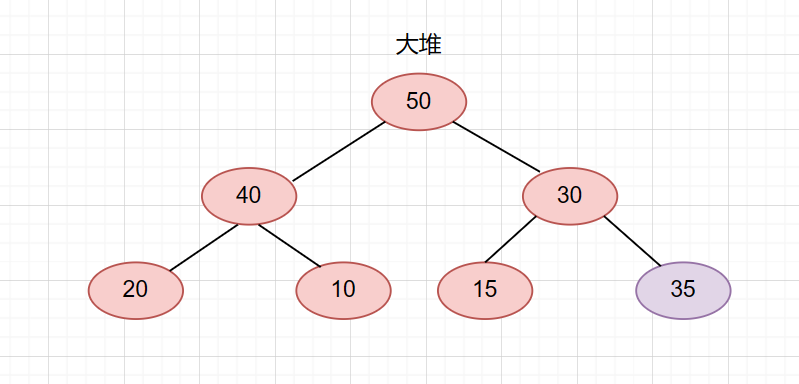
然后让当前节点与它的父节点比较大小。如果当前节点比父节点大,则交换位置(大堆的情况下)。
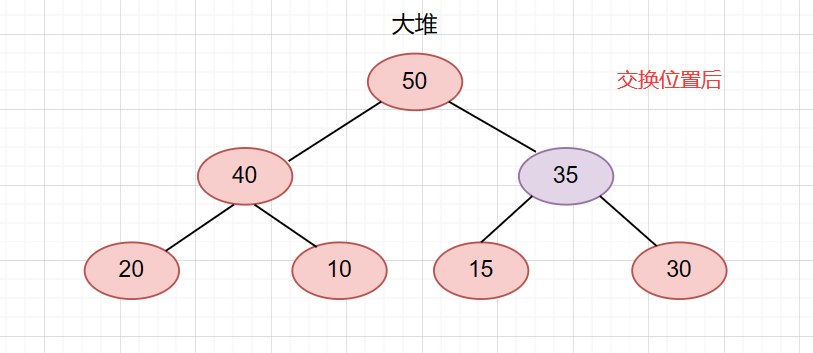
随后再让该节点和它的父亲比较,比它的父亲小,调整完毕。
第二个例子
依旧是刚刚那个堆,只不过我们把插入的数据换成了70
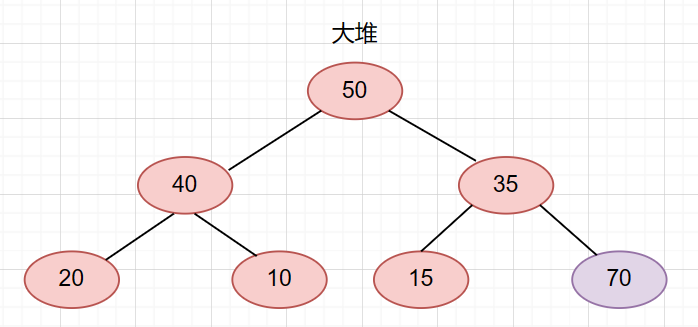
那么它会一直调整到根节点才结束。如图
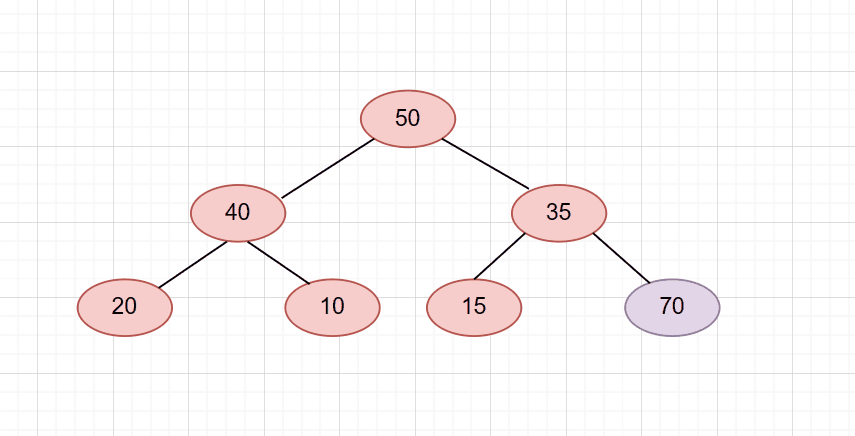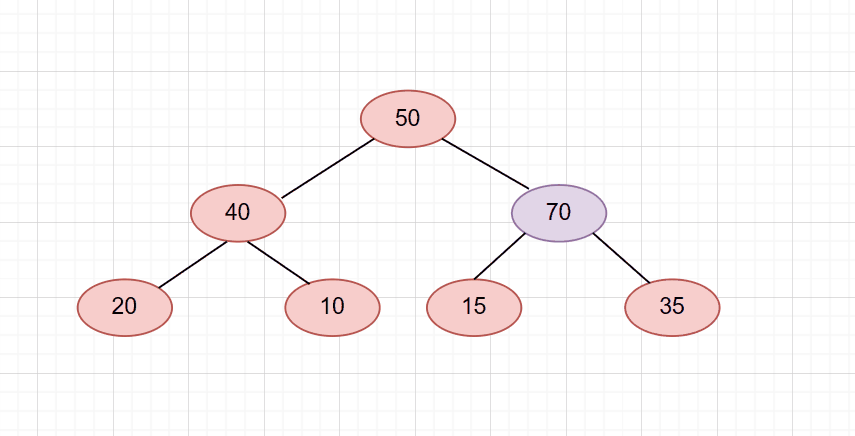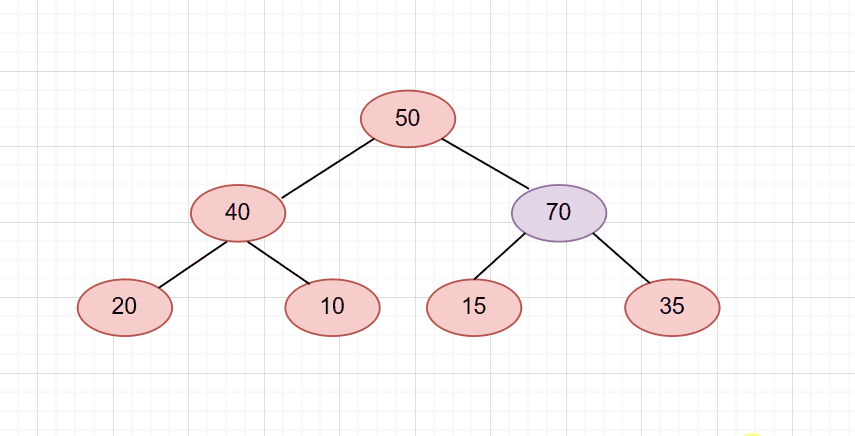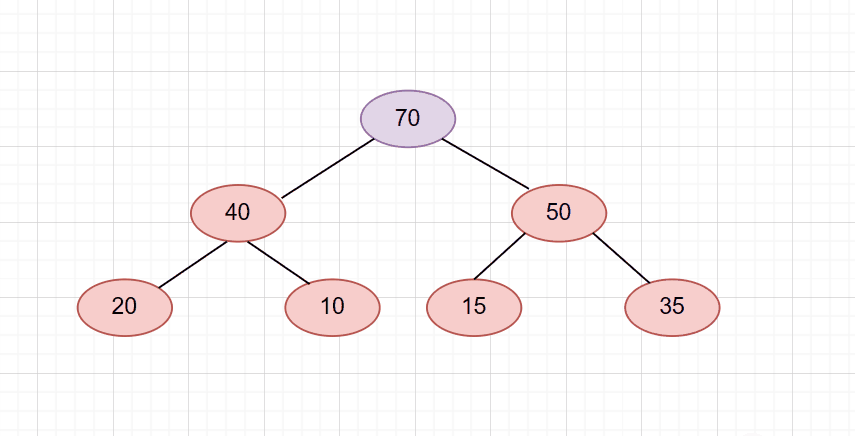
搞明白了向上调整的原理后。我们就可以写出push函数代码了!
push函数代码
void UpDateCapacity()
{
T* tmp = new T[_capacity * 1.5]; //开辟一个新的堆
assert(tmp); //断言,扩容失败则崩溃
memcpy(tmp, _hp, _size * sizeof(T)); //转移资源
delete _hp; //释放旧空间
std::swap(tmp, _hp); //交换两个地址
_capacity = _capacity * 1.5; //更新容量
}
//交换两个数的值
void swap(T& x, T& y)
{
T tmp = x;
x = y;
y = tmp;
}
void Up()
{
//从最后一个开始向上调整
int child = _size - 1;
int parent = (child - 1) / 2;
while (child) //child != 0
{
//大堆 , 孩子大于父亲则交换
if (_hp[child] > _hp[parent])
{
swap(_hp[child], _hp[parent]);
child = parent; //更新孩子
parent = (child - 1) / 2; //更新父节点
}
else break;
}
}
void push(const T& val)
{
if (_size == _capacity) //检查当前空间是否满了
{
//扩容
UpDateCapacity();
}
_hp[_size++] = val; //插入
Up(); //向上调整
}
移除节点函数pop
堆移除末尾节点是没有意义的,堆pop的都是根节点,也叫做堆顶。因为堆顶不是最大的,就是最小的。所以我们的pop函数就是移除堆顶中的元素。当然不能直接移除,如果直接移除会破坏堆的结构。所以我们时必须让堆顶与末尾节点交换。随后让堆顶向下调整即可。
pop的流程:
1.堆顶位置与末尾位置进行交换。
2.堆顶开始向下调整
什么是向下调整?
和向上调整差不多,向上调整是和父亲比较后决定是否交换。向下调整也是。如果是大堆的情况下,父亲与较大的那个孩子比较大小,如果比较大的孩子比父节点的值要大。那么则交换,小堆的情况则相反。
那么我们来演示一下。还是刚刚那个堆,不过我们要把70这个节点pop掉。
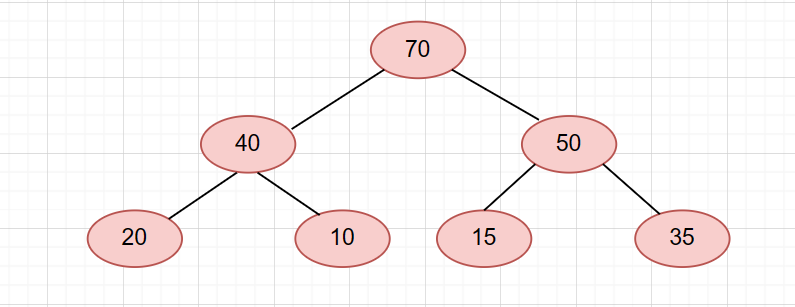
第一步,我们让堆顶与末尾交换。
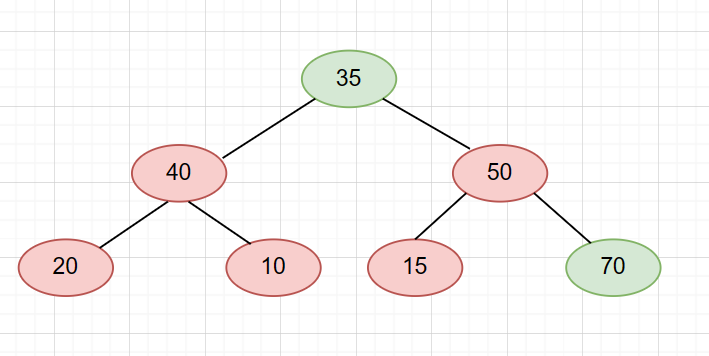
随后删掉末尾元素(很简单,就是_size–即可)。
然后我们要先让它的两个子节点进行比较,因为是大堆,所以取较大的那个,也就是50。再拿50和35进行比较,50大于35,则交换。
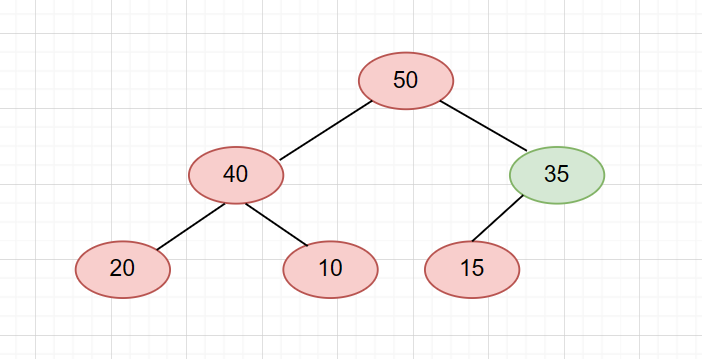
然后我们继续向下调整,可是此时它已经没有右孩子了。那么就直接和左孩子比较。比左孩子大,则结束。
整个流程图:
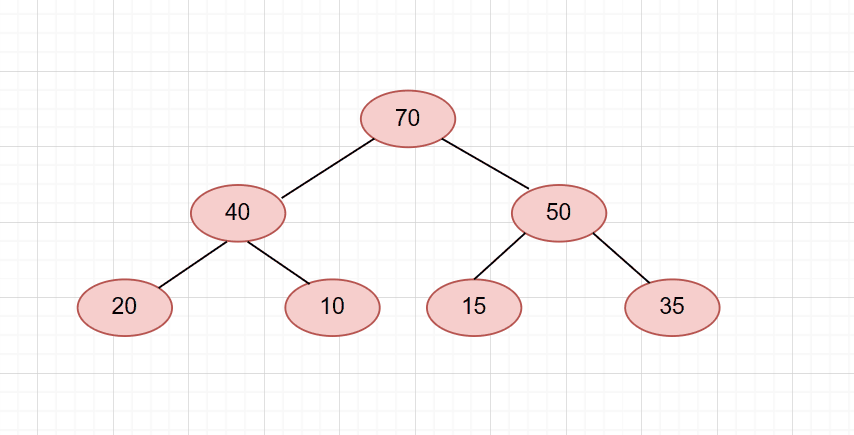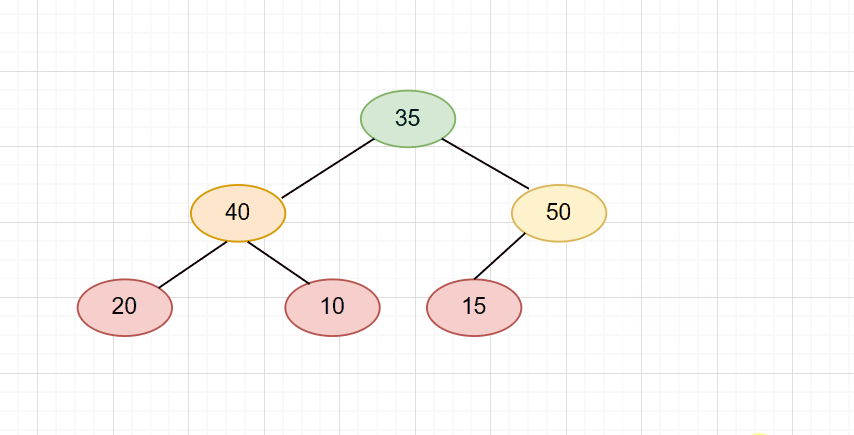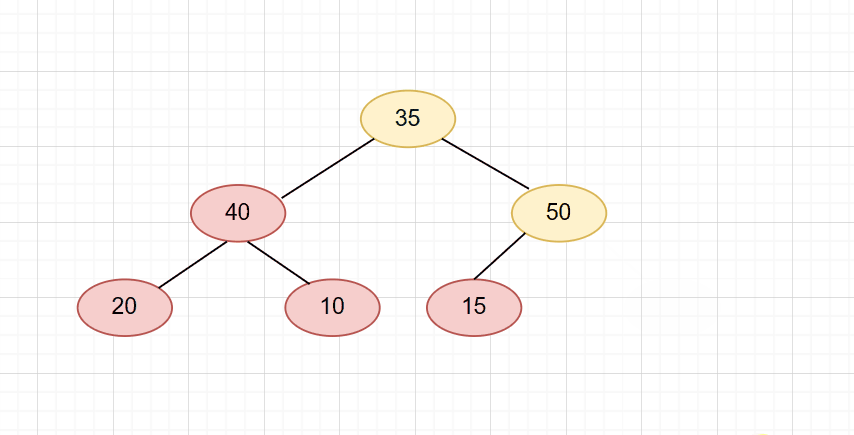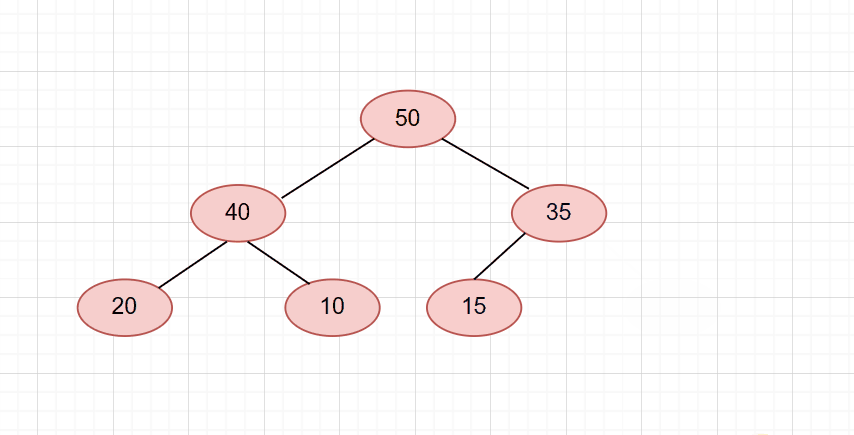
pop代码
原理弄明白之后,直接上代码。
void Down()
{
int parent = 0; //父节点
int child = parent * 2 + 1; // 左孩子节点
while (parent < _size) /
{
if (child + 1 >= _size - 1 && _hp[child + 1] > _hp[child])
child++; //如果右孩子存在且右孩子 > 左孩子,那么child变成右孩子
if (child >= _size - 1) break; //左孩子不存在
if (_hp[child] > _hp[parent]) //子节点>父节点
{
swap(_hp[parent], _hp[child]); //交换
parent = child; //更新
child = parent * 2 + 1;
}
else break;
}
}
void pop()
{
assert(_size > 0); //保证堆里有元素
//根节点和最后一个节点交换
swap(_hp[0], _hp[_size-- - 1]); //堆顶和末尾交换
Down(); //向下调整
}
top函数
top函数是获取堆顶元素的函数,我们可以在保证堆里有元素的情况下直接返回_hp的第0个元素即可。
T top()
{
assert(_size > 0);
return _hp[0];
}
引入仿函数
我们上面演示的是大堆的情况下,但是如果我们又想让它在不写多个类的情况下,既可以用大堆,也可以用小堆,那么该如何实现呢?这里我们可以在模板参数中引入仿函数。
首先我们要有2结构体/类,并重载它们的()操作符,传入两个参数用来比较,Greate类比较 >,Less类 比较小于
template<class T>
struct Greater
{
bool operator()(T& x, T& y)
{
return x > y;
}
};
template<class T>
struct Less
{
bool operator()(T& x, T& y)
{
return x < y;
}
};
然后我们在类模板声明处加上一个类型,并设置缺省。
template<class T,class Functor = Less<T>>
class Heap
{
.....
};
这样我们的类中就有一个Functor类型了,我们可以用这个类型创建一个对象,这个对象及你创建Heap对象时传入的模板参数。传入Less则创建Less对象,传入Greater则创建Greater对象。不传则用缺省的。
随后我们就可以修改向上和向下调整的代码了
void Up()
{
Functor func; //创建一个Functor对象
//从最后一个开始向上调整
int child = _size - 1;
int parent = (child - 1) / 2;
while (child) //child != 0
{
//大堆
if (func(child,parent)) //用Functor对象的()操作符重载返回的bool值来判断真或者假
{
swap(_hp[child], _hp[parent]);
child = parent;
parent = (child - 1) / 2;
}
else break;
}
}
void Down()
{
Functor func; //创建一个Functor对象
int parent = 0;
int child = parent * 2 + 1;
while (parent < _size)
{
//用Functor对象的()操作符重载返回的bool值来判断真或者假
if (child + 1 >= _size - 1 && func(_hp[child + 1],_hp[child]))
child++; //如果右孩子存在且右孩子 > 左孩子,那么child变成右孩子
if (child >= _size - 1) break; //左孩子不存在
if (func(_hp[child],_hp[parent])) //用Functor对象的()操作符重载返回的bool值来判断真或者假
{
swap(_hp[parent], _hp[child]);
parent = child;
child = parent * 2 + 1;
}
else break;
}
}
这样我们堆的基本功能也实现了,当然还有拷贝构造,赋值重载,移动构造…并没有完善。由于我们只是演示堆的实现,所以这些函数就不实现了,大家有兴趣的话也可以实现一下。以下是演示中的所有代码。
template<class T>
struct Greater
{
bool operator()(T& x, T& y)
{
return x > y;
}
};
//建大堆
template<class T>
struct Less
{
bool operator()(T& x, T& y)
{
return x < y;
}
};
template<class T,class Functor = Less<T>>
class Heap
{
public:
T* _hp;
size_t _size;
size_t _capacity;
public:
Heap(size_t capacity = 16):_capacity(capacity),_size(0){
_hp = new T[_capacity];
}
~Heap() {
delete _hp;
_size = _capacity = 0;
}
private:
void UpDateCapacity()
{
T* tmp = new T[_capacity * 1.5]; //开辟一个新的堆
assert(tmp);
memcpy(tmp, _hp, _size * sizeof(T));
std::swap(tmp, _hp);
_capacity = _capacity * 1.5;
}
//交换两个数的值
void swap(T& x, T& y)
{
T tmp = x;
x = y;
y = tmp;
}
void Up()
{
Functor func;
//从最后一个开始向上调整
int child = _size - 1;
int parent = (child - 1) / 2;
while (child) //child != 0
{
//大堆
if (func(child,parent))
{
swap(_hp[child], _hp[parent]);
child = parent;
parent = (child - 1) / 2;
}
else break;
}
}
void Down()
{
Functor func;
int parent = 0;
int child = parent * 2 + 1;
while (parent < _size)
{
if (child + 1 >= _size - 1 && func(_hp[child + 1],_hp[child]))
child++; //如果右孩子存在且右孩子 > 左孩子,那么child变成右孩子
if (child >= _size - 1) break; //左孩子不存在
if (func(_hp[child],_hp[parent]))
{
swap(_hp[parent], _hp[child]);
parent = child;
child = parent * 2 + 1;
}
else break;
}
}
public:
void push(const T& val)
{
if (_size == _capacity)
{
//扩容
UpDateCapacity();
}
_hp[_size++] = val;
Up();
}
T top()
{
assert(_size > 0);
return _hp[0];
}
void pop()
{
assert(_size > 0);
//根节点和最后一个节点交换
swap(_hp[0], _hp[_size-- - 1]);
Down();
}
};