算法提出
如果让推荐系统领域的从业者选出业界影响力最大、应用最广泛的模型,那么笔者认为90%的从业者会首选协同过滤。1992年, Xerox的研究中心开发了一种基于协同过滤的邮件筛选系统,用以过滤一些用户不感兴趣的无用邮件。2003 年,Amazon 发表论文 Amazon.com Recommenders Item-to-Item Collaborative Filtering,这让Amazon的推荐系统成为今后很长时间的研究热点和界主流的推荐模型。
算法的主要思想
一言以蔽之。协同过滤算法的核心思想就是物以类聚、人以群分。
那么关键问题就是我们怎么知道哪些人是同类的,哪些物品是同类的呢?
协同过滤算法说:我们可以给每个用户生成一个向量表示,在向量空间中距离相近的向量我们就认为他们是同一类的。物品同理。
那么问题又来了,我们如何为每个用户生成向量表示呢?
协同过滤算法说:这就是共现矩阵的艺术了。
详细步骤如下:
UserCF(人以群分)
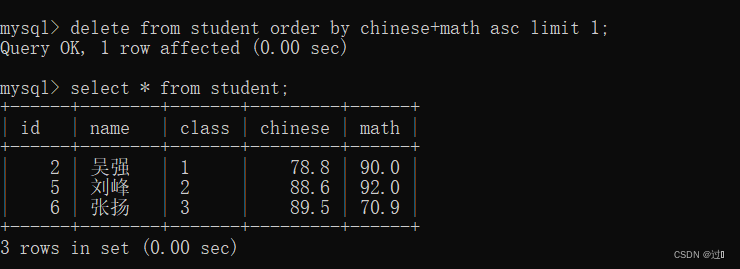
1、构建共现矩阵,矩阵的每一行代表一个用户,每一列代表一个物品。矩阵元素[i,j]表示用户i对物品j的评价。如下图所示

2、 在计算用户相似度,这里我们将共现矩阵数值化,即将矩阵中“点赞”的值设为1,将“踩”的值设为-1,“没有数据”置为0。之前说过矩阵的每一行代表一个用户,每一列代表一个物品。所以我们可以将共现矩阵中的行作为该用户的向量表示,列作为物品的向量表示。
UserCF的核心思想是人以群分,现在我们得到了用户的向量表示,那么计算用户i和用户j的相似度问题,就是计算用户向量i和用户向量y之间的相似度,两个向量之间常用的相似度计算方法有余弦相似度、皮尔逊相关系数、欧氏距离等。在相似用户的计算过程中,理论上,任何合理的“向量相似度定义方式”都 可以作为相似用户计算的标准。
3、最终结果排序,
在获得Top n相似用户之后,利用Top n用户生成最终推荐结果的过程如下。 假设“目标用户与其相似用户的喜好是相似的”,可根据相似用户的已有评价对目标用户的偏好进行预测。这里最常用的方式是利用用户相似度和相似用户的评价的加权平均获得目标用户的评价预测,如下所示。
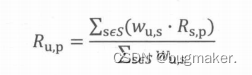
其中,wu,s是用户u和用户s的相似度,Rs,p是用户s对物品p的评分。
在获得用户U对不同物品的评价预测后,最终的推荐列表根据预测得分进行排序即可得到。至此,完成协同过滤的全部推荐过程。
UserCF的优缺点
以上介绍的协同过滤算法基于用户相似度进行推荐,因此也被称为基于用户的协同过滤(UserCF ),它符合人们直觉上的“兴趣相似的朋友喜欢的物品, 也喜欢”的思想,但从技术的角度,它也存在一些缺点,主要包括以下两点。
(1)在互联网应用的场景下,用户数往往远大于物品数,而UserCF需要维 护用户相似度矩阵以便快速找出Top w相似用户。该用户相似度矩阵的存储开销 非常大,而且随着业务的发展,用户数的增长会导致用户相似度矩阵的存储空间 以m2的速度快速增长,这是在线存储系统难以承受的扩展速度。
(2 )用户的历史数据向量往往非常稀疏,对于只有几次购买或者点击行为的 用户来说,找到相似用户的准确度是非常低的,这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预定、大件商品购买等低频应用)。
ItemCF(物理类聚)
1、构建共现矩阵
2、计算共现矩阵两两列向量间的相似性(相似度的计算方式与用户相似度的计算方式相同),构建物品的相似度矩阵。
3、获得用户历史行为数据中的正反馈物品列表。
4、利用物品相似度矩阵,针对目标用户历史行为中的正反馈物品,找出相似的TopN个物品,组成相似物品集合。对相似物品集合中的物品,利用相似度分值进行排序,生成最终的推荐列表。
如果一个物品与多个用户行为历史中的正反馈物品相似,那么该物品最终的相似度是多个相似度的累加,如下式所示:
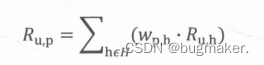
其中H是目标用户的正反馈物品集合,wp,h是物品p与物品h的物品相似度,Ru,h是用户对物品h的已有评分。
ItemCF与UserCF的不同
UserCF基于用户相似度进行推荐,使其具备更强的社交特性, 用户能够快速得知与自己兴趣相似的人最近喜欢的是什么,即使某个兴趣点以前不在自己的兴趣范围内,也有可能通过“朋友”的动态快速更新自己的推荐列表。 这样的特点使其非常适用于发现热点,以及跟踪热点的趋势。
ItemCF更适用于兴趣变化较为稳定的应用,比如电商场景。用户在一个时间段内更倾向于寻找一类商品,这时利用物品相似度为其推荐相关物品是契合用户动机的。在Netflix的视频推荐场景中,用户观看电影、电视剧的兴趣点往往比较稳定,因此利用ItemCF推荐风格、类型相似的视频是更合理的选择。