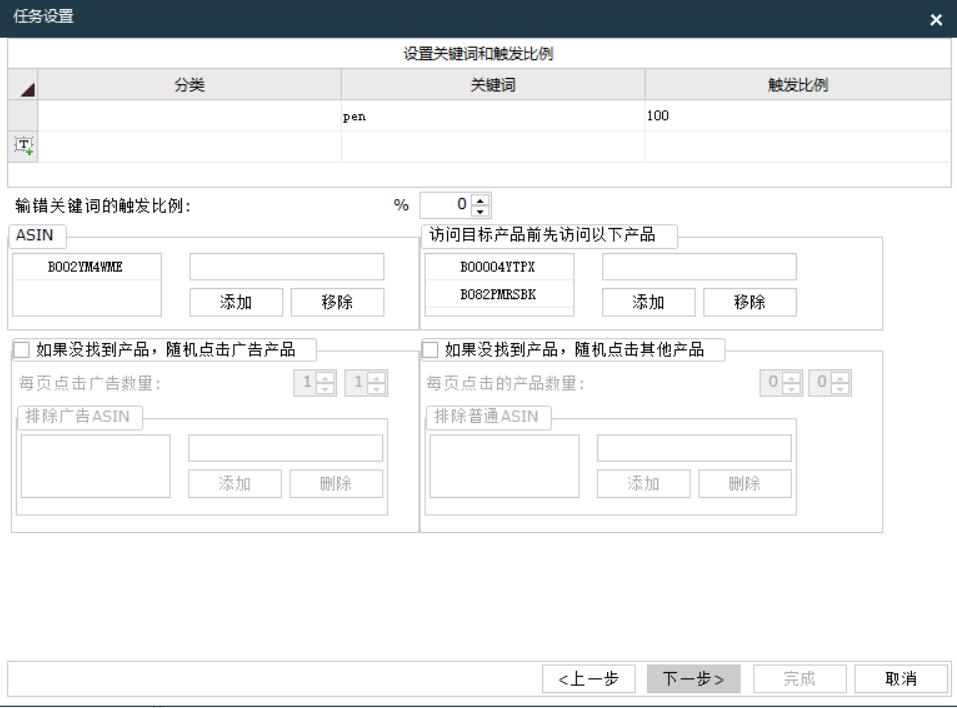
在进行网络抓取时,我们常常会遇到目标网站对反爬虫的监测和封禁。为了规避这些风险,使用代理IP成为一种常见的方法。然而,如何应对目标网站的反爬虫监测,既能保证数据的稳定性,又能确保抓取过程的安全性呢?本文将向您分享一些关键策略,帮助您迈过反爬虫的障碍,提高抓取成功率,并保护自己的网络抓取工作的稳定与安全。
首先,了解目标网站的反爬虫机制是至关重要的。不同的网站有不同的反爬虫策略,掌握其原理和特点,能够帮助我们更有效地应对。常见的反爬虫策略包括验证码、IP封禁、请求频率限制等。一旦我们能够清楚了解目标网站采用的反爬虫手段,我们就能够有针对性地制定解决方案。
其次,合理使用代理IP是应对反爬虫监测的关键。使用代理IP能够隐藏我们的真实IP地址,增加抓取时的匿名性。但是,我们需要明确了解代理IP的质量和可用性。选择稳定和高匿名性的代理IP供应商,能够大大减少被封禁的风险。同时,我们可以采用代理IP池的方式,不断更换和轮换代理IP,使抓取行为更隐蔽,提高反封禁的能力。
另外,模拟真实用户行为也是绕过反爬虫的一个重要策略。通过设置请求头信息、缓慢访问页面、模拟用户登录等手段,使我们的抓取行为更像是真实用户的访问行为,以规避反爬虫的监测。此外,我们还可以使用谷歌的无头浏览器工具Puppeteer等技术,模拟真实的浏览器环境和用户操作,进一步增加抓取的成功率。
同时,定期更新和维护我们的爬虫代码也是重要的一环。随着目标网站的不断升级和调整,其反爬虫机制也会发生变化。我们需要密切关注目标网站的更新动态,并根据需要及时修改爬虫代码,以保持抓取的稳定性和高效性。
最后,我们需要遵守道德和法律的约束。在进行网络抓取时,我们要遵守目标网站的Robots协议,避免未经允许访问和使用网站数据。我们应该尊重网站的合法权益,合法使用抓取的数据,并遵守相关法律法规,以免给自己和他人带来不必要的法律风险。
在应对目标网站的反爬虫监测时,了解反爬虫机制、合理使用代理IP、模拟真实用户行为、定期更新维护爬虫代码以及遵守道德和法律,都是重要的策略。让我们以谨慎的态度和专业的技术,应对反爬虫的挑战,保证数据的稳定和安全,并确保自己的网络抓取工作顺利进行。