目录
- 5.4树、森林
- 5.4.1树的存储结构
- 1. 双亲表示法(顺序存储):
- 2. 孩子表示法(顺序+链式)
- 3. 孩子兄弟表示法(链式)
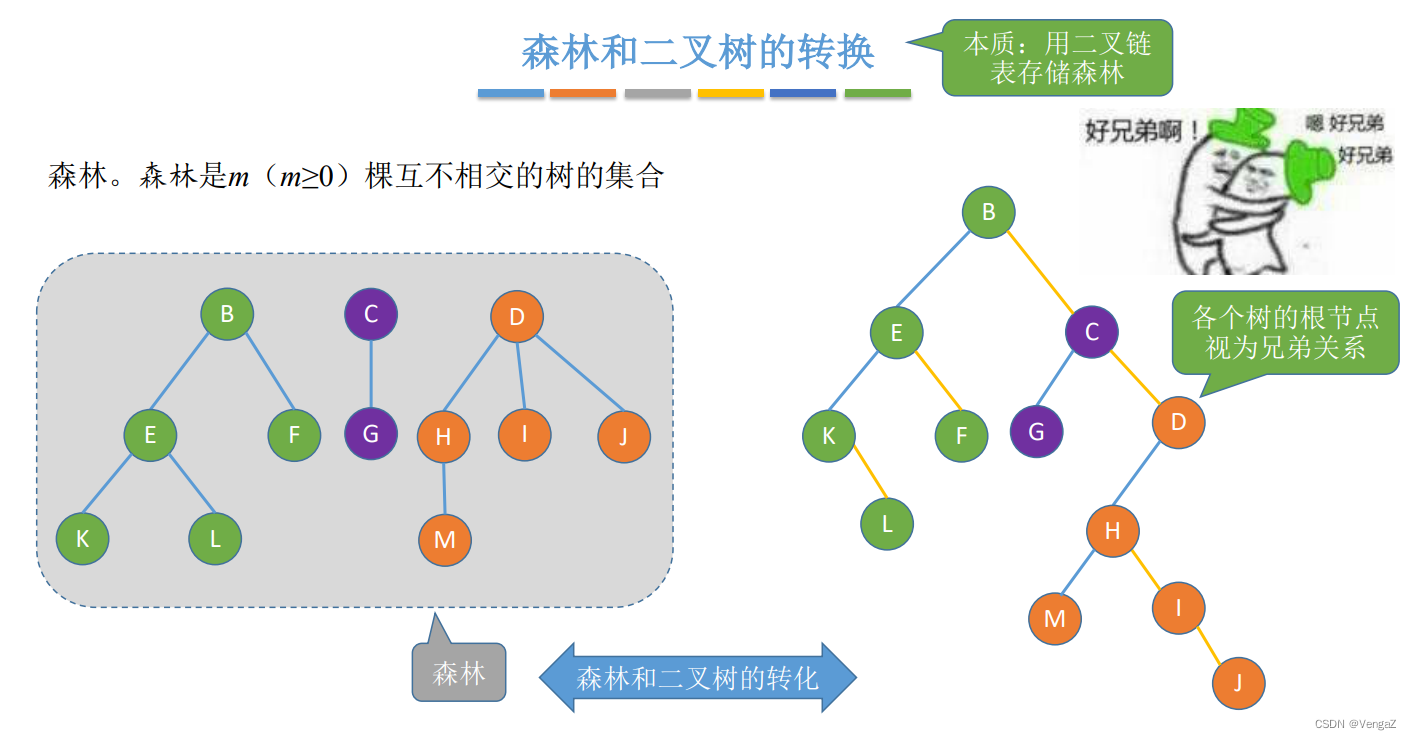
- 5.4.2树、森林与二叉树的转换
- 5.4.3树、森林的遍历
- 1. 树的遍历
- 先根遍历
- 后根遍历
- 层序遍历(队列实现)
- 2. 森林的遍历
- 数据结构:树和森林的存储结构与遍历方式
- 树的存储结构
- 树的存储结构:链式存储结构
- 树的存储结构:数组存储结构
- 森林的存储结构
- 森林的存储结构:链式存储结构
- 森林的存储结构:数组存储结构
- 树和森林的遍历方式
- 前序遍历
- 中序遍历
- 后序遍历
- 结论
5.4树、森林

5.4.1树的存储结构
1. 双亲表示法(顺序存储):
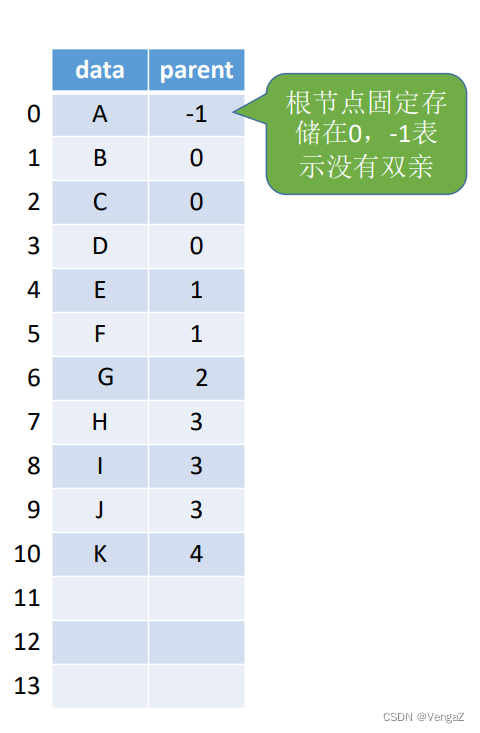
每个结点中保存指向双亲的指针
数据域:存放结点本身信息。
双亲域:指示本结点的双亲结点在数组中的位置。
#define MAX_TREE_SIZE 100 //树中最多结点数
typedef struct{ //树的结点定义
ElemType data;
int parent; //双亲位置域
}PTNode;
typedef struct{ //树的类型定义
PTNode nodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点数
}PTree;
基本操作:
- 增:新增数据元素,无需按逻辑上的次序存储,只要在最后增加并且写上其父节点;(需要更改结点数n)
- 删(叶子结点):① 将伪指针域设置为-1;②用后面的数据填补(不会中间出现空数据);(需要更改结点数n)
- 查询:①优点-查指定结点的双亲很方便;②缺点-查指定结点的孩子只能从头遍历,空数据导致遍历更慢;
- 所以删除时用②用后面的数据填补(不会中间出现空数据);(需要更改结点数n)这个方法更好
- 求双亲很方便,但是求结点的孩子需要遍历整个结构
2. 孩子表示法(顺序+链式)
孩子链表:把每个结点的孩子结点排列起来,看成是一个线性表,用单链表存储,则n个结点有n个孩子链表(叶子的孩子链表为空表)。而n个头结点又组成一个线性表,用顺序表(含n个元素的结构数组)存储。
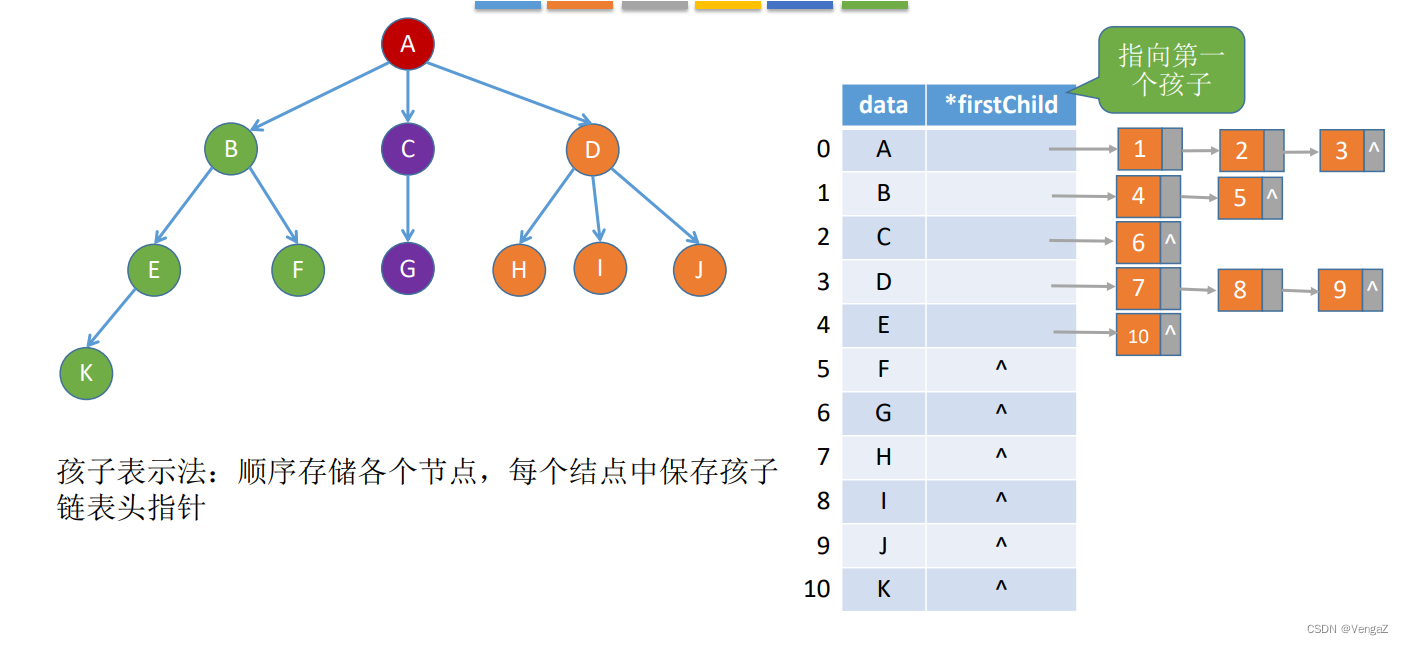
问题在于:找孩子方便,找双亲不方便,需要遍历整个结构(n个结点的孩子链表指针域指向的n个孩子链表)
struct CTNode{
int child; //孩子结点在数组中的位置
struct CTNode *next; // 下一个孩子
};
typedef struct{
ElemType data;
struct CTNode *firstChild; // 第一个孩子
}CTBox;
typedef struct{
CTBox nodes[MAX_TREE_SIZE];
int n, r; // 结点数和根的位置
}CTree;
3. 孩子兄弟表示法(链式)
第一个孩子与右兄弟
特点:
- 最大的优点是实现树转换成二叉树和相互转换
- 易于查找结点的孩子
- 缺点是从当前结点查找双亲很麻烦,可以为每个结点设置一个parent指针指向父结点
- 孩子表示法存储的树,在物理上是二叉树
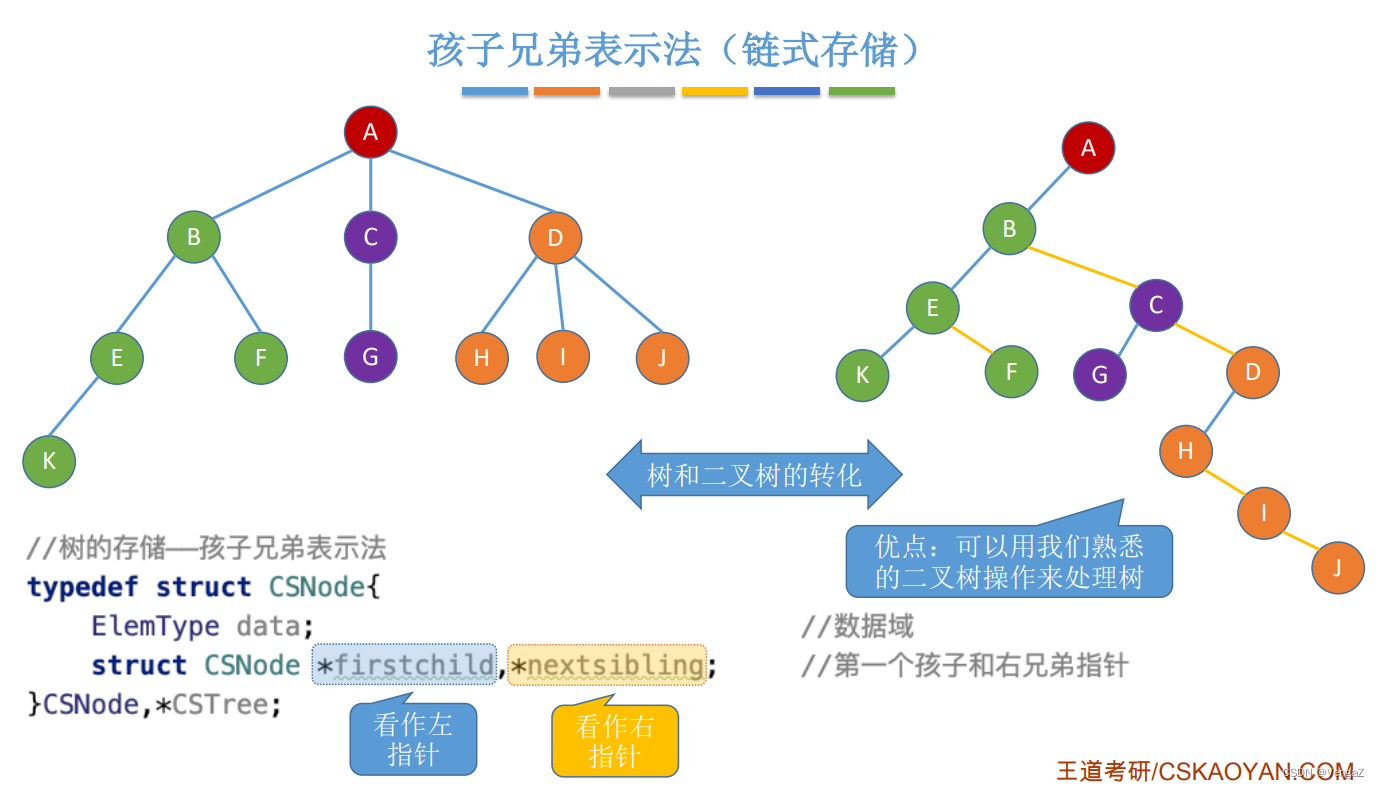
typedef struct CSNode{
ElemType data; //数据域
struct CSNode *firstchild, *nextsibling; //第一个孩子和右兄弟指针, *firstchild 看作左指针,*nextsibling看作右指针
}CSNode. *CSTree;
5.4.2树、森林与二叉树的转换
本质:森林中各个树的根结点之间视为兄弟关系

5.4.3树、森林的遍历

1. 树的遍历
先根后根都是深度优先,层次是广度优先遍历
先根遍历
- 若树非空,先访问根结点,再依次对每棵子树进行先根遍历;(与对应二叉树的先序遍历序列相同)树的深度优先遍历
void PreOrder(TreeNode *R){
if(R!=NULL){
visit(R); //访问根节点
while(R还有下一个子树T)
PreOrder(T); //先跟遍历下一个子树
}
}

后根遍历
树的深度优先遍历
- 若树非空,先依次对每棵子树进行后根遍历,最后再返回根节点;(与对应二叉树的中序遍历序列相同,但是直接看的话还是后序遍历序列,不转化成二叉树来看的话就直接用后序遍历求解)
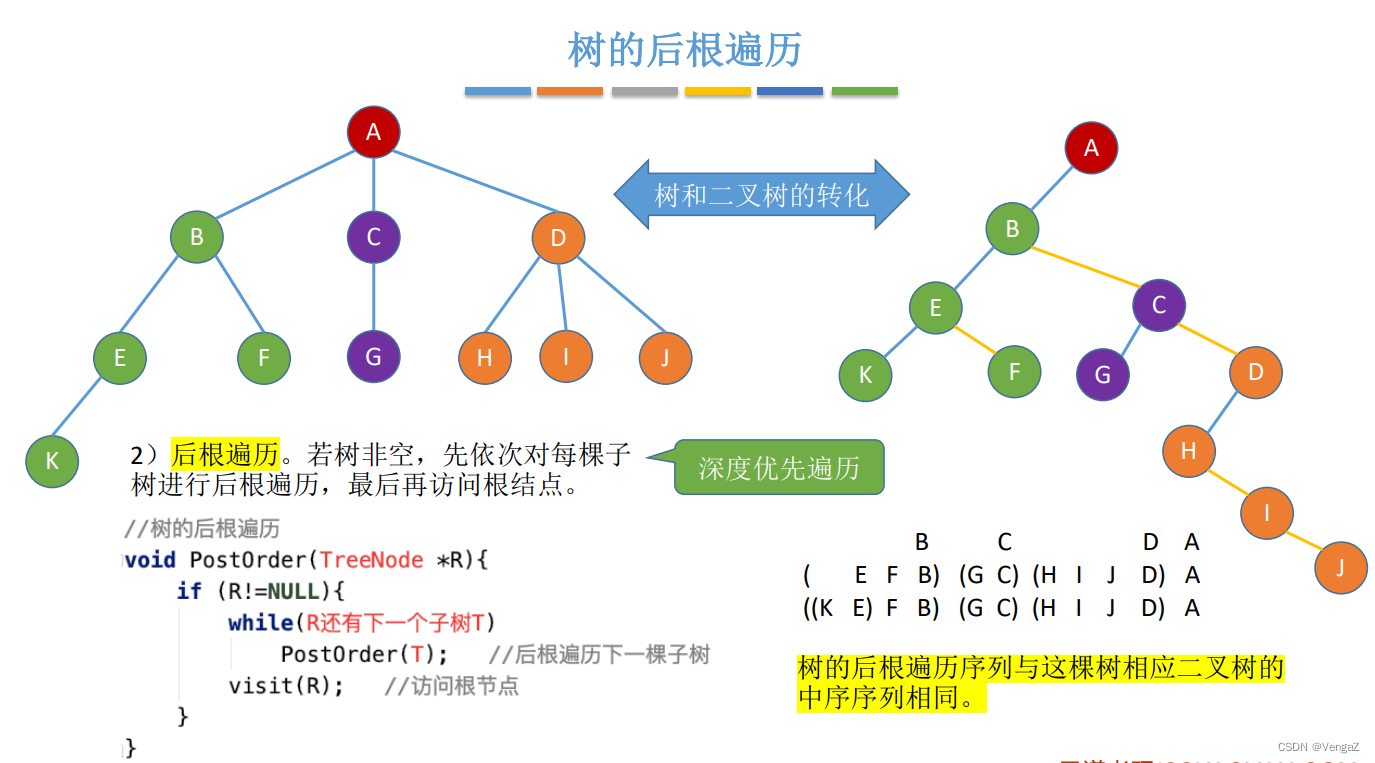
void PostOrder(TreeNode *R){
if(R!=NULL){
while(R还有下一个子树T)
PostOrder(T); //后跟遍历下一个子树
visit(R); //访问根节点
}
}
层序遍历(队列实现)
广度优先遍历
若树非空,则根结点入队;
若队列非空,队头元素出队并访问,同时将该元素的孩子依次入队;
重复以上操作直至队尾为空;
2. 森林的遍历
先序遍历:等同于依次对各个树进行先根遍历;也可以先转换成与之对应的二叉树,对二叉树进行先序遍历;
中序遍历:等同于依次对各个树进行后根遍历;也可以先转换成与之对应的二叉树,对二叉树进行中序遍历;
数据结构:树和森林的存储结构与遍历方式
树和森林是在计算机科学中常见的非线性数据结构,它们在组织和存储数据方面具有重要的作用。本文将介绍树和森林的存储结构,并详细解释它们的遍历方式。
树的存储结构
树是一种由节点和边构成的数据结构,其中有一个特殊的节点被称为根节点,其他节点可以分层次地连接在根节点下面。每个节点可以有零个或多个子节点,而每个子节点可以继续拥有自己的子节点,形成了一个层次化的结构。
树的存储结构:链式存储结构
树的链式存储结构是通过节点之间的指针连接来表示树的。每个节点都包含一个数据域和多个指向子节点的指针。根节点没有父节点,而其他节点有且仅有一个父节点。
struct TreeNode {
int data;
TreeNode* parent;
vector<TreeNode*> children;
};
树的存储结构:数组存储结构
树的数组存储结构是通过数组来表示树的。将树的节点按层次遍历的顺序依次存储在数组中,通过数组下标可以找到节点之间的关系。
struct TreeNode {
int data;
};
TreeNode tree[MAX_SIZE];
森林的存储结构
森林是由多个不相交的树组成的集合,每个树都是独立的。每个树的根节点都不属于其他任何树的子节点,因此它们是相互独立的树结构。
森林的存储结构:链式存储结构
森林的链式存储结构是通过多个树的链式存储结构组合在一起构成的。每个树都是一个独立的链式存储结构。
vector<TreeNode*> forest;
森林的存储结构:数组存储结构
森林的数组存储结构是通过多个数组存储结构组合在一起构成的。每个数组存储结构表示一棵树。
TreeNode forest[MAX_TREES][MAX_SIZE];
树和森林的遍历方式
树和森林的遍历方式是指访问树或森林中所有节点的方法。常见的树和森林遍历方式有三种:前序遍历、中序遍历和后序遍历。这三种遍历方式是基于节点的访问顺序来定义的。
前序遍历
前序遍历是指先访问根节点,然后按照从左到右的顺序依次访问每个子节点的遍历方式。在树和森林的存储结构中,前序遍历可以通过递归或栈的方式来实现。
中序遍历
中序遍历是指先按照从左到右的顺序依次访问每个子节点,然后再访问根节点的遍历方式。在树和森林的存储结构中,中序遍历可以通过递归或栈的方式来实现。
后序遍历
后序遍历是指先按照从左到右的顺序依次访问每个子节点,然后再访问根节点的遍历方式。在树和森林的存储结构中,后序遍历可以通过递归或栈的方式来实现。
结论
树和森林是非常重要的数据结构,它们在计算机科学中有着广泛的应用。通过链式存储结构和数组存储结构,我们可以灵活地表示树和森林,并实现它们的遍历方式。掌握树和森林的存储结构和遍历方式,对于学习和理解更复杂的数据结构和算法有着重要的意义。








![[openCV]基于赛道追踪的智能车巡线方案V1](https://img-blog.csdnimg.cn/e950a36d0a6b4542b379b74e5eed3575.png)