文章目录
- 常见的缓存一致性解决方案
- 双写模式
- 失效模式
- 两种模式的总结
- 上述模式的改进
常见的缓存一致性解决方案
这里的缓存一致性其实就是缓存中的数据和数据库中的数据如何保持一致.
这个问题根据具体的业务场景和需要解决起来略有差异,但是总体看以分为两类,双写模式和失效模式,那他们是怎样工作的呢?有什么缺点以及怎样进行改进呢? 这里总结说明一下.
双写模式
总的流程就是先写数据库,数据库写成功了,去更新缓存.
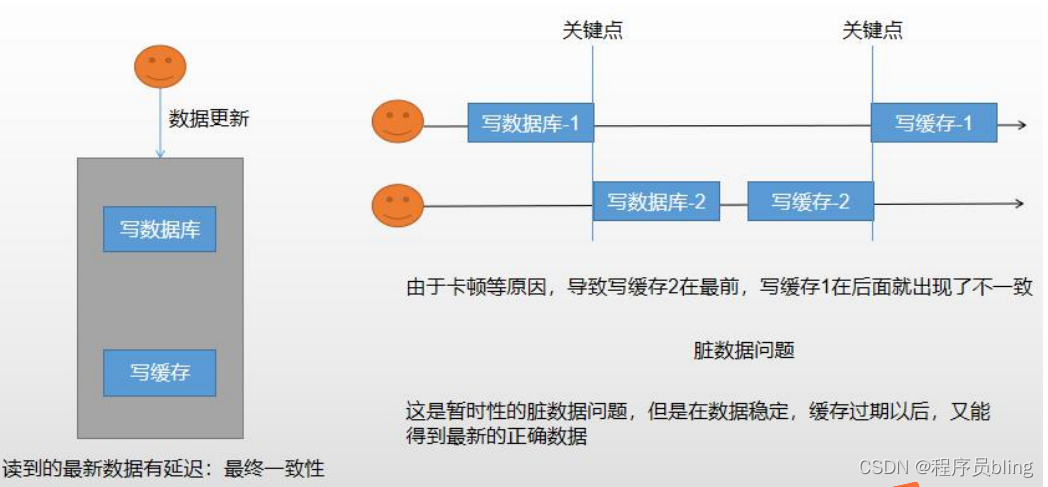
在大并发下可能会产生的问题:
有两个更新请求, 请求1先去写数据库,写完数据库再写缓存的时候因为卡段等某些原因,导致请求2优先完成了另一个写数据库,写缓存的操作,这时候请求1再去写缓存,缓存里的数据就和数据库中的数据不一致了.

失效模式
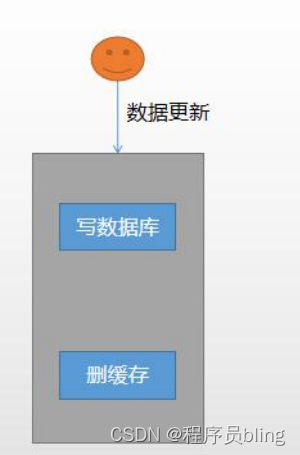
总体流程:
更新的时候先更新数据库,然后直接删除缓存,等后面有查询操作的时候,会自动将最新数据放到缓存中
注意:
在将数据库里的数据查出来放入到缓存中时,首先要判断缓存中是否有,如果有的话,说明在这个期间有别的请求对缓存做了操作,此时就不应该再去处理了.否则很容易造成不一致问题.
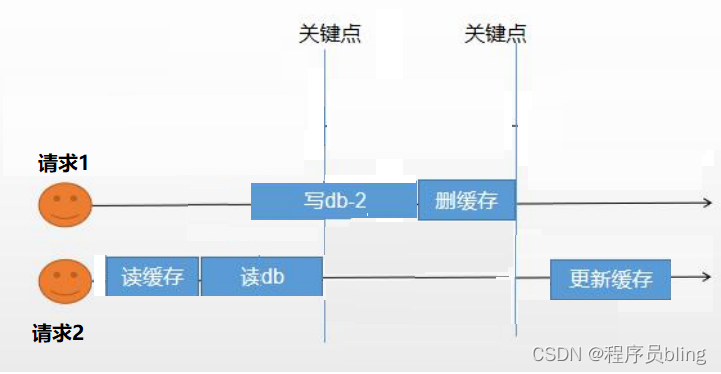
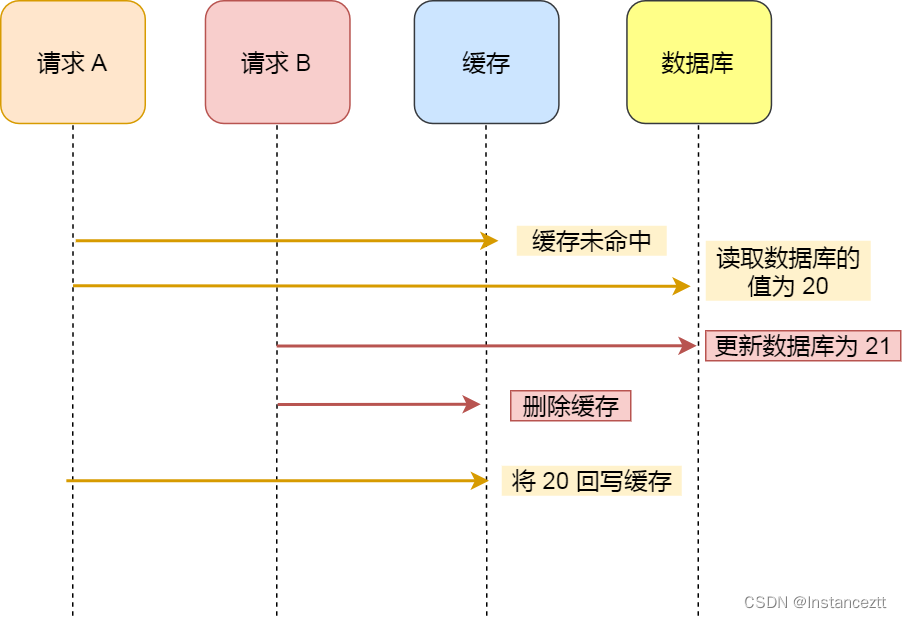
并发下存在的问题:
假如某一条数据因为过期或者被删除了,在缓存中并没有.
此时有两个请求,请求2先去读缓存,缓存中没有,然后去数据库中查询出来,在准备去更新缓存的时候,因为gc或者cpu切换等原因,请求1先完成了更新数据库删除缓存的操作,这个时候请求2将查询出来的数据放入缓存.缓存里面的数据就变成了一个旧数据.
两种模式的总结
保持数据一致性的解决方案:
上述两种模式在大并发下都会产生数据不一致情况,其实解决方案也趋于一致.主要就是两种
- 加锁,上述问题产生的根本原因是写数据库,更新缓存的操作不是一个整体,不是原子性的,那我们可以通过加锁,将其变成一个整体.
那加锁又有不同的方式,如果是读多写少的情况,可以加分布式读写锁,来规避读读之间的互斥,提高并发量,如果是写多读少的情况,说实话本身就没有必要放到缓存中了. - 加过期时间,如果我们的业务允许可以有短暂性的不一致的话,这种场景都不用再纠结了.直接加一个短暂的过期时间就好了, 比如说一天,当数据过期后,又会从数据库加载最新的数据.
主要区别:
这两种模式最主要的区别在于一个是更新缓存,一个是删除缓存,那要怎样选择呢?
最主要的区分点在于这个数据会不会被频繁的访问到?
一般来讲,访问数据也遵循28法则,即20%的数据占据了80%的访问量,那如果这个数据需要被非常频繁的访问到,并且不涉及到什么复杂计算,那应该更新缓存, 否则则应该采用更简单的删除缓存.
上述模式的改进
上面两种模式及解决方案可能还是会存在一些小问题,比如说加锁肯定会影响性能,那还有一种更好的方式,只是复杂度会高一些.
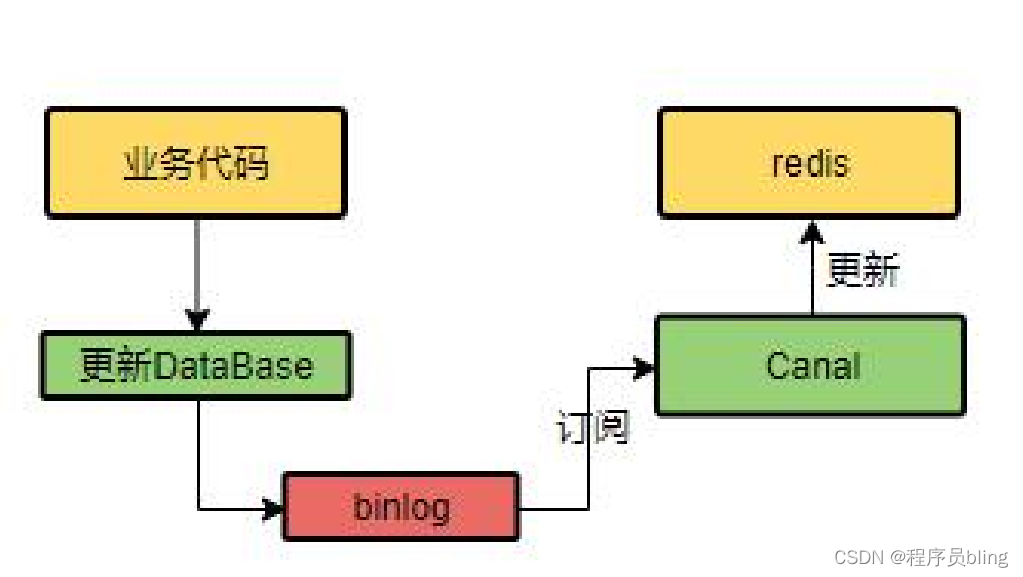
上述产生并发问题的最关键一点就是最新的数据没有更新到redis中,那我们可以使用阿里开源的canal,它其实是将自己伪装成mysql的从服务器,通过监听变更日志(binlog)的方式,将数据库的更新按序同步到redis中.
这种方式的另一个好处就是在编码期间只需要更新数据库,都不需要去更新缓存,
今天的分享就到这里了,有问题可以在评论区留言,均会及时回复呀.
我是bling,未来不会太差,只要我们不要太懒就行, 咱们下期见.








![[附源码]Python计算机毕业设计SSM基于的高校在线办公系统(程序+LW)](https://img-blog.csdnimg.cn/c0a837db349c4b4bbe5f347368eda122.png)



