1.前言
系统设计的核心作用是在业务现实世界和抽象的IT实现之间建立起一道桥梁。
与其他行业被物理特性限制所束缚不同,软件世界可以变得无限庞大,而限制软件发展的其实是人的认知能力。所有软件设计服务的目标其实都是管理人的认知,是关于人有限的精力如何学习软件中无限多的知识(Knowledge)的问题。
软件行业从传统的瀑布开发模式,过渡到了敏捷开发模式,对于文档,敏捷宣言中说的是“工作的软件高于详尽的文档”,但实际工作中开发人员写的文档是越来越少,或者是能不写就不写;流程上,更是恨不得需求还没有出来就直接撸代码,撸完代码就直接上线。
缺乏整体系统设计,设计出来的系统就不够完善,再加上快速的系统迭代,导致系统越来越难以维护,开发成本越来越高,一个项目需要参与的人越来越多,最终没有人能够说明清楚,这个系统具体是如何运行的了。随着团队人员的更替,加上每个人的设计思路又不一样,更加加重了系统的复杂性。
| 上面也就引入了两个问题: |
|---|
| 1. 缺乏文档问题:不清楚系统长什么样? |
| 2. 软件复杂度高的问题:迭代修改系统的成本高。 |
上面两个问题在MTDD都有相应的解法,后面我们会详细讲述,接下来我还是再详谈一下软件复杂度。
2.软件复杂度
2.1 软件复杂度的症状和原因
《软件设计哲学》这本书中提到,软件复杂度的三种症状:
1. 变化放大:需要修改一个地方,却发现改动的点涉及全站,导致难度倍增;
2. 认知负荷:开发者需要完成一项任务的知识量;
3. 未知:开发者在修改代码后,不知道它的实际影响面。
为了从源头上解决这些问题,John Ousterhout教授提出:从项目一开始就要严格遵循进行软件设计的原则,那些为了赶工期而没有经过良好设计的代码,最终经过多次迭代后,都会变得越来越臃肿,继而变得再也无法维护了。
我非常认可John Ousterhout的观点,但实际操作中发现基本不具有可行性,原因:
1.从瀑布模式到敏捷开发,已经很难回去了。
2. 是否遵循良好的软件设计原则很难衡量。
3. 没有这么多的时间来检查(代码review,设计renview)是否有按照这些原则来设计和编码。
我的观点:
对于“简化模块依赖”,“减少模糊性”,“高内聚低耦合”这些原则的话术,知道的人就知道怎么做,不知道的人还是不知道怎么做。这些术语缺少实际的指导性。
2.2 软件复杂度是怎么引入的(另外一个角度)
2.2.1 我们来看一个例子

2.2.2 系统到底是谁做出来的
一个有意思的现象:


那系统到底是谁做出来的呢?(这里主要说的是业务系统。一些中间件之类的系统,基本都由研发来完成的。)


系统设计离不开,业务人员、产品经理以及技术研发的合作,业务和产品的需求没有理清楚,同样会导致系统复杂度提升。
2.2.3 另外一种系统复杂度引入环节

系统各主要相关方缺乏对系统设计的信息拉齐,给系统复杂度的提升同样有重要的贡献。
那么如何让各角色更好的进行信息对齐,这就引入了MTDD。
3.一种新型的系统设计解决方案:MTDD
前面提到了《软件设计哲学》作者提出了一些系统设计总结,也有些人提出了一些方法论,比如领域驱动设计(DDD),测试驱动开发(TDD),行为驱动开发(BDD);但是这些模式,都是从设计方法论上给与指导,战术上指导偏少。下面我们来介绍我自己沉淀的一个方法论,和战术指导MTDD&MTDP。
3.1 MTDD是什么
MTDD的全称是:Module Tree Drive Design, 模块树驱动设计,也可以叫做能力树驱动设计。MTDD是一种系统设计模式,并同时提供了战术层的SDK。
MTDD主要思想是让业务,产品、研发共同对复杂业务系统中的模块进行分析,并对这些业务模块做好分层分类,最终形成各方达成一致的一棵模块树;研发人员开发可以通过给定的SDK,将系统中的代码按照模块的方式进行打标分类,系统根据代码中打标分类,自动生成一颗可视化的模块树。通过这个方式,让系统与业务保持高度一致。
MTDD思想主要体现在:
- 当业务和产品需要对系统能力进行新增、修改、或者扩展时,可以对照系统这颗可视化的模块树进行沟通,然后进行思考和设计具体的哪个或者哪些模块需要进行修改或者扩展,并产出修改后的最终结果。
- 研发人员接到接到需求后开发完成后,新开发的功能就会自动的在系统的模块树上进行呈现。
- 产品和业务验收时,就可以对照系统上的模块树,进行功能验收。
3.2 MTDD的特点
3.2.1 模块化
在系统设计中,模块是指一组相互依赖的程序元素,通常是在模块内部完成特定的工作。模块也可以被组合以形成更大的、更复杂的系统。子模块则是模块的一部分,通常是实现特定的功能。
在MTDD中, 模块化更多的是从业务的角度上来说的,比如一个营销触达模块,比如仓储系统中的入库模块;模块下面还可以有子模块,子模块也可以有子子模块, 这个可以根据一定的颗粒度进行灵活拆分,重点是业务,产品、研发三方达成一致,并且明确模块的关系(父子关系)。
3.2.2 分类与分层
在系统设计中,分层和分类是非常重要的,这有助于提高系统的可扩展性和可维护性,也能很好的降低人的认知负荷。
- OOD(面对对象设计)本质就是一种分类思想。
- DDD(领域驱动设计)本质也是一种分类思想。
分层设计:
在现实世界中,所有我们见到的事物,人类都自然的对其给与了分层,比如:

再比如在仓储管理中,也会有天然的分层:
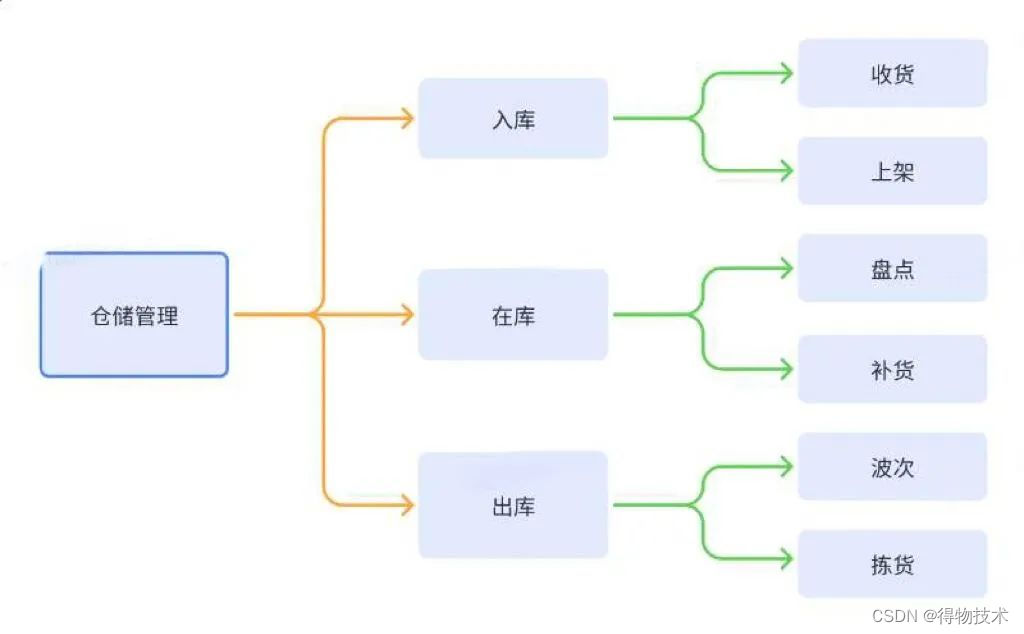
分层分类-复杂度分解:
我们的目标是将一些同类型的提高一个抽象层次,将大脑比较难处理的9个概念简化成3个,这样就无需记忆其中的每个概念,另外由于较高层次的思想总是能够提示下面一个层次的思想,所以记忆起来会更方便。所有的思维过程(思考、记忆、解决问题)都应该使用这样的分组和概括的方法,将大脑中的无序信息组成一个相关关联的金字塔结构。
每个模块下又可以有多个子模块。
总而言之,设计人员对模块进行分层分类后,可以大大降低思考复杂度, 这个很好理解。

3.2.3 可视化
分层分类的模块以树状接口进行可视化呈现。

| 左边图描述的是:业务、产品、研发对齐需求后,认为的业务系统上需要建设两个子模块的能力。 |
|---|
| 右边的图是:研发实现产品需求后,系统自动生成的能力树的样子。 |
3.2.4 强大的配置化能力
所有的业务配置,都是业务相关的,系统用来控制业务的逻辑,本质就是业务的一部分。在传统的业务系统中一般有两种方式来实现:
- 使用需要一个配置中心,配置中心一般都使用key-value的方式来存储。业务系统根据配置的key到配置中心来获取value,并解析value的值。业务人员直接在配置中心来做配置值的修改。
- 每个配置单独开发配置页面,业务人员在配置页面上进行值修改。
这两种方式都存在一些问题:
- 使用配置中心,虽然将所有的配置都进行了统一,但是面对一些负责配置时,需要采用类似json这种格式来存储,修改的时候只能修改json的值,无法通过页面富样式页面来修改。
- 每个页面单独开发配置页面,对配置友好,但是开发工作量大,因为每个配置都需要前端开发。
使用MTDD配置化能力时,就可以解决上面两个问题:
我的观点:
业务配置一定属于具体的业务模块,因为配置是用户控制某个具体的模块逻辑,所以配置尽量挂在模块下面是一个非常自然的做法。
3.2.5 其他优势
- 让业务,产品,在提需求的时候,就能够以系统能力的方式去思考。
- 在有新需求时,产研可以方便的在能力树上找到需要改动的模块。
- 测试的影响范围也很容易确定。对修改友好,影响范围可控。
- 让程序员天然的进行开闭原则,对新增开放,对修改改封闭。
3.3 MTDD作用与总结
系统设计的核心作用是在业务现实世界和抽象的IT实现之间建立起一道桥梁。而业务系统本身就是现实世界在计算机系统中的映射。
现实世界是一个模块化的,层次化的树状结构,所以业务系统就应该自然的通过模块化的树状结构来进行映射。
模块树驱动设计闭环

4.MTDD实战
4.1 MTDD战略层
4.1.1 统一语言
DDD中也有统一语言,或者叫做“通用语言(Ubiquitous Language )”
当团队成员不能享用一个公共语言来讨论领域时,项目会面临严重的问题。领域专家使用自己的行话,技术团队成员在设计中也用自己的语言讨论领域。 代码可能是一个软件项目中最重要的产物,但每天用来讨论的术语却与代码中使用的术语脱节了。即使是同一个人都需要使用不同的 语言来交谈和书写,所以要想完成对领域的深刻表达通常需要产生 一种临时形式,但这种形式不会出现在代码甚至是书写的内容中。 在交流的过程中,需要做翻译才能让其他的人理解这些概念。开发 人员可能会努力使用外行人的语言来解析一些设计模式,但这并一定都能成功奏效。领域专家也可能会创建一种新的行话以努力表达 他们的这些想法。在这个痛苦的交流过程中,这种类型的翻译并不能对知识的构建过程产生帮助。
上面这段是话是摘自《领域驱动设计精简版 》
Eric Evans 早就意识到,需要在领域专家和研发之间共用一套通用语言,并且Eric Evans也做了大量的举例说明,来说明什么是通用语言,以及统一通用语言可以更好的服务于系统设计。
MTDD更也是站在巨人的肩膀上,提供了一个方法论:让业务,产品,技术在系统设计之前,一起对照系统模块树来进行沟通;对于一个新功能,一起思考是在某个模块下新增模块,还是修改货扩展模块内部的逻辑;在对齐后,就可以进行开发了,并且研发有一定的范式开做开发,开发后,系统的模块树就能够自动可视化的呈现出来;业务和产品也可以通过可视化的方式进行验收;
4.1.2 按定制规范来做设计和开发
上面说了在业务方、产品、技术在参照能力树根据需求并对齐需要开发的模块后,研发可以按照一定的范式做系统开发;这是因为我们提供了一套开发的SDK,以及SDK的使用文档,来帮助研发人员来进行基于能力树功能的开发。系统功能开发完成后,相应的模块信息就可以自动在模块树页面上进行呈现。当然想要在页面上进行呈现,需要有前端来支持。
这个规范主要由几个主要的java注解来实现:
- @Module
- @ModuleConfig
- @ConfigItem
4.1.3 系统的模块化以及分层分类
使用上面的java注解,对代码中模块进行打标。
业务模块化,并且做了分层与分类,那么系统中的代码需要根据业务中的分层分类进行进行分类打标,使其与业务分层分类保持一致。
4.1.4 持续重构(Continue Refactor)
我们这个世界够复杂了吧,如果让你设计一个IT系统来实现刻画这个世界的方方面面,我打赌一定没有人搞得定;但现实中的这个世界还是能够有条不紊的发展演进,没有需要出现“推倒重来”的现象,为什么呢, 我认为是我们的世界一直在用各种方式不停的重构。
“物竞天择,适者生存”出自达尔文的进化论,达尔文在1859年出版的《物种起源》一书中系统地阐述了他的进化学说。物竞天择,适者生存是指物种之间及生物内部之间相互竞争,物种与自然之间的抗争,能适应自然者被选择存留下来的一种丛林法则。
对于软件系统也是这样,业务是在不停的发展, 我们的认知也是一直不断的更新,当“我们”通过可视化的能力树发现一些突兀时,那肯定是某个或者某些模块拆分不正确,或者模块提供的能力不合适,这时,我们就可以考虑对模块树进行重构了,要么是拆分模块,要么是调整模块的关系,要么是修改模块的职责。
4.1.5 关于产品需求
如果产品了解MTDD,那么就会提出更加符合产品化的需求了。
如果研发对MTDD理解深入,那么当产品的需求不符合产品化,能力化时,就会与产品进行沟通,产品修改需求,以便更好的设计出产品化,系统能力化的需求。
| ✔好的产品需求 | ×不好的产品需求 |
|---|---|
| 对现有系统能力的扩展;增加新的系统能力 | 针对特定的业务需求 定制系统能力 |
4.2 MTDD战术层(MTDP)
MTDP的全称是Module Tree Drive Programing, 领域树驱动编程。
4.2.1 模块
注解@Module的定义
/**
*
* 模块注解,打在一个服务类上,Module注解是继承了Component注解,因此它注解的类可以被实例化到Spring中去
* 服务启动时会扫码所有Module类,将他们组装成树进行持久化。
*/
@Target({ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Component
@Documented
public @interface Module {
/**
* 该模块的key
* 在设置模块的key的时候,在同一个服务里面(同一个根节点),如果两个类设置的key是一样,最后会被去重为一个模块,无论是单体服务还是分布式工程。
* moduleKey全局唯一,就算它们归属不同的根节点,也不能设置一样的moduleKey,
* 不同根节点的模块,如果设置了同一个moduleKey,后部署的服务将无法能力树的变更情况进行持久化。
* @return
*/
String moduleKey();
/**
* 用于指定该模块的父模块,
* 根节点的parentModule指定为 {@link Void}.class。
* 每个模块指定他们的夫模块,直到可达根节点,最后生成一颗树。
* 指定parentModule时一定要注意,不能循环依赖了,循环依赖的情况下,服务将抛出异常无法启动,
* @return
*/
Class<?> parentModule();
/**
* 该模块名称
* @return
*/
String moduleName();
/**
* 模块描述,一个该模块详细的描述
* @return
*/
String moduleRemark() default "";
/**
* 能否被剪枝,你是可以设置模块能不能被剪枝,默认是不可以的(后续会根据数量对比情况进行调整默认值)。
* 我们应该将系统中必要的功能设置为无法裁减,将那些加强性的能力,智能化的能力,衍生化的能力,非基本的能力设置为可以裁减
* @return
*/
boolean cutAble() default false;
}模块的具体例子:
@Module(moduleKey = "scm.wms", moduleName = "WMS", parentModule = NULL)
public class WmsModule {
//业务逻辑
}
@Module(moduleKey = "scm.wms.inner.test1", moduleName = "测试模块1", parentModule = WmsModule.class)
public class InnerTestModule1 {
//业务逻辑
}
@Module(moduleKey = "scm.wms.inner.test2", moduleName = "测试模块2", parentModule = WmsModule.class)
public class InnerTestModule2 {
//业务逻辑
}4.2.2 模块树
每个模块都有父模块ParentModule,跟模块的父模块为NULL,模块树则是由所有模块组成的一个树状结构的树。

4.2.3 裁剪与恢复

4.2.4 模块配置
找到模块上的配置,点击展开配置。

展开配置如下:

上面的配置,是无需前端进行开发,只需要后端实现就好,后端代码:
@Data
@ModuleConfig(configKey = "scm.wms.inbound.receive.oneBarcodeMuliSku", configName = "收货一码多品配置", module="scm.wms.inbound.receive")
public class ReceiveScanOneCodeMoreSkuModuleConfig {
@ConfigItem(itemName = "是否开启一码多品的拦截"
, itemRemark = "如果关闭, 一码多品的商品在收货时, 不会收到\"该条码对应多个商品,请打印商品标签\"的提醒, prd:https://poizon.feishu.cn/wiki/wikcnstRj3Qfbn4fXDrmvBk6R0d"
, defaultValue = "true")
private Boolean isOpen;
@ConfigItem(itemName = "拦截方式"
, itemRemark = "如果配置强拦截,则必须打印商品标签, 阻断收货流程。如果配置弱拦截, 只是提醒一下, 不阻断收货流程"
, scopeClass = InterceptType.class
, defaultValue = "WEAK")
private String interceptType;
@ConfigItem(itemName = "拦截规则"
, scopeClass = InterceptRuleType.class
, defaultValue = "ARBITRARY")
private String interceptRule;
}配置的几个java注解:
1. ModuleConfig
/**
* 业务配置注解,业务配置是Module的字段
*/
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ModuleConfig {
/**
* 配置的key
*/
String configKey();
/**
* 配置名称
* @return
*/
String configName();
/**
* 配置描述,鼠标悬浮时的气泡提示
* @return
*/
String configRemark() default "";
/**
* 是否必要,必要的不可以被剪枝
* @return
*/
boolean cutAble() default false;
}
2.ConfigItem 配置属性
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ConfigItem {
/**
* 配置名称
* @return
*/
String itemName();
/**
* 配置描述,鼠标悬浮时的气泡提示
* @return
*/
String itemRemark() default "";
/**
* 默认值
* @return
*/
String defaultValue() default "";
/**
* 如果你的取值范围是枚举指定枚举的全路径类名,
* 如果你的取值范围是一种策略,指定策略的interfaces的全路径名称
* @return
*/
Class<?> scopeClass() default Void.class;
/**
* 范围,默认通用,当你需要定制时才需要指定
* @return
*/
ScopeType scopeType() default ScopeType.COMMON;
/**
* 自定义组件,需要前端参与开发,非特殊组件,无需设置,DSK会自动给你寻找组件
* @return
*/
String customScopeType() default "";
/**
* 对位文本类型的配置,min则为文本长度限制的最小值
* 对于数字类型的配置,min则为数字的最小值。
*/
int min() default Integer.MIN_VALUE;
/**
* 对位文本类型的配置,min则为文本长度限制的最大值
* 对于数字类型的配置,min则为数字的最大值。
*/
int max() default Integer.MAX_VALUE;
}5.MTDD与TMF的差别
5.1 什么是TMF
TMF 是 Trade Modularization Framework 的全称,即交易模块化框架,最初是交易系统中的一个代码模块,后来剔除业务耦合部分,独立出来成为一个实现业务与平台分离的业务框架。
5.2 TMF架构

(图片来源:https://www.cnblogs.com/shoshana-kong/p/14957739.html)
5.3 TMF2在架构设计上主要的思想
- 业务包与平台分离的插件化架构:平台提供插件包注册机制,实现业务方插件包在运行期的注册。业务代码只允许存在于插件包中,与平台代码严格分离。业务包的代码配置库也与平台的代码库分离,通过二方包的方式,提供给容器加载。
- 全链路统一的业务身份:平台需要能有按“业务身份”进行业务与业务之间逻辑隔离的能力,而不是传统SPI架构不区分业务身份,简单过滤的方式。如何设计这个业务身份,也成为业务间隔离架构的关键。
- 管理域与运行域分离:业务逻辑不能依靠运行期动态计算,要能在静态期进行定义并可视化呈现。业务定义中出现的规则叠加冲突,也在静态器进行冲突决策。在运行期,严格按照静态器定义的业务规则、冲突决策策略执行。

(图片来源:https://www.infoq.cn/article/w3ztwqs9q4astbksd0mj)
5.4 MTDD VS TMF

6.MTDD 展望
6.1 将模块间的耦合度进行量化
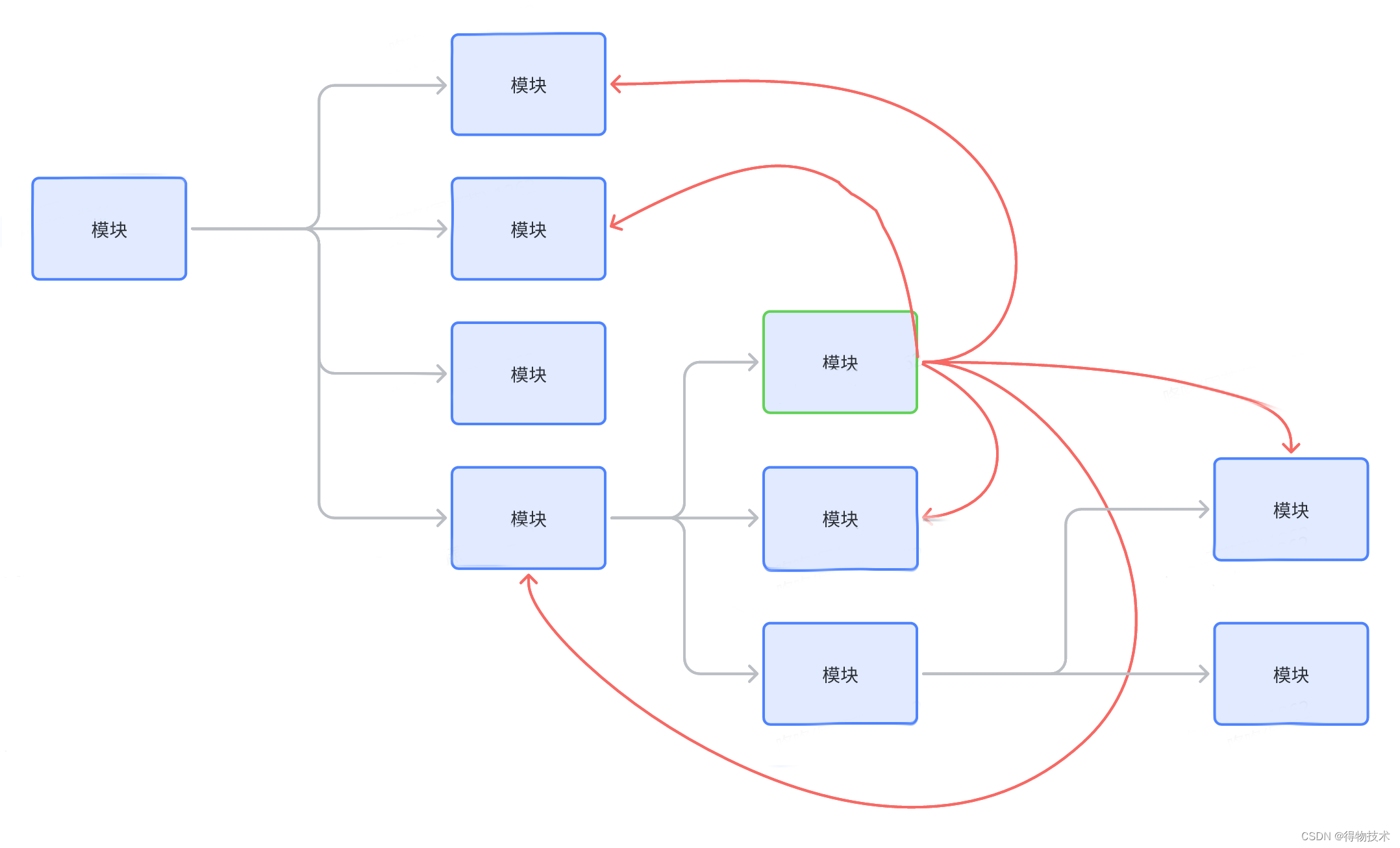
前面有提到“持续重构”这个概念;但是持续重构提出来很容易,但是做起来,就没有这么简单;
What:首先是如何发现需要重构的点,为什么是这个点要重构,而不是那个点要重构。
When:其实是什么时候需要进行重构。
为了更好的回答上面两个问题,个人认为最重要的是能够量化两个模块的复杂度。
6.2 将模块间的耦合度进行可视化
*文/阿福德
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!

![[代码案例] 快速入手matlab绘图基本指令](https://img-blog.csdnimg.cn/fa9fb91c64ca4a73b8502745a2e16a17.png)