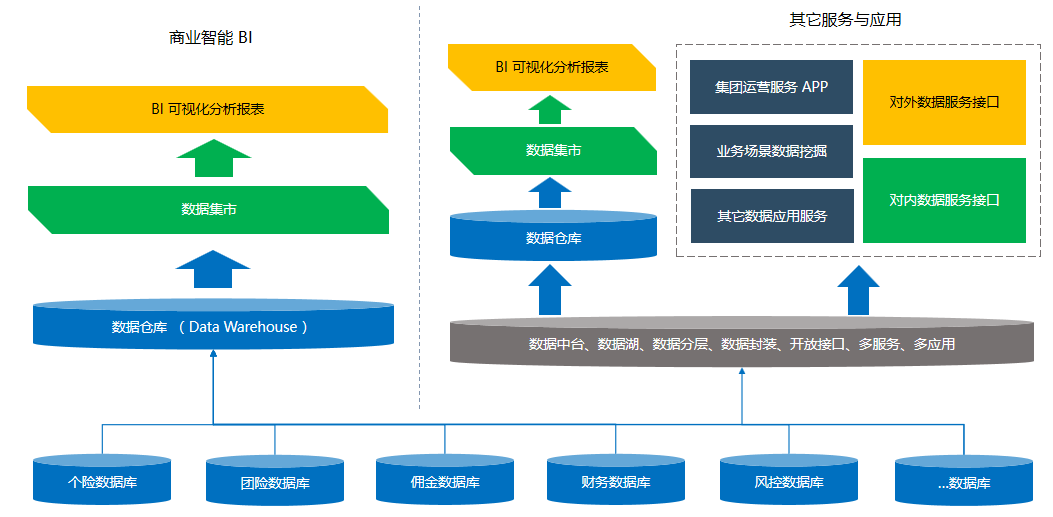
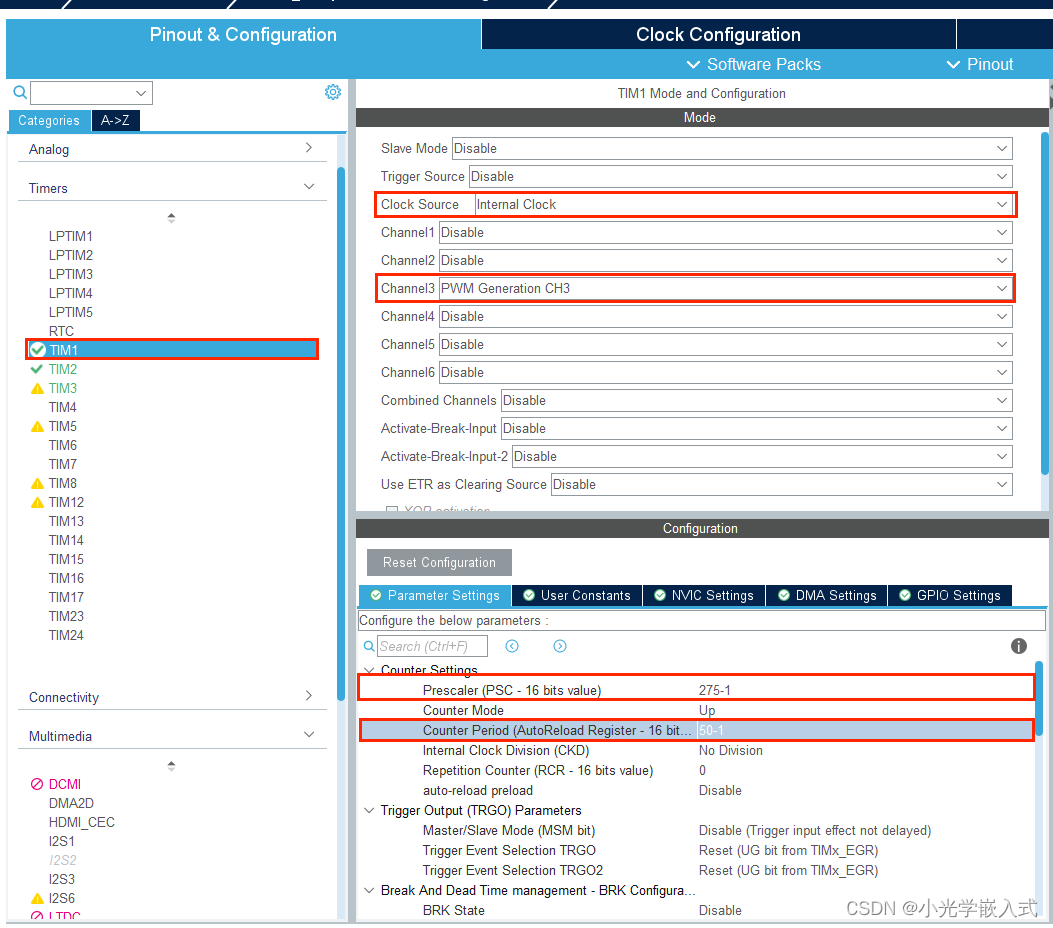
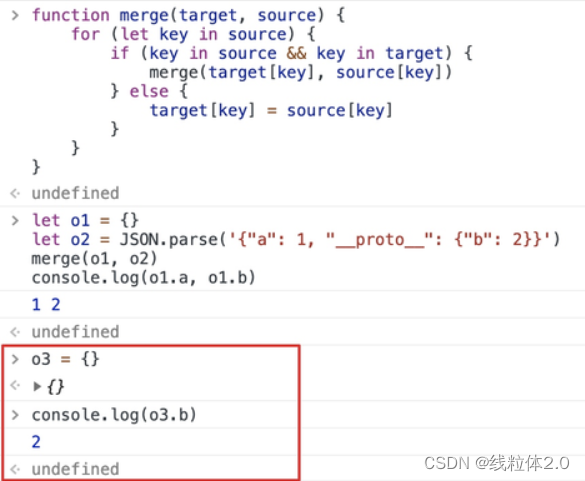
摘要
近年来,在资源有限的边缘设备上高效部署和加速功能强大的视觉变压器(ViTs)已成为一个很有吸引力的任务。虽然早期退出是加速推理的一个可行的解决方案,但大多数工作都集中在自然语言处理(NLP)中的卷积神经网络(CNNs)和transformer模型上。此外,将早期退出方法直接应用于vit可能会导致性能的性能下降。为了解决这一挑战,我们系统地研究了ViTs早期退出的有效性,并指出浅层内部分类器的特征表示不足和深度内部分类器中捕获目标语义信息的能力有限限制了这些方法的性能。然后,我们提出了一个早期的通用vit框架,称为LGViT,它包含异构退出头,即局部感知头和全局聚合头,以实现效率-准确性的权衡。特别是,我们开发了一种新的两阶段训练方案,包括端到端训练和冻结主干的自蒸馏,以生成早期退出的vit,这有利于两种头部提取的全局和局部信息的融合。我们在三个视觉数据集上使用三个流行的ViT骨干进行了广泛的实验。结果表明,我们的LGViT可以实现大约1.8×的加速竞争性能。
介绍
在过去的几年中,视觉变压器(ViTs)由于其强大的性能和通用的结构而成为各种多媒体任务的基本骨干。随着5G无线网络和物人工智能(AIoT)的发展,在资源有限的边缘设备上部署ViTs以实现实时多媒体应用已成为一个有吸引力的前景。然而,vit的高计算复杂度给将其部署在边缘设备上带来了重大挑战。例如,ViT-L/16 [26],一种典型的计算机视觉ViT架构,需要超过180gga的片段进行推理,在NVIDIA Jetson TX2设备上需要56.79毫秒来对224×224分辨率的图像进行分类。考虑到性能和服务质量(QoS)对实时多媒体系统至关重要,在资源受限的边缘设备上部署这种延迟-贪婪的vit是一项具有挑战性的任务。
一旦内部分类器的预测满足一定的标准,退出就通过终止前向传播来加速神经网络的推理提供了一个可行的解决方案。虽然在NLP中对神经网络和变压器模型进行了广泛的研究,但它在ViTs中的应用仍然是一个开放的问题。为ViTs开发一个有效的早期退出框架的主要挑战可以浓缩为三个关键方面。首先,直接在vit上应用早期退出策略会导致显著的性能下降。然而,目前还没有关于是什么限制了性能的系统调查。其次,最小化精度下降,进一步加速边缘设备上早期退出vit的推断是一个挑战。最后,在训练阶段,内部分类器从最终分类器中丢失大量信息,导致性能不佳。
关于第一个挑战,Kaya等人发现cnn可以在最后一层之前达到正确的预测,他们引入了内部分类器来缓解过度思考的问题。Sajjad等人研究了transformer模型中 dropping layers的影响,发现较低的层对任务性能更为重要。然而,他们的分析仅限于cnn或变压器模型,并没有考虑到ViTs中早期退出方法的限制。关于第二个挑战,一系列的研究引入了现有的标准来确定何时终止正向传播或设计先进的主干网络来平衡性能和效率。尽管Bakhtiarnia等人提出了一个早期的退出框架,通过合并额外的主干块作为退出的头部,但这些方法与移动平台和边缘平台施加的限制之间仍然存在相当大的加速差距。设计高效的退出头有利于构建具有丰富特征表示的早期退出头。关于第三个挑战,基于蒸馏的方法提供了一个很有前途的解决方案来帮助内部分类器模仿最终的分类器。然而,这些方法只适用于相同的早期退出的头部架构。
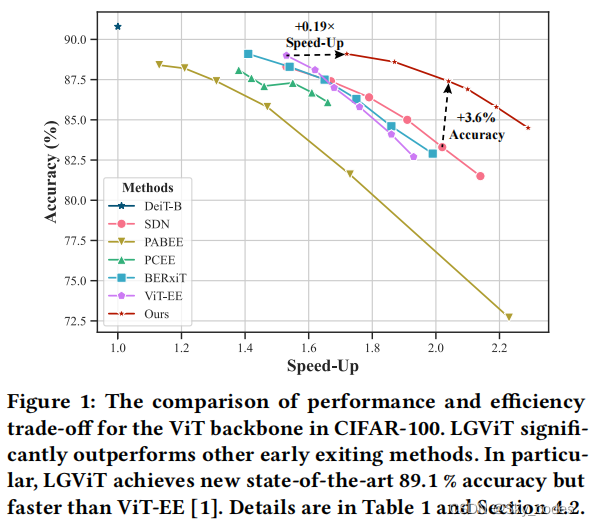
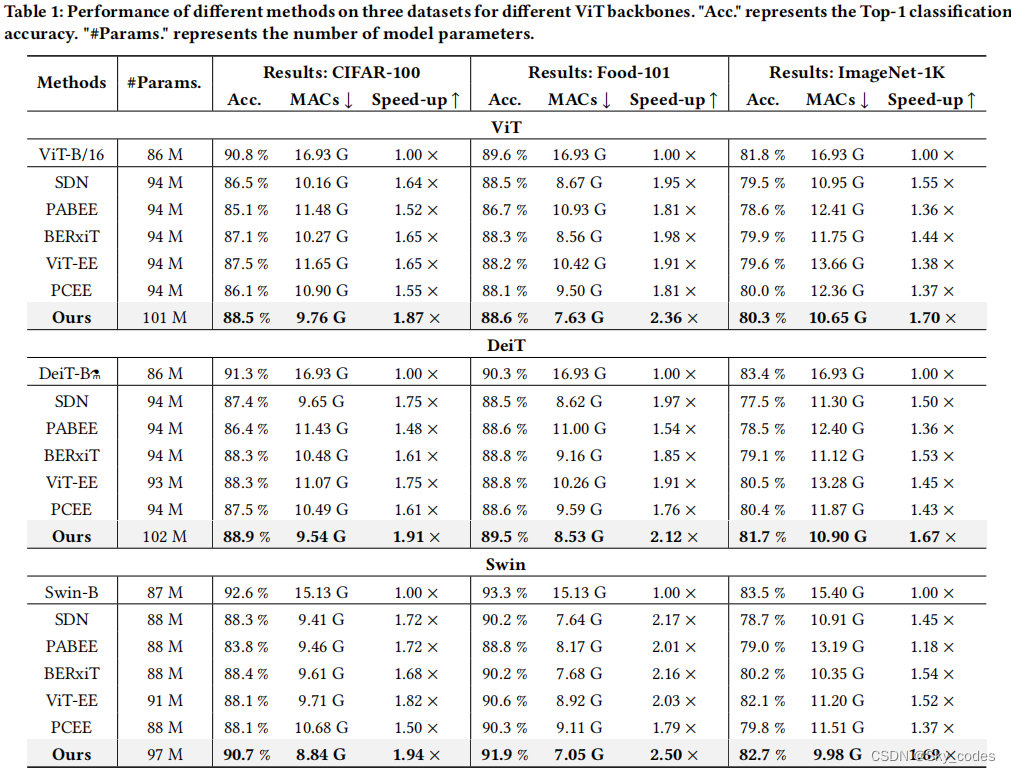
为了弥补这些限制,我们首先进行了探测实验,以检验早期退出方法在vit中的直接应用。我们发现,早期退出的性能受到以下因素的限制: i)浅层内部分类器中的特征表示不足;ii)在深度内部分类器中捕获目标语义信息的能力较弱。在这些见解的基础上,我们提出了一个有效的通用vit的早期退出框架,称为LGViT,它在加速推理的同时保持几乎相同的准确性。在LGViT中,我们结合了异构的退出头,特别是局部感知头和全局聚合头,来生成早期退出的ViT网络。将局部感知头附着在浅层的退出点上,以捕获局部信息并学习足够的特征表示。相反,将全局聚合头连接到深度退出点来提取全局信息,从而增强了对目标语义特征的捕获。据我们所知,这是第一个使用异构退出头部的早期退出vit的工作。随后,我们提出了一种新的两阶段训练策略的早期退出ViTs。在第一阶段,我们利用端到端方法来帮助骨干ViT实现其全部潜力。在第二阶段,我们冻结了主干的参数,并只更新了退出的头部。采用退出头之间的自蒸馏法来减少信息损失。最后,我们进行了大量的实验,以验证我们提出的框架在加速ViT推理方面的优越性,在三个数据集上实现了三个ViT骨干的良好的效率-精度权衡。例如,如图1所示,当ViT作为主干时,我们的方法可以加速推理1.72×,而对CIFAR-100数据集的准确率仅下降1.7 %。
我们的主要贡献总结如下:
- 我们对早期退出的有效性进行了系统的调查,并分析了香草早期退出所产生的问题。
- 我们提出了一个有效的早期退出框架,称为LGViT的一般ViT,结合异质退出头,即局部感知头和全局聚合头,以实现效率-准确性的权衡。
- 我们开发了一种新的两阶段训练策略,促进多个异构的头部学习和显著最小化信息损失。
- 我们在三个广泛使用的数据集和具有代表性的ViT骨干上进行了广泛的实验,证明了我们提出的框架的优越性,它实现了1.8×的平均加速,而只牺牲了2%的精度。
相关工作
Efficient ViT
Early exiting strategy
早期退出是一种有效的动态推理范式,它允许内部分类器有足够自信的预测提前退出。最近对早期退出的研究大致可以分为两类: 1)架构设计。一些研究集中在设计先进的骨干网络来平衡性能和效率。例如,Teerapittayanon等人首先提出在dnn中附加不同深度的内部分类器,以加速推理。Wołczyk等人引入了级联连接,以增强内部分类器之间的信息流,并增强了来自多个内部分类器的聚合预测,以提高性能。这些方法几乎没有考虑到退出头部结构的设计,并且几乎所有的方法都使用了一个完全连接的层作为退出头部。 Bakhtiarnia等人建议将额外的主干块作为早期退出的分支插入ViT。2)、培训方案。另一种工作方法是设计训练方案来提高内部分类器的性能。Liu等人的使用自蒸馏来帮助内部分类器从最终的分类器中学习知识。Xin等人引入了一种交替训练方案,在奇数和偶数迭代的两个目标之间交替。
现有的高效ViT压缩方法主要是通过精心设计紧凑的ViT结构或应用模型压缩技术来压缩ViT。我们的方法采用样本级加速进行推理,基于每个出口预测的置信度动态调整不同路径上的输出。关于早期的退出策略,与本文最相关的工作是[1]中的CNN-Add-EE和ViT-EE,它们分别使用卷积层和变压器编码器作为退出头。然而,它们的性能并不令人满意,并且不能实现有效的推理。据我们所知,我们首先引入异构退出的头部来构建早期退出的vit,并实现效率-精度的权衡。在上述研究的基础上,我们还提出了一种新的两阶段训练方案来弥补异构架构之间的差距。
方法
在本节中,我们首先提供了所提出的LGViT框架的动机和概述。然后我们说明了异构退出头部和两阶段训练策略。最后,我们描述了在推理过程中所使用的退出策略。
Motivation
早期的现有方法可以过早地停止神经网络的正向传播,从而提供效率-精度的权衡,这在自然语言处理中实现了神经网络和变压器的显著性能改进。然而,天真地在ViT上实现早期退出可能不会为内部分类器产生性能提高。例如,与CIFAR-100上的ViT-B/16的原始分类器相比,内部分类器在第五层和第十层的性能分别下降了21.8%和4.0%。如图2所示,我们比较了DeiT-B在不同退出点的注意图(探测实验的详细描述见附录A.2)。深度分类器可以提取目标语义特征来识别对象。因此,我们得到了以下观察结果:
-
观察1:浅层的内部分类器不能学习到足够的特征表示。
-
观察2:深度内部分类器不能捕获目标语义信息。
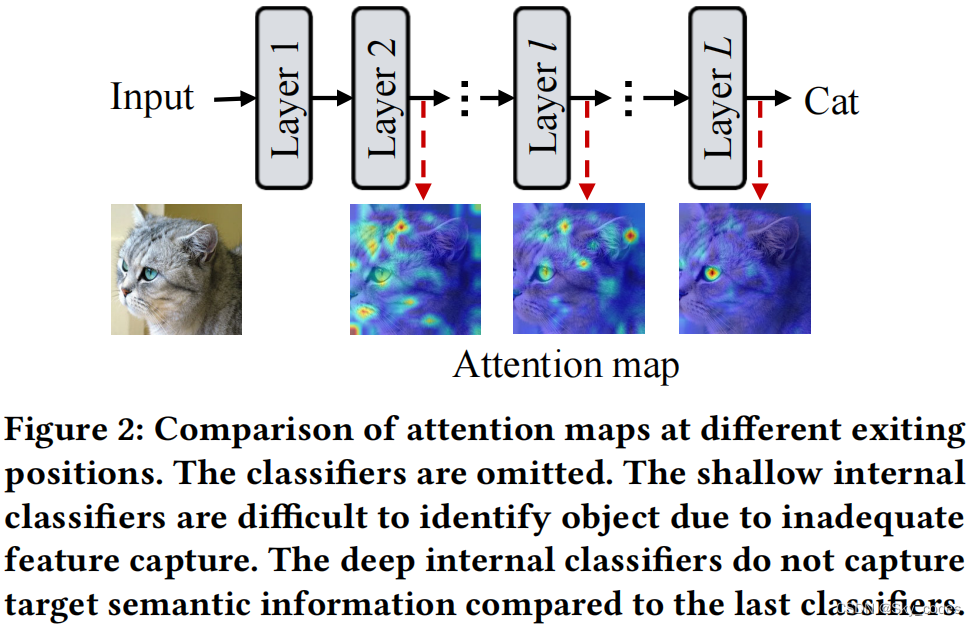
我们还发现,如果将卷积和自注意作为现有架构,分别位于浅层和深层,与普通的头架构相比,该模型将获得更全面的局部和全局信息组合。
Overview
基于上述观察结果,我们提出了一个针对vit的早期退出框架,该框架包含了异构的早期退出架构。图3描述了对所提议的框架的概述。它包括一个ViT主干、多个局部感知头和多个全局聚合头。最初,提供了一个由𝐿编码器块组成的ViT主干。我们向ViT的中间块中添加了𝑀的内部分类器。一般来说,𝑀要小于主干层的总数,因为在每层之后添加内部分类器会导致大量的计算成本。内部分类器的位置与主干层的编号无关。
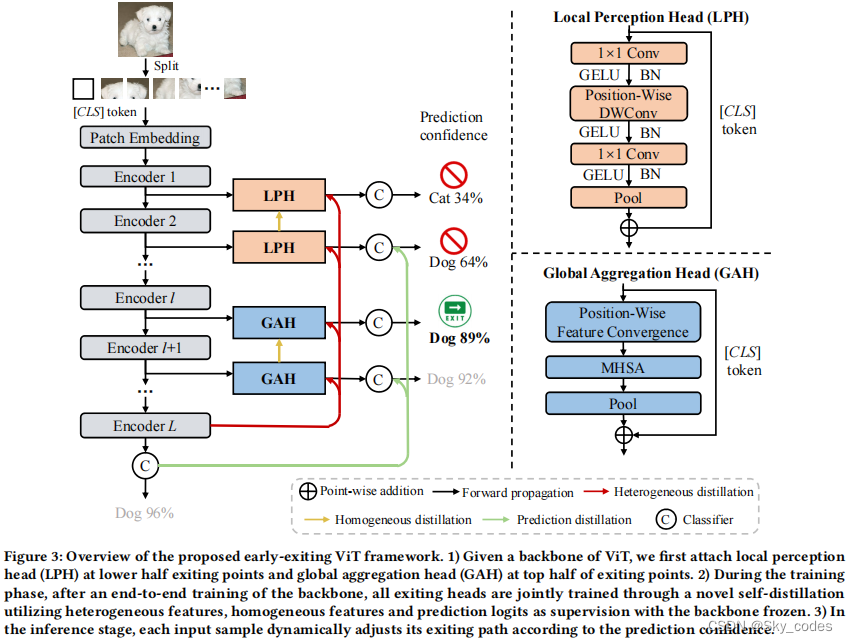
我们遵循一个三步的程序来构建早期退出的ViT框架:
- 附着异构的退出头:从ViT的主干开始,我们首先沿着其深度选择几个退出点。然后根据局部感知头和全局聚合头的位置放置在相应的退出点上。
- 两阶段训练:我们使用一种新的两阶段训练策略对整个早期退出的ViT进行训练,包括端到训练和骨干冻结的自蒸馏。这可以促进全局信息和本地信息的集成,以提高性能。
- 动态推理:当部署训练好的模型进行推理时,每个输入样本可以根据每个退出头部预测的置信度,在不同的深度动态地确定其输出。
Attaching Heterogeneous Exiting Heads
我们首先介绍了退出头部的位置,然后是对异构的退出头部的详细描述。在这项工作中,退出点的位置是根据一个近似等距的计算分布来确定的,即两个相邻点之间的中间块的乘法累加运算(MACs)保持一致。为了简单起见,退出点被限制为放置在单个编码器块的输出处。我们将基于卷积的局部感知头附加到退出点的下半部分,以增强局部信息的探索。基于自我关注的全球聚合头被整合到点的上半部分,以增强全球信息获取。
- Local perception head
如A.2节所分析的,直接在ViT中应用早期退出会导致浅层内部分类器的性能严重下降。为了缓解这一问题,我们引入了一个局部感知头(LPH)用于早期退出框架,它优雅地将卷积合并到ViT中,以增强特征表示学习。它可以实现有效的局部信息探索和有效的从原始主干中提取的特征集成。如图3右上角所示,提出的LPH首先使用1×1卷积层来扩展维度。随后,扩展的特征被传递到一个位置级深度卷积(PDConv)与𝑘×𝑘核大小,这取决于退出位置𝑚。为了减少计算开销,我们对更深的退出点采用较小的核尺寸卷积。我们使用一个递减的线性映射函数𝑓(·)来确定PDConv的核大小,即𝑘=𝑓(𝑚),𝑚≤𝐿/2。例如,在第𝑚个退出位置的扩展特征被传递给𝑘×𝑘深度卷积。请注意,𝑘=0意味着扩展的特性将绕过PDConv,直接进入后续部分。因此,PDConv可以表述为:
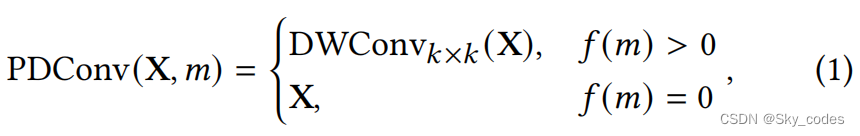
其中, D W C o n v k × k DWConv_{k×k} DWConvk×k表示与大小为𝑘×𝑘的核的深度卷积。然后使用1×1的卷积将特征投影回原始的补丁空间,然后传递到平均池化层。考虑到[𝐶𝐿𝑆]标记包含初始特征表示,因此将其添加到合并输出中,以促进来自原始主干的全局信息和来自卷积的局部信息的融合。具体地说,给定一个ViT编码器输出 X e n ∈ R N × D X_{en}∈R^{N×D} Xen∈RN×D,其中𝑁表示补丁的数量,𝐷表示隐藏的维度,当退出点的位置低于𝐿/2时,建议的退出头的输出为:
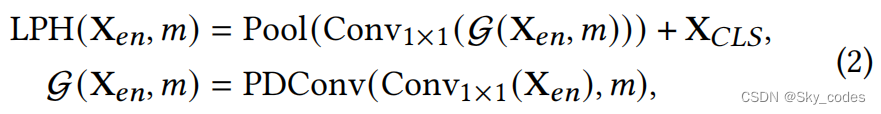
其中, X C L S X_{CLS} XCLS表示[𝐶𝐿𝑆]标记,并省略了激活层。每次卷积后均采用高斯误差线性单位(GELU)和批归一化(BN)。LPH的输出最终被传递给内部分类器。通过引入LPH作为现有的头部,浅层内部分类器可以学习足够的特征表示并捕获局部信息,从而提高视觉任务的性能。
- Global aggregation head
基于A.2节的讨论,将早期退出方法直接应用于ViT,阻碍了深度内部分类器中的语义信息捕获。我们提出了一个全局聚合头(GAH),并将其合并到深层退出点,如图3的右下方所示。该GAH集成了来自局部相邻标记的特征,然后计算每个子集的自注意,以促进目标语义信息的利用。在GAH中,我们首先使用一个位置级特征收敛(PFC)块来从退出点聚合特征。在PFC块中,输入特征 X ∈ R N × D X∈R^{N×D} X∈RN×D被重塑为𝐷×𝐻×𝑊维度,并以𝑠×𝑠窗口的大小进行降采样。采样特征 X s a m p l e ∈ R D × H / s × W / s X_{sample}∈R^{D×H/s×W/s} Xsample∈RD×H/s×W/s被恢复为原始尺寸格式 N / s 2 × D N/s^2×D N/s2×D。所提出的PFC块将输入特征重构为补丁格式,并使用𝑠×𝑠窗口对其进行降采样。然后将采样的特性恢复为原始格式。为了避免引入额外的可学习参数,我们使用了一个具有𝑠步幅的平均池作为PFC的实现。与PDConv类似,PFC的s窗口大小𝑠也取决于退出位置𝑚。更深的退出点利用更大的窗口大小,显著降低了计算成本。我们使用一个递增的线性映射函数𝑔(·)来确定PFC的窗口大小,即𝑠=𝑔(𝑚),𝐿/2<𝑚≤𝐿。例如,输入特征被传递到在第𝑚个退出点的大小为𝑔(𝑚)×𝑔(𝑚)窗口的子样本。请注意,最小窗口大小通常设置为2。因此,PFC可以表示为:
其中, p o o l g ( m ) pool_{g(m)} poolg(m)表示具有𝑔(𝑚)步幅的平均池。在方程中省略了特征的重塑和恢复操作。与原始MHSA相比,PFC不仅减少了计算冗余,而且有助于关注目标补丁。然后将集成的特征通过多头自注意(MHSA)和一个池层来传递。[𝐶𝐿𝑆]标记也被添加到合并的特性中。因此,当退出点的位置大于𝐿/2时,所提出的GAH可以表述为:
其中,输入X使用变换矩阵 W Q , W K W_Q,W_K WQ,WK和 W V W_V WV线性转换为查询、键和值向量;𝑑是向量维数。通过使用GAH作为退出头部,深度内部分类器可以减少自我注意的空间冗余,捕获更多的目标语义信息。
- Complexity analysis
为了彻底理解异构退出头的计算瓶颈,我们通过分析它们的浮点运算(MACs),将我们提出的LPH + GAH与标准卷积+ MHSA进行了比较。给定大小为𝑁×𝐷的输入特征,标准𝑘×𝑘卷积的流程为:
一个MHSA模块的流量可以计算为:
其中,省略了激活函数。为了进行公平的比较,我们在LPH中选择了相同的内核大小的𝑘。建议的两个退出头的流程如下:
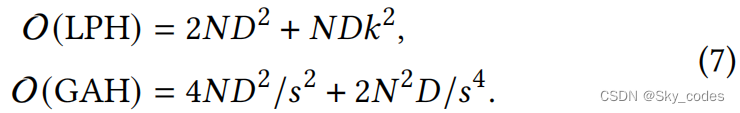
我们观察到LPH和GAH的计算复杂度分别低于标准卷积和MHSA。
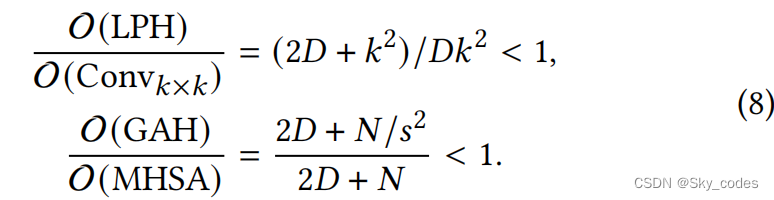
因此,与标准卷积和MHSA相比,我们提出的LPH和GAH头更适合计算成本,也更方便在硬件平台上实现。
Two-Stage Training Strategy
为了解决早期退出导致的性能下降问题,我们提出了一种新的两阶段训练策略,将知识从更深层次的分类器转移到浅层的分类器。两阶段训练策略的过程如下。
- 在第一阶段,我们训练主干ViT,并以交替策略更新主干和最终分类器的参数。因此,可以最小化多个内部分类器的干扰,使最终的分类器能够充分发挥其潜力。与一般的训练类似,我们利用交叉熵函数作为训练损失。
- 在第二阶段,主干和最终分类器保持冻结。只能更新退出的头和内部分类器的参数。我们引入了自蒸馏,以方便模仿最后一个分类器中所有退出的头部,如图3左侧所示。
整体蒸馏损失包括非均相蒸馏、均相蒸馏和预测蒸馏损失。
Heterogeneous distillation
考虑到异质退出头部的使用,不同类型的头部之间的差距是巨大的。直接利用最后一层的特征作为内部分类器的监督,会导致信息丢失。为了解决这个问题,我们提出了异构蒸馏,以促进从异构架构中学习知识。为了减少多重损失之间的冲突,我们只使用最后一层的特征作为LPH和GAH的第一个和最后一个退出头的参考特征。LPH捕获的归纳偏差和局部视觉表征可以与从自我注意中提取的全局信息优雅地集成。考虑到退出头部和最终块之间的特征映射的不同形状,我们使用了一个对齐模块来匹配维度。该模块由深度卷积、GELU和BN激活函数组成。最后一个ViT层F_𝐿∈R^{𝑁×𝐷}
的特征图首先被重塑为
的特征图首先被重塑为
的特征图首先被重塑为𝐷×√𝑁×√𝑁$尺寸。重塑后的特征图传递给模块以降维,然后恢复到原始尺寸格式𝑁’×𝐷。异质性的损失函数可以表示为:
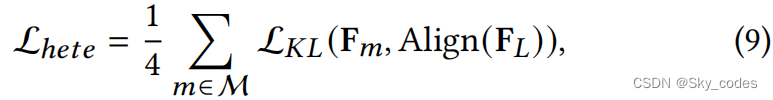
其中M = {1M/2M/2+1M}和 L K L L_{KL} LKL是Kullback-Leibler散度函数。
Homogeneous distillation
我们建议在具有相同架构的退出头之间进行均匀蒸馏,以进一步提高性能。在每一种类型的退出头部中,我们使用最后的头部作为教师助理,以帮助前面的同质头部学习提示知识。例如,在所有的LPHs中,最终的LPH的特征(即在𝑀/第2个退出点)被用作前面的LPH的参考特征。给定从第一个到第𝑚个退出头F𝑚的特征图(1≤𝑚≤𝑀/2),LPHs间均质蒸馏的损失函数为:
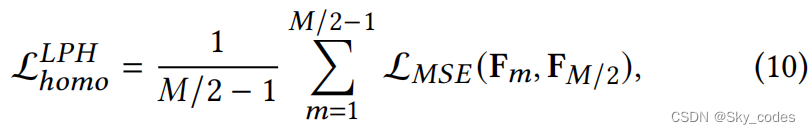
其中, L M S E L_{MSE} LMSE为均方误差函数。由于GAH的特征映射有不同的形状,我们在特征映射之间应用点积运算。给定GAH F m ∈ R N / g 2 ( m ) × D F_m∈R^{N/g^2(m)×D} Fm∈RN/g2(m)×D的特征图,通过计算 F m T F m F^T_mF_m FmTFm.可以将其形状转换为𝐷×𝐷均相蒸馏的损失函数可以表示为:
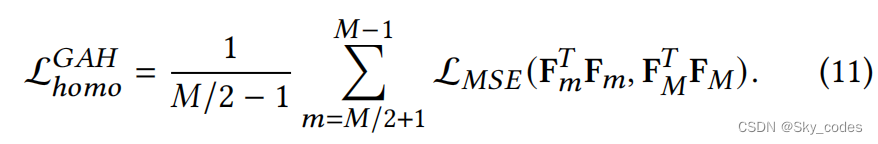
因此,均相蒸馏的整体损失函数可以表示为:
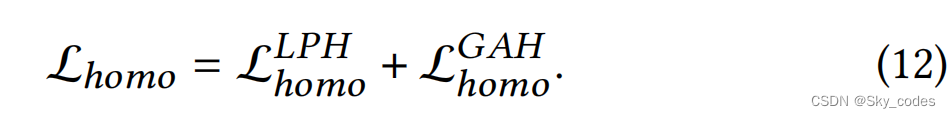
Prediction distillation
为了进一步提高内部分类器的性能,我们利用最终的分类器分别作为最后一个LPH和GAH所在的第𝑀/2个和第𝑀个退出点的参考标签。给定一个与标签𝑦相关的输入样本,并假设第𝑀/2个和第𝑀个退出点的预测分别为ˆ𝑦𝑀/2和ˆ𝑦𝑀,预测蒸馏的损失函数可以表述为:
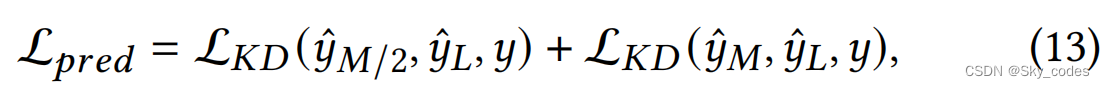
其中,L𝐾𝐷为香草知识精馏的损失函数:
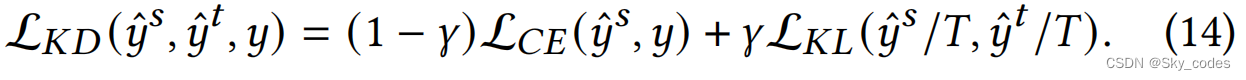
这里, L C E L_{CE} LCE是交叉熵函数,𝑇是控制对数平滑度的温度值,𝛾是一个平衡超参数。
因此,我们所提出的方法的总体损失函数为:
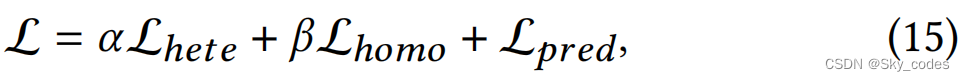
其中,𝛼和𝛽为超参数。
Dynamic Inference
在本节中,我们首先介绍退出的度量,然后描述早期退出的ViT推理的过程。我们使用之后的标准置信度量作为退出度量,它表示最自信的分类类的概率。在第𝑚个退出位置的预测置信度 c m c_m cm为:
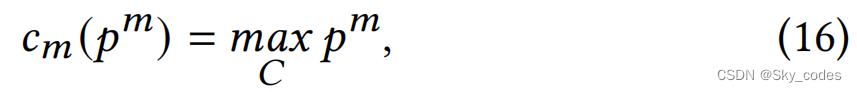
其中, p m p^m pm为第𝑚个退出位置的预测分布,𝐶为分类标签集。在推理过程中,输入样本会按顺序进行退出。每个样本根据退出的度量动态地调整其退出路径。如果一个样本在第𝑚个退出点的分类置信度超过了预定义的阈值𝜏,则将终止ViT的正向传播,并输出在第𝑚个退出点的预测。阈值𝜏可以根据计算成本和硬件资源进行调整,以实现效率-精度的权衡。一个较低的阈值可能导致显著的加速,但代价是准确性可能下降。如果从未达到退出条件,则ViT将恢复到标准推理过程。
实验
实验部分,有需要建议看原文
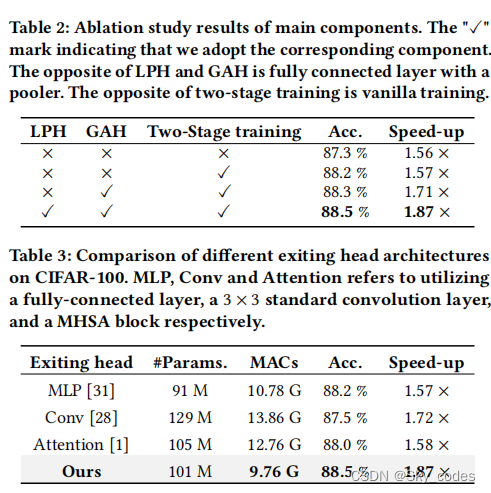
消融

总结
在本文中,我们指出,由于在浅层内部分类器中的特征表示不足,以及在深度内部分类器中捕获目标语义信息的能力有限,因此天真地在ViTs中应用早期退出会导致性能瓶颈。在此基础上,我们提出了一个早期的通用vit框架,该框架结合了异构退出头部来增强特征探索。我们还开发了一种新的两阶段训练策略,以减少异构退出头部之间的信息损失。我们在三个视觉数据集上对三个ViT骨干进行了广泛的实验,证明了我们的方法优于其他竞争的方法。我们的方法的局限性是手动选择了退出的位置和最优的退出路径。在未来,我们打算利用贝叶斯优化来自动执行最优的退出决策。
附录
作者在附录部分也添加了不少实验,有需要可以看看。