Pre-trained models for natural language processing: A survey(NLP领域预训练模型研究综述)_笔记
零、摘要
简洁的介绍了语言表征学习的研究进展,以及描述了如何将PTMs(pre-training models)应用于下游任务,并概述了未来的潜在发展方向。
一、前言
首先列出了常用的神经网络模型:CNN、RNN、GNN以及注意力机制,它们的优点是能够缓解特征工程问题。对比于非神经网络方法,缺点是严重依赖于离散的手工特征,而神经网络方法通常使用低维和密集的向量(又称 分布式表示)隐式地表示语言的句法或语义特征。
由于深度神经网络通常包含大量的参数,但目前除了机器翻译,其他的大多数有监督的NLP任务的数据集都相当小,因此采用深度神经网络在这些小的训练数据上过拟合,在实践中不能很好地泛化。许多NLP任务的早期神经模型为了解决这一问题都设计的相对较浅,通常只包含1-3个神经层。这个问题也导致了近些年与计算机视觉(CV)领域相比,神经网络模型在NLP领域性能的提高可能不太显著。
引出预训练模型,随着深度神经网络模型的发展,以及计算机算力的提高很多模型在设计上从浅变深(例如transformer),第一代预训练模型:skip-gram,glove,目的是学习好的单词嵌入,尽管这些预先训练的嵌入可以捕获单词的语义,但它们与上下文无关,无法捕获上下文中的更高级别概念,如多义词消歧、句法结构、语义角色、回指;第二代预训练模型针对于上下文单词嵌入,例如:CoVe , ELMo OpenAI GPT and BERT. 下游任务需要这些学习过的编码器来表示上下文中的单词。针对不同的任务,使用不同的预训练任务来学习PTMs。
这篇文献的工作:
(1)全面审查。为NLP提供了PTMs的全面回顾,包括背景知识、模型架构、训练前任务、各种扩展、适应方法和应用。
(2)新分类法。提出了一种面向自然语言处理的ptm分类法,从四个不同的角度对现有的ptm进行分类:1)表示类型;2)模型架构;3)训练前任务类型;4)特定场景类型的扩展。
(3)资源丰富。收集了大量关于ptm的资源,包括ptm的开源实现、可视化工具、语料库和论文列表。
(4)未来的发展方向。讨论和分析了现有的ptm的局限性。并提出了未来可能的研究方向。
二、背景
2.1 语言表征学习
一个好的语言表征并不是局限于特殊的任务而是通用的,对于语言理解,一个好的表征应该能够捕获隐藏在文本数据中的潜在语言规则和常用知识。例如:词汇意义,句法结构,语义角色,甚至语用。
通用的神经网络体系架构包括两种常见的单词嵌入:无上下文和上下文单词嵌入。区别是一个词的嵌入与否根据它出现的上下文动态变化。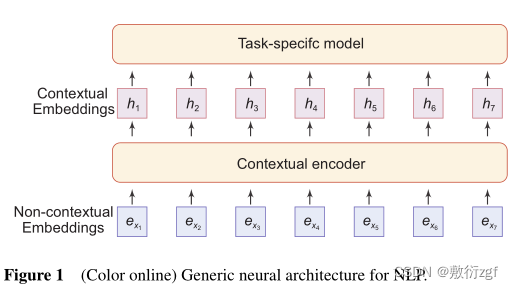
(1)无上下文嵌入
表示语言的第一步是将离散的语言符号映射到分布式的嵌入空间中。两个缺点:第一个问题是嵌入是静态的。不管上下文如何,单词的嵌入总是相同的。因此,句法-语境嵌入无法对多义词进行建模。第二个问题是词汇量不足问题。为了解决这个问题,字符级词表示或子词表示在许多NLP任务中被广泛使用,例如CharCNN、FastText、Byte-Pair Encoding(BPE)。
(2)上下文嵌入
为了解决多义词和词的上下文依赖性问题,需要区分词在不同上下文中的语义.
2.2 神经上下文编码
大多数神经上下文编码器可以分为两类:序列模型和非序列模型。

(1)序列模型
卷积模型:
卷积模型将单词嵌入到输入句子中,并通过卷积操作聚合来自相邻单词的局部信息来获取单词的含义
循环模型:
循环模型捕获记忆时间短的单词的上下文表示,例如LSTMs和GRUs
在实践中,双向lstm或gru用于从单词的两端收集信息,但其性能经常受到长期依赖问题的影响。
(2)非序列模型
非序列模型使用预定义的词之间的树或图结构学习上下文表示,如句法结构或语义关系。一些流行的非序列模型包括循环神经网络、TreeLSTM和GCN。虽然语言感知的图结构可以提供有用的归纳偏差,但如何构建良好的图结构也是一个具有挑战性的问题。此外,该结构在很大程度上依赖于专家知识或外部NLP工具,如依赖解析器。
Fully-connected self-attention model:全连接 自注意力模型
在实践中,更直接的方法是使用一个全连通图来建模每两个单词的关系,让模型自己学习结构。通常情况下,连接权重是通过自注意机制动态计算的,它隐式地表示了词与词之间的连接。全连接自注意模型的一个成功实例是Transformer,它还需要其他补充模块,如位置嵌入、归一化层、残差连接和前馈神经网络(FFN)层。
(3) Analysis
序列模型学习单词的上下文表示具有局部偏差,很难捕捉单词之间的远程交互。尽管如此,序列模型通常很容易训练,并在各种NLP任务中获得良好的结果。
相比之下,Transformer作为一个实例化的全连接自注意模型,可以直接建模序列中每两个词之间的依赖关系,功能更强大,适合建模语言的长期依赖关系。然而,由于Transformer结构沉重且模型偏差较小,它通常需要较大的训练语料库,并且很容易在小型或中等规模的数据集上过拟合。目前,Transformer由于其强大的能力已经成为ptm的主流架构。
2.3 为什么要预训练
在如今的NP发展过程中,模型的参数越来越多,需要更大的数据集去训练模型,并且要防止过拟合。但对于构建大规模标签数据集和训练模型都是很大的挑战,尤其是语法和语义相关的任务来说,所耗费的成本非常巨大。
相比之下,构建大规模无标签语料库是相对容易的,可以先从这些语料库中学习好的表示,再将这些表示应用于下游任务。最近的研究表明,借助从大型无标签语料库中学习到的语义表示,在很多NLP任务中取得了明显的效果。
预训练的好处: 1.在庞大的文本语料库上进行预训练,可以学习通用语言表示,帮助完成下游任务;2.预训练提供了更好的模型初始化,这通常会导致更好的泛化性能,并加快对目标任务的收敛;3.预训练可以看作是避免小数据过拟合的一种正则化。
2.4 NLP的PTM简史
预训练一直是学习深度神经网络参数的有效策略,然后对下游任务进行微调。早在2006年,深度学习的突破就出现了贪婪的分层无监督预训练和监督微调。在计算机视觉中,在庞大的ImageNet语料库上预训练模型,然后针对不同的任务对更小的数据进行进一步的微调已经在实践中得到了应用。这比随机初始化好得多,因为模型学习一般的图像特征,然后可以在各种视觉任务中使用。在自然语言处理中,大型语料库上的PTMs也被证明有利于从浅词嵌入到深层神经模型的自然语言处理下游任务。
(1)First-generation PTMs: Pre-trained word embeddings 第一代PTMs,预训练单词嵌入 将单词表示为密集向量有着悠久的历史,在神经网络语言模型的先导工作中引入了“现代”词嵌入(NNLM)。参考文献表明,在未标记数据上嵌入预训练单词可以显著改善许多NLP任务。为了解决计算的复杂性,他们学习了使用成对排序任务的单词嵌入,而不是语言建模。他们的工作是第一次尝试从未标记的数据中获得对其他任务有用的通用单词嵌入。参考文献表明,不需要深度神经网络来构建良好的单词嵌入。他们提出了两种浅架构:连续词袋(CBOW)和skip-gram(SG)模型。尽管它们很简单,但它们仍然可以学习高质量的单词嵌入,以捕获单词之间潜在的语法和语义相似性。Word2vec是这些模型最流行的实现之一,它使预训练的词嵌入可用于NLP中的不同任务。此外,GloVe也是一种广泛使用的预训练词嵌入模型,它是通过从大型语料库中全局词-词共现统计来计算的。
尽管预训练的词嵌入在NLP任务中已被证明是有效的,但它们与上下文无关,而且大多是通过浅模型训练的。当用于下游任务时,整个模型的其余部分仍然需要从头学习。
在同一时期,许多研究者也尝试学习段落、句子或文档的嵌入,如段落向量、跳过思想向量、Context2Vec。与现代模型不同的是,这些句子嵌入模型试图将输入句子编码成一个固定维的向量表示,而不是每个标记的上下文表示。
(2)Second-generation PTMs: Pre-trained contextual encoders第二代PTMs:预先训练的上下文编码器
因为大多数NLP任务都超出了单词级别,所以在句子级别或更高级别预训练神经编码器是很自然的。神经编码器的输出向量也称为上下文词嵌入,因为它们表示依赖于上下文的词语义。
参考文献[34]提出了PTM用于NLP的第一个成功实例。他们用语言模型(LM)或序列自编码器初始化LSTMs,发现预训练可以提高LSTMs在许多文本分类任务中的训练和泛化能力。参考文献[5]使用LM预训练共享LSTM编码器,并在多任务学习(MTL)框架下对其进行微调。他们发现,预训练和微调可以进一步提高MTL在几种文本分类任务中的性能。参考文献[35]发现Seq2Seq模型可以通过无监督的预训练显著提高。用预先训练好的两种语言模型的权值初始化编码器和解码器的权值,然后用标记数据进行微调。除了使用LM预训练上下文编码器外,文献[13]还使用机器翻译(MT)从注意力序列到序列模型预训练深度LSTM编码器。经过预训练的编码器输出的上下文向量(CoVe)可以提高多种常见NLP任务的性能。由于这些前身PTM,现代PTM通常使用更大规模的语料库、更强大或更深的体系结构(例如,Transformer)和新的预训练任务进行训练。参考[14]预训练的2层LSTM编码器,具有双向语言模型(BiLM),包括向前LM和向后LM。经过预先训练的BiLM ELMo(语言模型嵌入)输出的上下文表示被证明可以在大量的NLP任务中带来很大的改进。文献[36]用字符级LM预训练的上下文字符串嵌入捕获单词含义。然而,这两个ptm通常用作特征提取器来生成上下文词嵌入,这些词嵌入被输入到下游任务的主模型中。它们的参数是固定的,主模型的其余参数仍然从头训练。ULMFiT(通用语言模型微调)[37]尝试微调预先训练的LM用于文本分类(TC),并在六个广泛使用的TC数据集上取得了最先进的结果。
ULMFiT主要分为三个阶段:(1)一般领域数据的LM预训练;(2)对目标数据进行LM微调;(3)在目标任务上进行微调。ULMFiT还研究了一些有效的微调策略,包括判别式微调,倾斜的三角形学习率和逐渐解冻。
最近,非常深入的ptm显示了它们在学习通用语言表示方面的强大能力:例如,OpenAI GPT(生成式预训练)[15]和BERT(双向编码器表示from Transformer)[16]。除了LM,提出了越来越多的自监督任务(见3.1节),以使PTMs从大规模的文本语料库中获取更多的知识。
三、PTMs概述
ptm之间的主要区别是上下文编码器的使用、训练前任务和目的。我们在第2.2节简要介绍了上下文编码器的体系结构。在本节中,我们将重点介绍训练前任务,并给出训练前任务的分类。
3.1 训练的任务
训练前的任务对于学习语言的普遍代表性是至关重要的。通常,这些训练前任务应该具有挑战性,并具有大量的训练数据。在本节中,我们将训练前任务总结为三类:监督学习、无监督学习和自监督学习。
(1)监督学习(Supervised learning,SL)是基于输入输出对组成的训练数据学习将输入映射到输出的函数;
(2)无监督学习(Unsupervised learning, UL)是指从未标记的数据中发现一些内在知识,如聚类、密度、潜在表示等;
(3)自监督学习(Self-Supervised learning,SSL)是监督学习和非监督学习的结合,SSL的学习范式与监督学习完全相同,但训练数据的标签是自动生成的。SSL的关键思想是以某种形式预测来自其他部分的输入的任何部分。例如,隐藏语言模型(MLM)是一个自监督的任务,它试图在给定其他单词的情况下预测句子中的隐藏单词。
在CV中,许多ptm在大型监督训练集(如ImageNet)上进行训练。
然而,在NLP中,大多数监督任务的数据集都不足以训练一个好的PTM。唯一的例外是机器翻译(MT)。WMT 2017是一个大型的MT数据集,包含了700多万对句子。此外,机器翻译是自然语言处理中最具挑战性的任务之一,预先训练过机器翻译的编码器可以使多种下游的自然语言处理任务受益。作为一个成功的PTM, CoVe[13]是一个预先训练MT任务的编码器,改进了各种常见的NLP任务:情绪分析(SST, IMDb),问题分类(TREC),蕴涵(SNLI)和问题回答(SQuAD)。
在本节中,我们将介绍一些在现有ptm中广泛使用的训练前任务。我们可以把这些任务看作是自我监督学习。表1还总结了它们的损失函数。
(1)语言模型LM
在自然语言处理中最常见的无监督任务是概率语言建模(LM),这是一个经典的概率密度估计问题。虽然LM是一个笼统的概念,但在实践中,LM通常特指自回归LM或单向LM。
给定文本序列x1:T = [x1,x2,…,xT],其联合概率p(x1:T)可以分解为

其中,x0是表示序列开始的特殊标记。
条件概率p(xt | x0:t-1)可以通过给定语言上下文x0:t-1的词汇表上的概率分布来建模。上下文x0:t-1由神经编码器fenc(·)建模,条件概率为
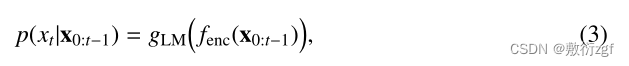
其中gLM(·)为预测层,在一个庞大的语料库中,我们可以用极大似然估计(MLE)来训练整个网络。单向LM的一个缺点是,每个标记的表示只编码左侧的上下文标记及其本身。然而,更好的文本上下文表示应该从两个方向编码上下文信息。一种改进的解决方案是双向LM (BiLM),它由两个单向LM组成:一个向前的从左到右LM和一个向后的从右到左LM。对于BiLM,。文献[38]提出了前向操作左向右LM,后向操作右向左LM的双塔模型。

结论
作者对NLP的PTMs进行了全面的概述,包括背景知识、模型架构、培训前任务、各种扩展、适应方法、相关资源和应用。基于现有的ptm,作者从四个不同的角度提出了一种新的ptm分类法,还提出了几个未来可能的研究方向。