ALIGN: A Large-scale ImaGe and Noisy-text embedding
目录
🍭🍭1.网络介绍
🍭🍭2.大规模噪声图像文本数据集
🐸🐸2.1图像过滤器
🐸🐸2.2文本过滤器
🍭🍭3.预训练和迁移任务
🐸🐸3.1噪声数据预训练
🐸🐸3.2图文匹配
🐸🐸3.3视觉分类
🐸🐸3.4仅带图像编码的视觉分类
🍭🍭4.消融实验
🐸🐸4.1网络结构
🐸🐸4.2超参数
🐸🐸4.3不同数据集
🐸🐸4.4权衡数据数量和数据质量
🍭🍭5.效果展示
🐸🐸5.1图像检索
🐸🐸5.2图像和文本输入检索图像
整理不易,欢迎一键三连!!!
摘要:预训练的表征对于许多NLP和感知任务变得至关重要。虽然NLP中的表示学习已经过渡到在没有人工注释的情况下对原始文本进行训练,但视觉和视觉语言表示仍然严重依赖于昂贵或需要专家知识的精心策划的训练数据集。对于视觉应用程序,表示大多是使用具有明确类标签的数据集(如ImageNet或OpenImages)来学习的。对于视觉语言,像概念字幕、MSCOCO或CLIP这样的流行数据集都涉及到一个非琐碎的数据收集(和清理)过程。这种代价高昂的管理过程限制了数据集的大小,因此阻碍了训练模型的扩展。在本文中,我们利用了一个由超过10亿个图像-文本对组成的噪声数据集,该数据集在概念字幕数据集中无需昂贵的过滤或后处理步骤即可获得。一个简单的双编码器架构学习对齐图像的视觉和语言表示
🍭🍭1.网络介绍
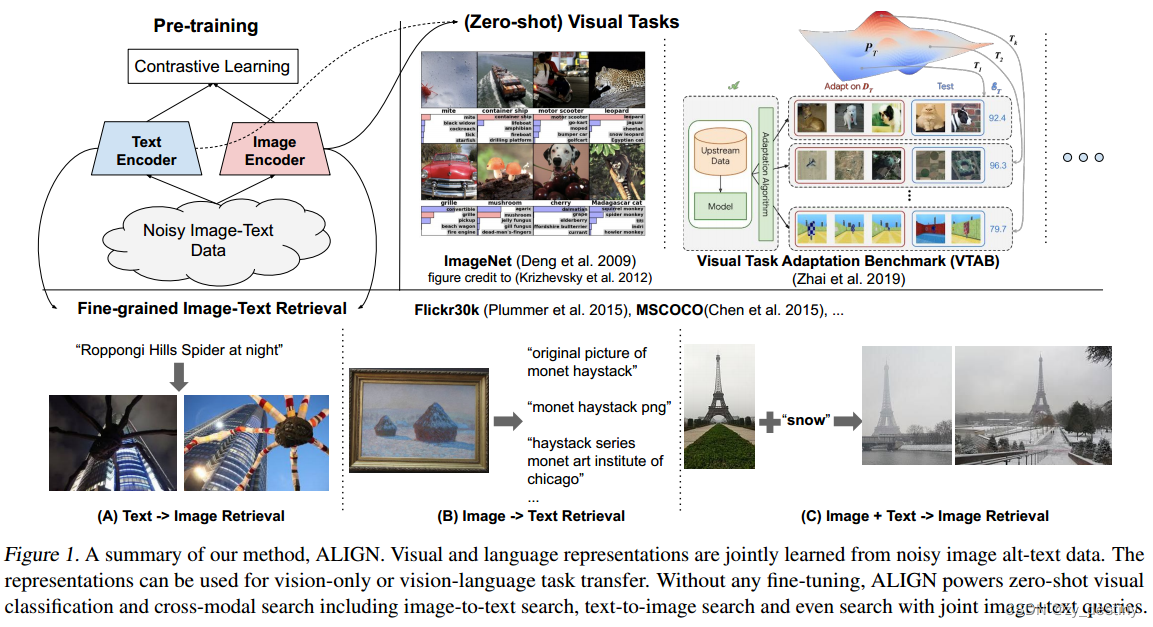
如左上角示意图所示,图像和文本编码器通过对比损失来进行学习,将互相匹配的文本-图像对嵌入到一起,将不匹配的分开,将配对文本视为图像的细粒度标签,我们的图像与文本对比损失类似于传统的基于标签的分类目标;关键区别在于文本编码器生成“标签”权重。
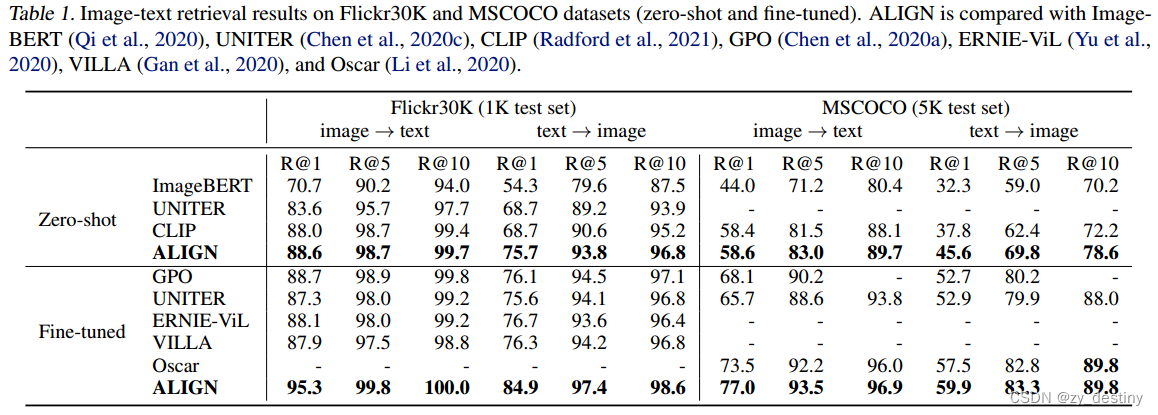
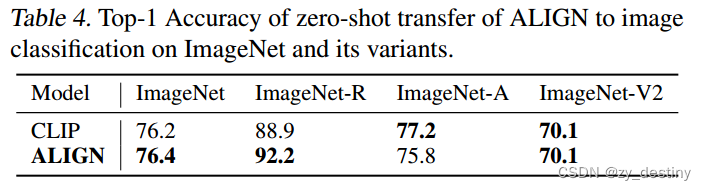
对齐的图像和文本表示自然适合于跨模态匹配/检索任务,并在相应的基准中实现最先进的(SOTA)结果。例如,在大多数零样本和微调中,ALIGN比以前的SOTA方法好7%以上R@1Flickr30K和MSCOCO中的度量。此外,当将classname输入文本编码器时,这种跨模态匹配自然能够实现零样本图像分类,在不使用任何训练样本的情况下,在ImageNet中实现76.4%的top-1精度。图像表示本身在各种下游视觉任务中也实现了卓越的性能。例如,ALIGN在ImageNet中达到了88.64%的top-1精度。图1-底部(a)-(c)显示了来自ALIGN构建的真实检索系统的跨模态检索示例。
- 输入文本——输出图像检索
- 输入图像——输出文本检索
- 输入图像+文本 ——输出图像检索
🍭🍭2.大规模噪声图像文本数据集
我们的工作重点是扩大视觉和视觉语言表征学习。为此,我们采用了比现有数据集大得多的数据集。具体来说,我们遵循构建概念字幕数据集的方法来获得原始英语文本数据的版本(图像和文本对)。在这里,为了达到缩放的目的,我们通过放松原作中的大部分清洁步骤,以质量换取大规模。相反,我们只应用基于最小频率的过滤器,如下所述。结果是一个更大(1.8B的图像-文本对)但噪声更大的数据集。图2显示了数据集中的一些示例图像-文本对。

🐸🐸2.1图像过滤器
基于图像的过滤。继Sharma等人(2018)之后,我们删除了色情图像,只保留短边大于200像素和纵横比小于3的图像,我删除了超过1000个相关文本的图像。为了确保我们不会在测试图像上进行训练,我们还删除了所有与下游评估数据集中重复或接近重复的测试图像
🐸🐸2.2文本过滤器
基于文本的筛选。我们删除了10张以上图片共享的文本。这些文本通常与图像的内容无关(例如,“1920x1080”、“alt-img”和“cristina”)。我们还丢弃了包含任何罕见标记的文本(原始数据集中1亿个最频繁的unigram和bigram之外),以及那些太短(<3个unigram)或太长(>20个unigrams)的文本,这可以去除诸如“image tid 25&id mggqpuweqdpd&cache 0&lan code 0”之类的嘈杂文本,或者过于通用而无用的文本。
🍭🍭3.预训练和迁移任务
🐸🐸3.1噪声数据预训练
我们使用双编码器架构预训练ALIGN。该模型由一对图像和文本编码器组成,顶部具有余弦相似性组合函数。我们使用具有全局池化的EfficientNet(不训练分类头中的1x1 conv层)作为图像编码器,使用具有class token嵌入的BERT作为文本嵌入编码器(我们从训练数据集中生成100k个单词片词汇)。在BERT编码器的顶部添加了一个具有线性激活的完全连接层,以匹配图像的尺寸。图像和文本编码器都是从头开始训练的。
图像和文本编码器通过归一化softmax损失进行优化。在训练中,我们将匹配的图像-文本对视为正样本,将批训练中可以形成的所有其他随机图像-文本配对视为负样本,这一点跟CLIP等文章是相同的。
损失函数:

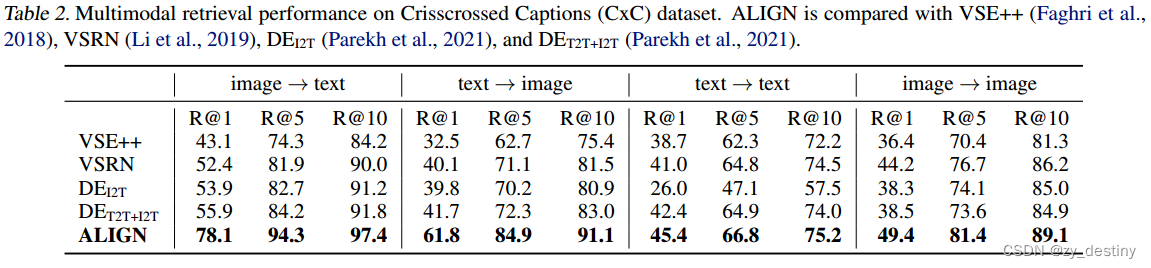
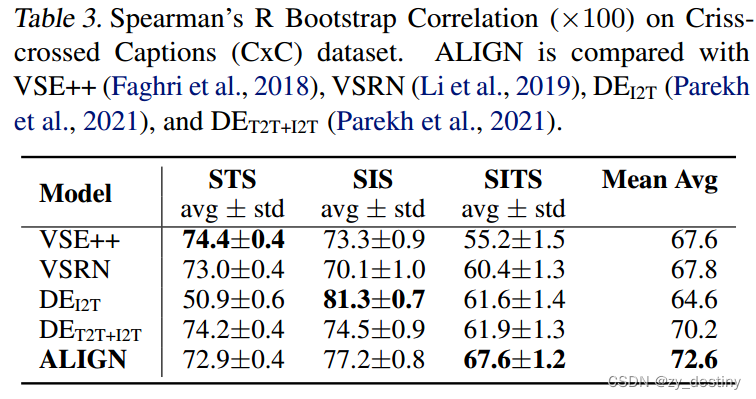
🐸🐸3.2图文匹配
🐸🐸3.3视觉分类
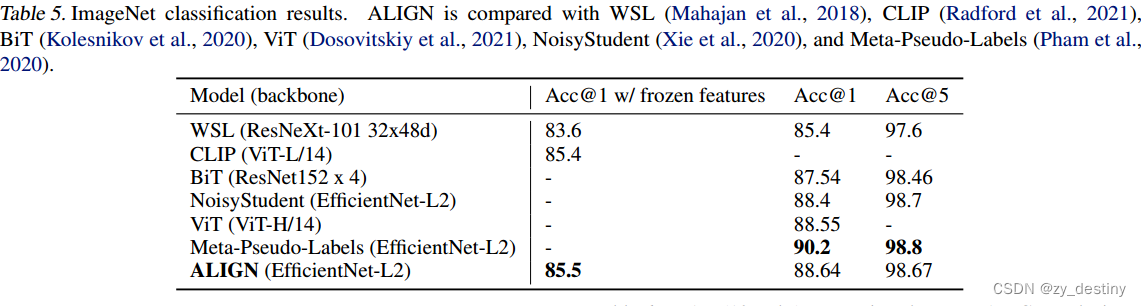
🐸🐸3.4仅带图像编码的视觉分类

表5将ALIGN与ImageNet基准测试上以前的方法进行了比较。在冻结功能的情况下,ALIGN略微优于CLIP,并实现了85.5%的SOTA结果,排名前1。经过微调后,ALIGN实现了比BiT和ViT模型更高的精度,并且只比元伪标签差,元伪标签需要在ImageNet训练和大规模未标记数据之间进行更深的交互。与同样使用EfficientNet-L2的NoisyStudent和Meta-Pseudeo标签相比,ALIGN通过使用较小的测试分辨率(600而不是800)节省了44%的FLOPS。
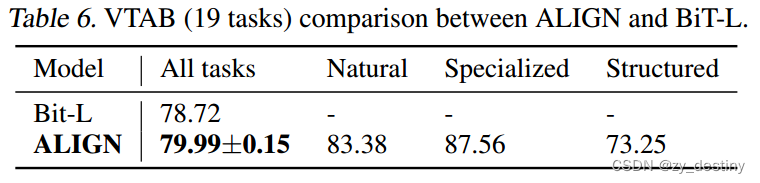
在VTAB评估中,我们遵循附录I中所示的超参数扫描,每个任务进行50次试验。每个任务在800个图像上进行训练,并且使用200个图像的验证集来选择超参数。
在扫描之后,所选择的超参数用于对每个任务的1000个图像的组合训练和验证分割进行训练。表6报告了三次微调运行的平均准确度(包括每个小组的分解结果)和标准偏差,并表明在应用类似的超参数选择方法的情况下,ALIGN优于BiT-L。
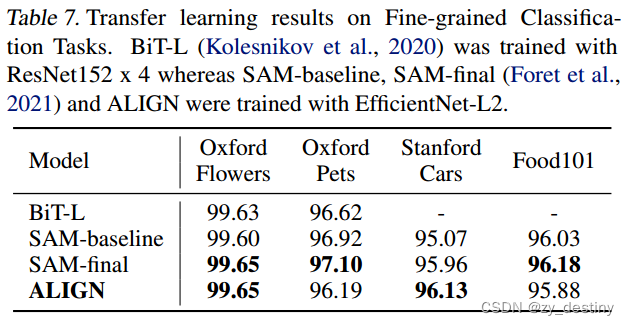
表7将ALIGN与BiT-L和SAM进行了比较,它们都对所有任务应用了相同的微调超参数。2对于这样的小任务,微调中的细节很重要。因此,我们列出了baseline结果,但没有使用SAM优化进行更公平的比较。在不调整优化算法的情况下,我们的结果(三次运行的平均值)与SOTA结果相当。
🍭🍭4.消融实验
🐸🐸4.1网络结构
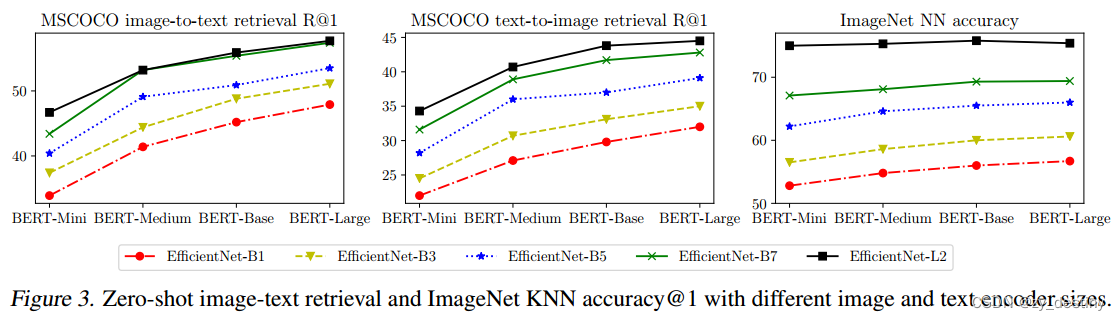
图3显示了图像和文本backbone的不同组合的MSCOCO零样本检索和ImageNet KNN结果。除了ImageNet KNN度量在EfficientNet-B7和EfficientNet-L2的情况下从BERT Base开始饱和到BERT Large之外,使用更大的backbone可以很好地提高模型质量。正如预期的那样,扩大图像编码器容量对于视觉任务更为重要(例如,即使使用BERT Mini文本塔,L2也比使用BERT Large的B7表现更好)。在图像文本检索任务中,图像和文本编码器的能力同样重要。基于图3所示的良好缩放特性,我们只使用EfficientNet-L2+BERT-Large对模型进行微调。
🐸🐸4.2超参数
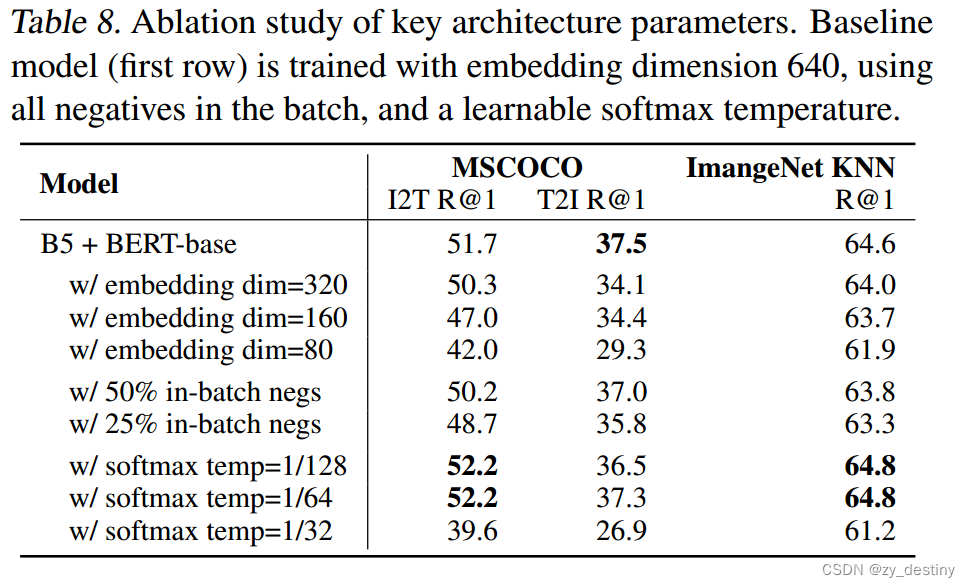
表8描述了关键的架构超参数,包括嵌入维度、批次中随机阴性的数量和softmax温度。表8将许多模型变体与使用以下设置训练的基线模型(第一行)进行了比较。
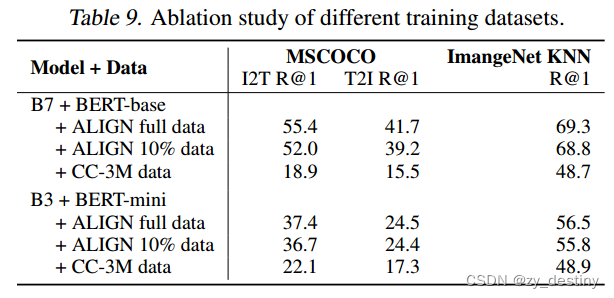
🐸🐸4.3不同数据集
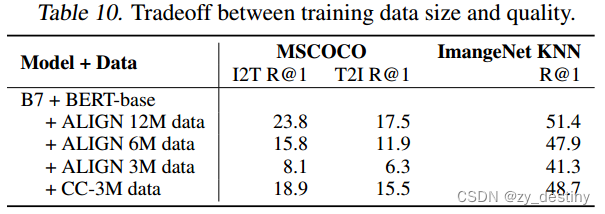
🐸🐸4.4权衡数据数量和数据质量
🍭🍭5.效果展示
🐸🐸5.1图像检索

🐸🐸5.2图像和文本输入检索图像


整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷