前言:目前国内的SAP相关的技术文档实在是少得可怜,PO相关的就更少了,基本上都是需要摸索,官方的技术专家很多时候的回复都是说了又似乎没说。。。
背景:由于目标系统接收数据缓慢或者是异步线程出现异常导致错误积压。
临时处理方案:
1.在SXI_MONITOR中查看异常报错的异步接口线程,全选之后重新启动;
2.在SMQ2入站队列中,对非running状态的队列进行激活或者解锁,保证队列的正常运作
3.对相关队列进行全局重置,参考note 2552322,下面为该note的部分内容:
RSQOWKEX 是用于重置出站队列条目的报告,以便出站队列调度程序可以处理队列。同样,RSQIWKEX 对应于入站 qRFC 场景。
创建出站 qRFC 时,首先调用调度器来处理此队列,队列的状态变为“正在运行”。
- 如果队列成功执行,将从 SMQ1(出站队列监控器)中消失,
- 如果未成功,队列将转到状态 SYSFAIL、RETRY、CPIERR 之一(请参阅 SAP Note 378903“SMQ1、SMQ2 中的队列状态和表 ARFCRSTATE”),其中详细解释了状态)。
此时,通过执行 RSQOWKEX 处理此队列,调度器将重试,如果之前的错误是临时的(例如,临时锁定),则此时队列将成功处理。
如果已调度报表 RSQOWKEX/RSQIWKEX,则调度器与报表之间可能会存在重复执行或死锁的情况,选择相同的条目。
如果未选择选择选项“无“重试队列”和“无“正在运行的队列”,则会发生这种情况。
从 RFC 的角度来看 - 不必在 ECC 中为 EWM 相关队列设置这些作业,因为创建内向/外向队列时将自动调用计划器。仅当队列首次未成功发送时,才有助于重新处理。但在重新处理之前,需要检查首次进入错误状态的原因。
4.如果上述方案无法彻底解决,可以通过SMQR进入RFC监控器中,选中所有条目,选择“编辑”选项,然后选择激活调度器激活队列的运行状态
后续优化方案:
1.SMQ2如果持续有retry的队列,除了上述的解决方案之外,可能还需要考虑到权限问题,可以参考note:1862256 - 入站队列 (SMQ2) 保持状态 RETRY
2.根据Tuning the PI/PO Messaging System Queues | SAP Blogs提示的检查方案,对可能存在的问题点进行检查并有针对性的排除,同时可以参考93159中的建议https://me.sap.com/notes/937159
3.由于异步线程的特殊性,有可能接收方系统无法在同一时间承受大量的数据,因此单向调整PO队列通道进程并不能很好处理“供需关系”,甚至导致冗余的进程拖垮了服务器的性能,因此,为了保证全局业务的正常进行,可以适当在合理的进程数下,设置全局通道、制定最大接收数量。比如说全局的异步通道为10,指定最大接收数量为4,那么久意味着最少可以允许最大3个系统在同一时间进行高并发的异步数据传输。
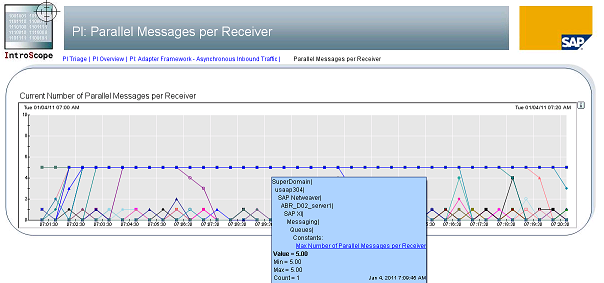
最大接收数量的配置在PO网页的管理后台,属性配置中的服务:
XPI Service: Messaging System->messaging.system.queueParallelism.maxReceivers,如果是0的话是无限制,如果设置了值的话就是有生效的
下面搬运Mike Sibler的文章内容,虽然是老版本的,但是还是有很多可以借鉴的地方:
Tuning the PI/PO Messaging System Queues
Motivation:
Most of the PI/PO adapters are running on Java. With PI 7.3 also the IDoc and HTTP adapter will be available for Java. Therefore for most of the scenarios Java only processing of messages is possible using Integrated Configuration objects (ICO).
For classical ABAP based scenarios the parallelization was mainly triggered by adjusting the parallelization of the ABAP queues in the Integration Engine. Now, since all the steps like mappings and backend calls are executed in the same queue the tuning of the Java based Messaging System queues is now essential. This blog tries to summarize the aspects that have to be considered when tuning the Messaging System queues.
The description is valid for all SAP PI releases. Newer versions have additional possibilities that will be explained where necessary.
Note: All this information will also be made available in the next version of the PI performance check via SAP Note 894509.
Prerequisite:
Wily Introscope is a prerequisite for the analysis discussed below. For more information on Wily please refer to SAP Note 797147 and Processes for 7.2.
Overview
Messaging System:
The task of the Messaging System is to persist and assign resources for messages processed on the Java stack.
Queues in the Messaging System
The queues in the Messaging System behave different then the qRFC queues in ABAP. The ABAP queues are strictly First In First Out (FIFO) queues and are only processed by one Dialog work process at a time. The Messaging System queues have a configurable amount of so called consumer threads that process messages from the queue. The default number of consumer threads is 5 per adapter (JDBC, File, JMS, …), per direction (inbound and outbound) and Quality of Service (asynchronous (EO, EOIO) and synchronous). Hence in case a message is taking very long other messages that arrived later can finish processing earlier. Therefore Messaging System queues are not strictly FIFO.
There are four queues per adapter. All the queues are named <Adapter>_SAP Help Portal<Queue_Name>.
<Queue_Name> here stands for:
- Send (Asynchronous outbound),
- Rcv (Asynchronous Inbound),
- Call (Synchronous outbound) or
- Rqst (Synchronous inbound).
An example for the JMS asynchronous outbound queue is JMS_SAP Help Portal.
The Messaging System is running on every server node. Therefore the maximum number of parallel connections to a backend system can be calculated by multiplying the number of server nodes by the configured number of consumer threads. In case you have 6 server nodes with the default 5 consumer threads for an adapter, you will have at most 30 parallel connections to the receiving backend.
Difference between classical scenarios and Integrated Configuration (ICO)
As stated earlier with 7.1 and higher more and more scenarios can be configured as Integrated Configuration (ICO). This means the message processing is solely done in Java and a message will not be passed to the ABAP stack any longer.
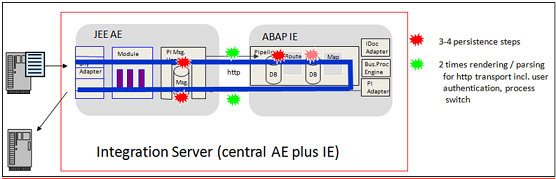
In a classical ABAP based scenarios a message transferred e.g. from JDBC to the JMS adapter will pass the Adapter Engine twice and will also be processed on the ABAP IE. The ABAP IE is responsible for routing and calling the mapping runtime. This is shown below:
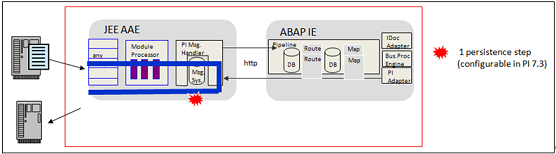
In an Integrated Configuration all the steps (routing, mapping and modules) are processed in the Java stack only:
Looking at the details of Messaging System processing we can see that every message will pass through the dispatcher queue first. The dispatcher queue is responsible for the prioritization of messages and will pass the message further to the adapter specific queues once consumer threads for the specific adapter queue are available. Therefore if you see a backlog on the dispatcher queue it indicates a resource shortage on one of the adapter specific queues. The message flow on the PI AFW outbound side for a classical (ABAP based) scenario is shown below:
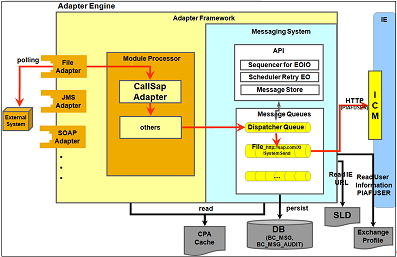
In a classical scenario a backlog will be most often seen on the receiver (inbound) side. The reason for this are the tasks executed in the Messaging System queue. The consumer threads on the sender (outbound) side only have to read the message from the database and forward the message to the Integration Engine. Since this are purely PI internal tasks this is usually very fast. However on the receiver (inbound) side the consumer threads will also be responsible for the Adapter module processing and the connection to the backend. This is more complex and external factors like network bandwidth or performance of the receiving system play a major role here.
In a Java only (ICO) scenario all the processing steps in the Messaging System are executed in the sender queue. The receiver queues are not used at all. Additionally to the above mentioned steps the consumer threads are now also responsible for routing and mapping. All these steps are executed by the sender consumer threads and therefore more time is required per message and a backlog is more likely to occur.
Analyzing a Messaging System backlog:
In the Messaging System a backlog can be seen when there are many messages in status “To be Delivered”. Other messages like “HOLD” status do not represent a backlog on queue level.
In general backlogs in the Messaging System can be caused in the following cases:
- Mass volume interfaces:
An interface that is triggered in a batch can create many messages that will queue within PI. For such interface it might be necessary that a backlog builds up in PI to protect the receiving backend from overloading. Therefore in such a case it is not the purpose of tuning the PI to pretend the backlog but to ensure that other runtime critical interfaces are not blocked by that backlog. - Slow performance of interface:
A long processing time for a single message can be another reason for a backlog In the classical ABAP based scenario this usually only happens on the Receiver Adapter. Reason for that could be a long runtime in the Adapter Module or in the receiving adapter. This can happen for all type of adapters but is especially critical for JDBC/FTP and EDI adapters connecting via slow WAN connections (like OFTP via ISDN).
In the Java-only scenario (ICO) in addition to the above also the mapping execution is now triggered by the Messaging System. A long running mapping (e.g. due to large messages or complex mapping logic) can therefore also cause a backlog for such interfaces. In such a case the bad performance of e.g. the INSERT statements to the remote DB has to be analyzed and improved. This will not be discussed in more detailed here. Please refer to the PI Performance Check for more information.
If further tuning is not possible also here the task is to avoid any blocking situations with other interfaces and avoid an overloading of the system.Based on the above description the aim of tuning of the Messaging System queues is to reduce the PI internal backlog but also ensure that connected backend systems can handle the messages received by PI.
In general backlogs on queues can be recognized using the Engine Status (RWB -> Component Monitoring -> Adapter Engine -> Engine Status) information as shown below.
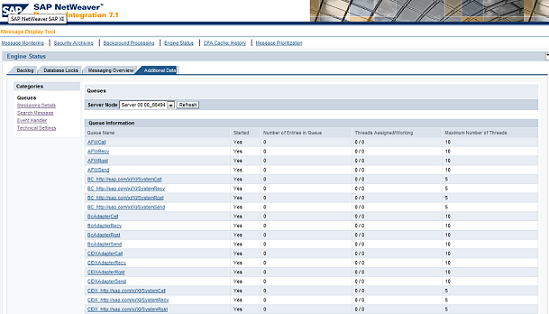
You can see here the number of messages in the queue and also the threads available and currently in use. This page only represents a snapshot for one server node. It is not possible to look at historical data or verify the thread usage on several server nodes simultaneously.
Therefore Wily Introscope is highly recommended. In the PI Triage dashboard you can see all the information in one screen and also analysis of historical data (per default 30 days) is possible. For efficient tuning of your system Wily is therefore mandatory.
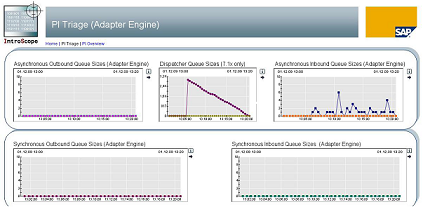
Parameters relevant for MS Queue tuning
Only a couple of parameters are available to tune the queue processing in the Messaging System:
1. Configure consumer threads per adapter:
As explained above all messages are processed using consumer threads that work on adapter specific MS queues. The number of consumer threads can be configured to increase the throughput per adapter. The adapter specific queues in the messaging system have to be configured in the NWA using service “XPI Service: AF Core” and property “messaging.connectionDefinition“. The default values for the sending and receiving consumer threads are set as follows:
(name=global,messageListener=localejbs/AFWListener,exceptionListener=localejbs/AFWListener,pollInterval=60000,pollAttempts=60,Send.maxConsumers=5, Recv.maxConsumers=5,Call.maxConsumers=5,Rqst.maxConsumers=5).
To set individual values for a specific adapter type, you have to add a new property set to the default set with the name of the respective adapter type, for example:
(name=JMS_SAP Help Portal, messageListener=localejbs/AFWListener, exceptionListener=localejbs/AFWListener, pollInterval=60000, pollAttempts=60, Send.maxConsumers=7, Recv.maxConsumers=7, Call.maxConsumers=7, Rqst.maxConsumers=7).
Note that you must not change parameters such as pollInterval and pollAttempts. For more details, see SAP Note 791655 – Documentation of the XI Messaging System Service Properties.Not all adapters use the above parameter. Some special adapters like CIDX, RNIF, or Java Proxy can be changed by using the service “XPI Service: Messaging System” and property messaging.connectionParams by adding the relevant lines for the adapter in question as described above.
2. Restrict the number of threads per interface:
- Restrict the number of threads for classical (dual-stack) interfaces)
As stated earlier in such a situation per default all worker threads could be used with messages waiting for the backend system to finish processing. Thus, this interface can block all other interfaces from the same adapter type, who would rely on the same group of worker threads.
To overcome this, parameter queueParallelism.maxReceivers can be used as described in SAP Note 1136790. This allows for classical (dual-stack) based scenarios to restrict the number of worker threads per interface (based on receiver Party/Service and Interface/Namespace information). By using this parameter you can ensure that even during backlog situations resources are kept free for other interfaces. This parameter is a global parameter – meaning it applies for the receive queue for all adapters. SAP highly recommends to set this parameter for all customers running high volume and high business critical interfaces at the same time in their PI system. - Restrict consumer threads for ICO interfaces:
Java only (ICO) scenarios do not use the Messaging System Receive queues. All steps are performed in the Send queues. Thus, the maxReceivers parameter is not applicable.
But also in ICO scenarios a separation is necessary since the same problems (long running mapping or slow backend) can occur. For this SAP Note 1493502 introduces property “messaging.system.queueParallelism.queueTypes”. By setting the value “Recv, IcoAsync” you ensure that maxReceivers is used for ABAP and Java based scenarios.
For finding the right value the same rules as above apply. - Enhancement to allow configuration of parallel threads per interface:
With 7.31 SPS11 and 7.4 SPS6 (Note 1916598 – *NF* Receiver Parallelism per Interface) an important enhancement was introduced that allows the specification of the maximum parallelization not just globally but on a more granular level. This new feature has to be activated by setting the parameter messaging.system.queueParallelism.perInterface in service MESSAGING to true.
Using a configuration UI you can specify rules to determine the parallelization for one or all interfaces of a given receiver service. If no rule for a given interface is specified the global maxReceivers value will be considered. A potential use case could be to restrict the parallel calls to a receiver system to avoid overloading the same. If the receiver system corresponds to a technical business system only the receiver service would be entered and the interface and namespace would be “*”. This means that across protocols (e.g. IDoc_AAE, Proxy and RFC) the parallelization would be limited by the value specified in this rule. Below you can find a screenshot of the configuration UI in NWA -> SOA -> Monitoring.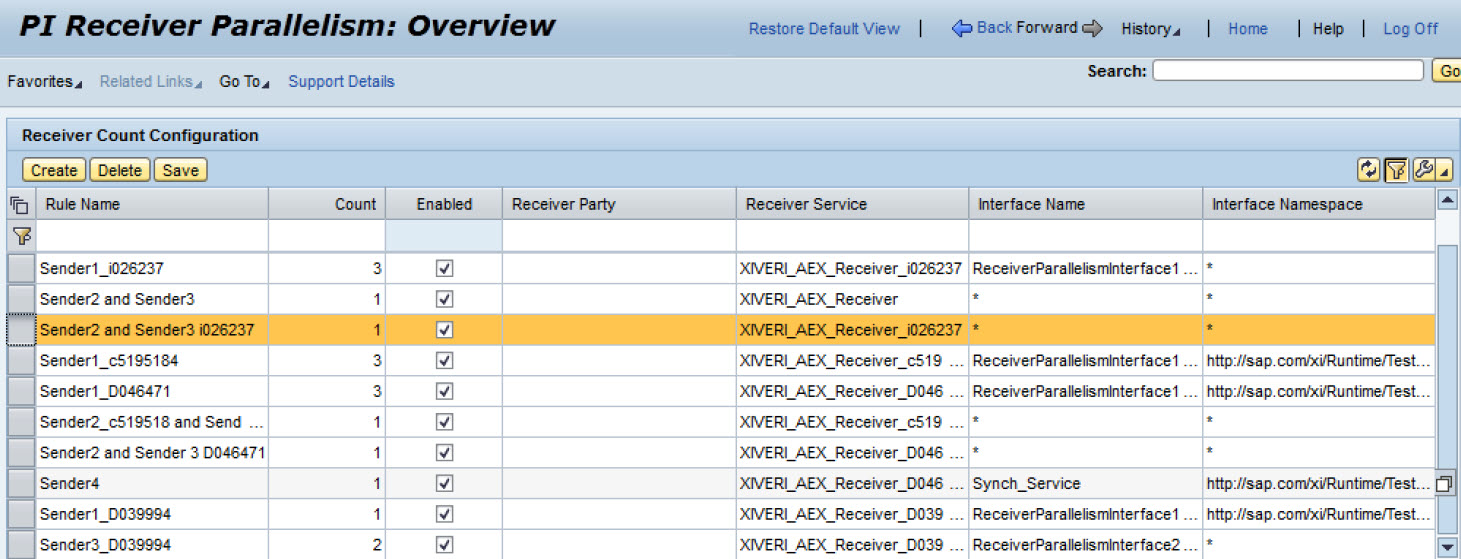
With the improvement mentioned above, also the dispatching mechanism in the dispatcher queue is changed so that it is aware of the maxReceiver settings. This means that now again the backlog will now be placed in the dispatcher queue and the prioritization will work properly.
4. Adapt Concurrency of Communication Channel:
Many receiver adapters like File, JDBC or Mail work per default sequential per server node. They use a synchronization barrier as shown below to avoid overloading of a backend system:
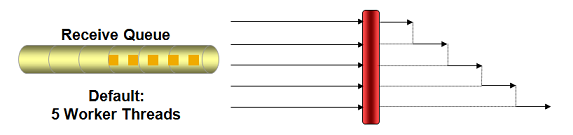
Since they only process one message per server node at a given point in time you should not dedicate too many consumer threads to it. As an example it makes no sense to simply configure 20 worker threads without setting maxReceivers.
To increase the throughput in such a case you also have to adjust the parallelism of the communication channel. For File and JDBC adapter this can be increased using the “Maximum Concurrency” value shown in the screenshot below. By doing this you will ensure that all worker threads that are allocated per interface are really processing messages. Of course the degree of parallelism highly depends on the resources available at the backend system. Setting “Maximum Concurrency” higher then MaxReceivers makes of course no sense.
5. Tuning the MS step by step
Via Wily it’s pretty easy to recognize a backlog. The screenshot below shows a situation where on both available server nodes most of the available worker threads are used for around 15 minutes. In case another runtime critical interface would send messages at the same time they would be blocked.
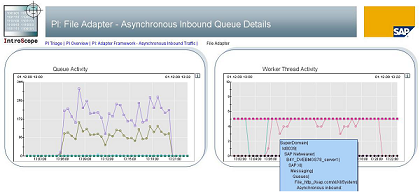
The screenshot below shows a backlog in the Dispatcher Queue. As discussed above messages are only loaded to the Adapter specific queues in case there are free resources available. Thus, a backlog in the Dispatcher Queue points to a bottleneck in resources for one specific adapter. This can be seen easily in Wily.
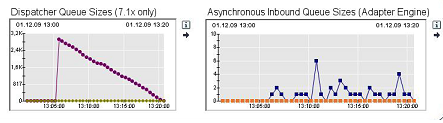
In case you notice such a backlog you should increase the number of consumer threads for the identified queue as described above.
6. Tuning the number of threads used per interface (classical ABAP based scenario):
Tuning of the Messaging System has to be done carefully since it has a direct impact on the resources required in PI and the connected backend. Often PI is a very powerful system and can overload connected backend systems easily.
The Wily screenshot below shows such an example. It is a batch triggered interface that sends in a very short timeframe a lot of messages that are balanced across all server nodes and then processed for a period of more than 20 minutes.
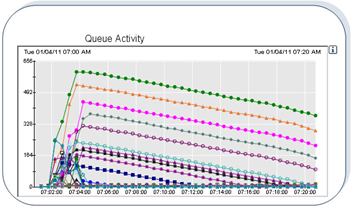
As stated earlier in such a situation per default all worker threads could be used with messages waiting for the backend system to finish processing. Thus, this interface can block all other interfaces from the same adapter type, who would rely on the same group of worker threads.
To overcome this restrict the number of consumer threads per interface using the parameter queueParallelism.maxReceivers. Looking at the below example we can see that the system has 40 worker threads configured (right graphic) but only 5 of them are used for processing the backlog. The reason for this is that queueParallelism.maxReceivers is set to 5. Thus, the remaining 35 consumer threads are available for other interfaces and no blocking situation would occur.
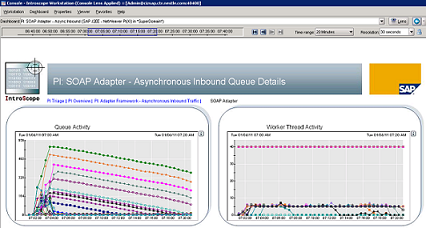
There is a specific Wily dashboard showing the current usage of maxReceivers per interface