多模态指的是多种模态的信息,包括:文本、图像、视频、音频等。而多模态研究的就是这些不同类型的数据的融合的问题。目前大多数工作中,只处理图像和文本形式的数据,即把视频数据转为图像,把音频数据转为文本格式。
目录
📞📞0.背景
❓❓ 1.问题-大多数模型缺乏灵活性,Web 数据嘈杂
🐶🐶2.BLIP解决方案
🌵2.1网络结构
🌴2.2噪声数据处理(CapFilt)
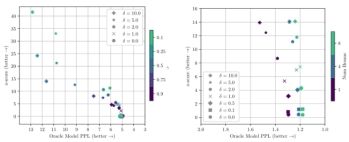
🌲2.3CapFilt消融实验
🐯🐯3.下游任务
🌵3.1图像文本检索(Image-Text Retrieval)
🌴3.2图像字幕(Image Caption)
🌲3.3视觉问答VQA(Visual Question Answering)
🌳3.4自然语言视觉推理NLVR2 (Natural Language Visual Reasoning)
🌱3.5视觉对话 VisDial(Visual Dialog)
🌾3.6. 0样本迁移到视频语言任务(Zero-shot Transfer to Video-Language Tasks)
🐰🐰4.结果
🌵4.1图像文本检索
🌴4.2图像字幕
🌲4.3VQA和NLVR2
🌳4.4视觉对话
🌱4.5文本到视频检索
🌾4.6视频问答
附加(本文未涉及)
代码地址:code
论文地址:paper
📞📞0.背景
视觉和语言是人类感知世界的两种最基本的方式,也是人工智能的两大关键基石。人工智能的一个长期目标是构建能够通过视觉和语言输入理解世界并通过自然语言与人类交流的智能代理。
为了实现这一目标,视觉语言预训练 已成为一种有效的方法,其中深度神经网络模型在大规模图像文本数据集上进行预训练,以提高下游视觉语言任务(例如图像文本)的性能。文本检索、图像字幕和视觉问答。
简而言之,视觉语言预训练旨在利用图像文本数据来教会模型共同理解视觉和文本信息的能力。通过预训练,模型在微调之前就已经过训练(微调涉及使用下游任务的数据对预训练模型进行额外的训练)。如果没有预训练,模型需要在每个下游任务上从头开始训练,这会导致性能下降。
❓❓ 1.问题-大多数模型缺乏灵活性,Web 数据嘈杂
- 从模型角度来看,大多数现有的预训练模型不够灵活,无法适应广泛的视觉语言任务。基于编码器的模型不太容易直接转移到文本生成任务,而编码器-解码器模型尚未成功应用于图像文本检索任务。
- 从数据角度来看,大多数模型都会对从网络自动收集的图像和替代文本对进行预训练。然而,网络文本通常不能准确描述图像的视觉内容,使它们成为监督的嘈杂来源。
🐶🐶2.BLIP解决方案
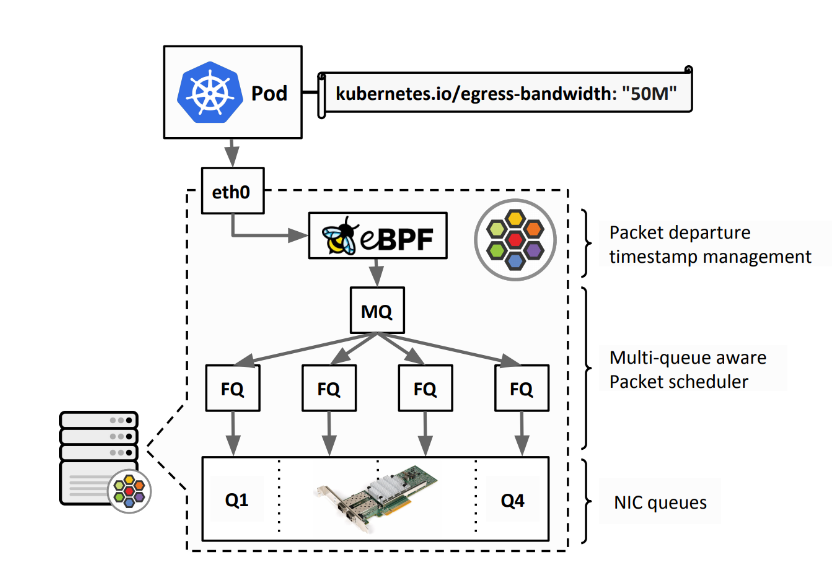
🌵2.1网络结构
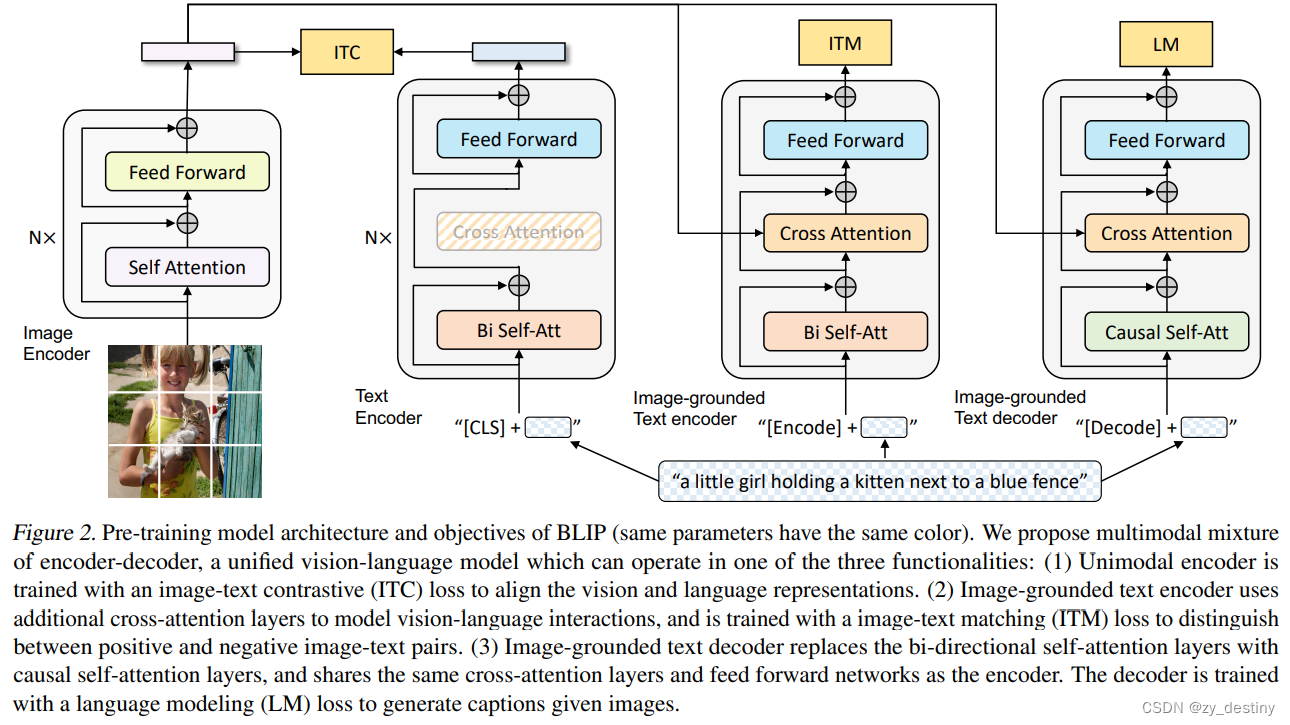
为了预训练具有理解和生成能力的统一视觉语言模型, BLIP 引入了编码器-解码器的多模态混合,这是一种多任务模型,可以在以下三个功能之一中运行:
- 单模态编码器,分别对图像和文本进行编码。图像编码器是一个视觉转换器。文本编码器与 BERT 相同。[CLS] 标记附加到文本输入的开头以总结句子。
- 基于图像的文本编码器,通过在文本编码器的每个变换器块的自注意力层和前馈网络之间插入交叉注意力层来注入视觉信息。特定于任务的 [Encode] 标记被附加到文本中,并且 [Encode] 的输出嵌入用作图像-文本对的多模态表示。
- 基于图像的文本解码器,用因果自注意力层替换文本编码器中的双向自注意力层。特殊的 [Decode] 标记用于表示序列的开始。
BLIP在预训练过程中联合优化了三个目标,其中两个基于理解的目标(ITC、ITM)和一个基于生成的目标(LM):
- 图像文本对比损失(ITC)激活单峰编码器。它的目的是通过鼓励正图像-文本对与负图像-文本对相比具有相似的表示来对齐视觉变换器和文本变换器的特征空间。
- 图像文本匹配损失(ITM)激活基于图像的文本编码器。ITM 是一项二元分类任务,要求模型在给定多模态特征的情况下预测图像-文本对是正(匹配)还是负(不匹配)。
- 语言建模损失(LM)激活基于图像的文本解码器,其目的是生成以图像为条件的文本描述。
🌴2.2噪声数据处理(CapFilt)
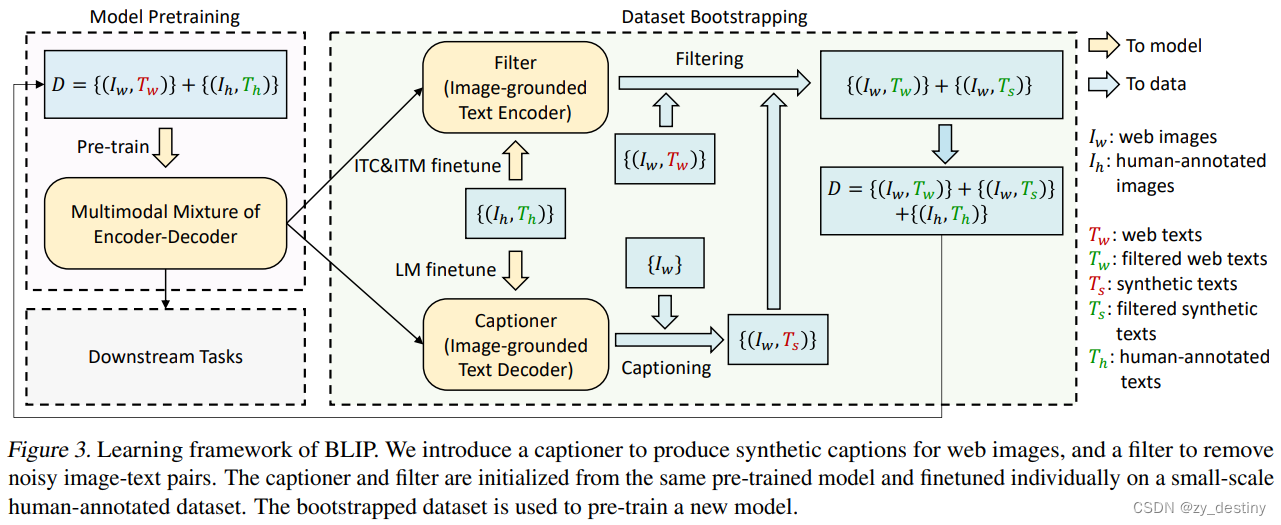
为了解决网络收集到的大规模数据中存在图像文本不配对的这个问题,BLIP通过引入两个模块来引导字幕:字幕生成器和过滤器。
- 字幕生成器 是一个基于图像的文本解码器。给定网络图像,我们使用字幕生成器生成合成字幕作为额外的训练样本。
- 过滤器 是一个基于图像的文本编码器。它会删除与相应图像不匹配的嘈杂文本。
🌲2.3CapFilt消融实验


红色:网络收集的图像文本对
绿色:基于网络收集的图像生成的文本
🐯🐯3.下游任务
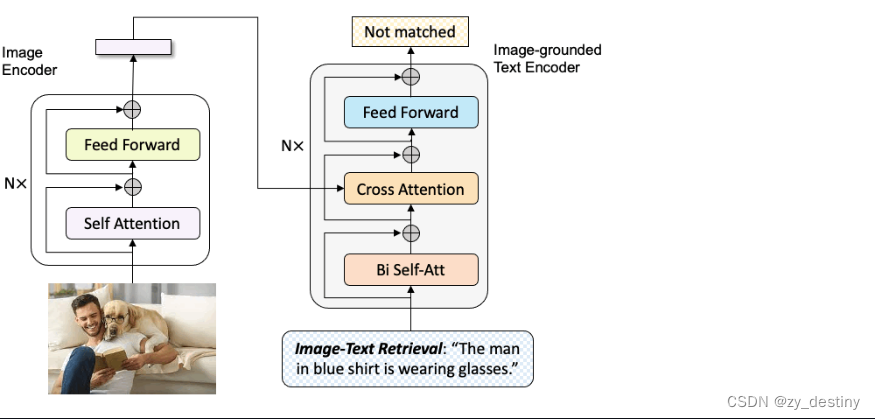
🌵3.1图像文本检索(Image-Text Retrieval)
图像文本检索有三种方式:
1)以图搜文。输入图片,输出文本
2)以文搜图。输入文本,输出图片
3)以图搜图,输入图片,输出图片
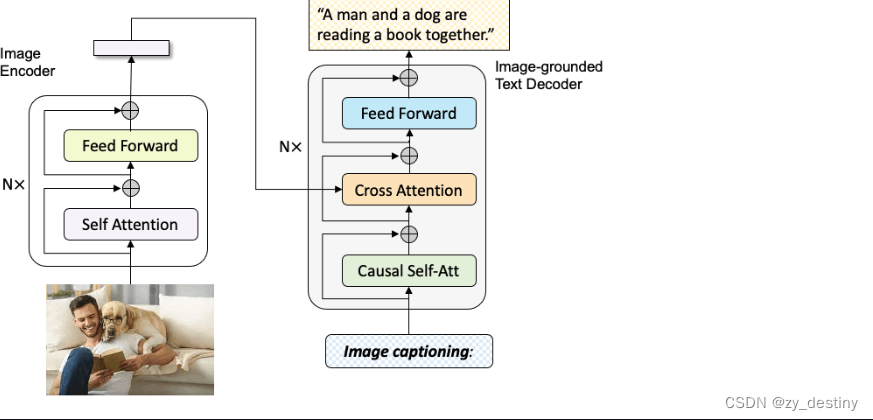
🌴3.2图像字幕(Image Caption)
输入:一张图片
输出:图片的自然语言描述(一个句子)
Referring Expression Comprehension 指代表达
输入:一张图片、一个自然语言描述的句子
输出:判断句子描述的内容(正确或错误)
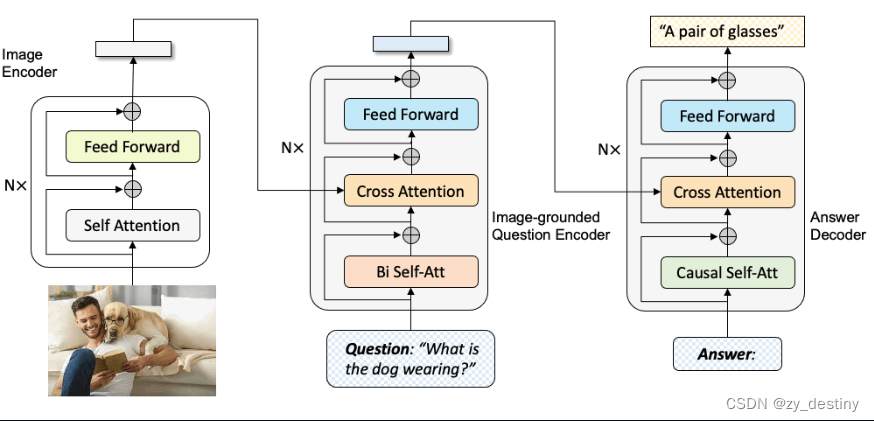
🌲3.3视觉问答VQA(Visual Question Answering)
输入:一张图片、一个自然语言描述的问题
输出:答案(单词或短语)
🌳3.4自然语言视觉推理NLVR2 (Natural Language Visual Reasoning)
输入:2张图片,一个文本
输出:true或false
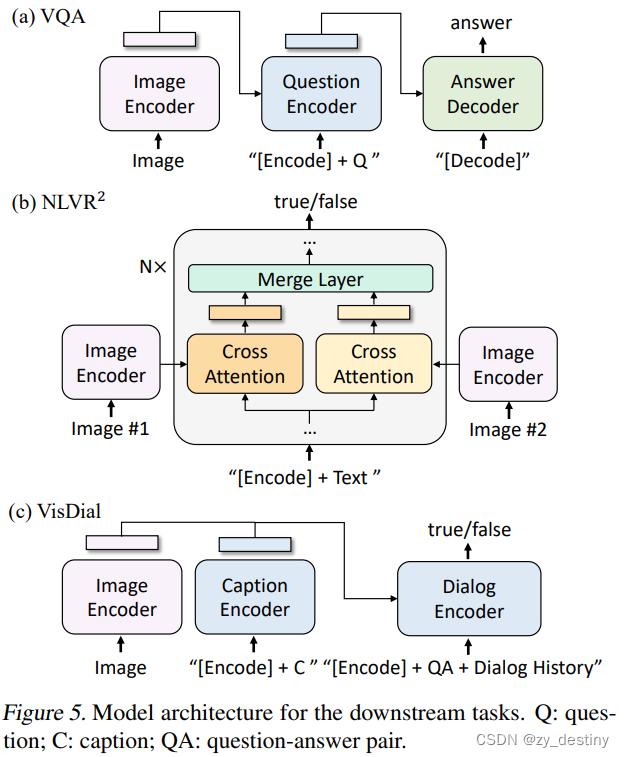
🌱3.5视觉对话 VisDial(Visual Dialog)
输入:一张图片
输出:两个角色进行多次交互、对话
🌾3.6. 0样本迁移到视频语言任务(Zero-shot Transfer to Video-Language Tasks)
🐰🐰4.结果
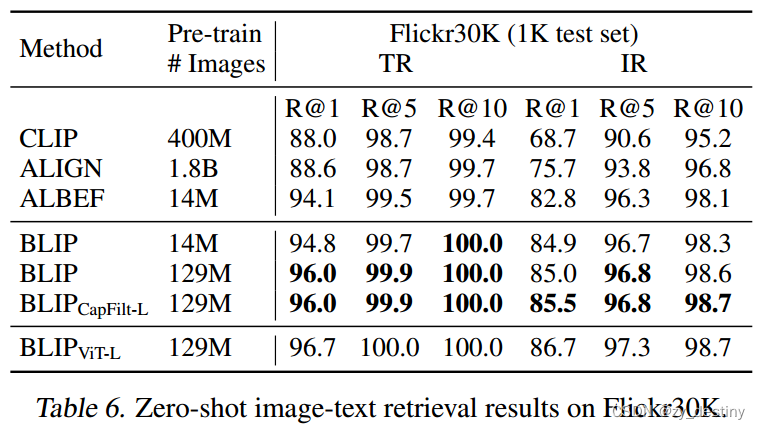
🌵4.1图像文本检索
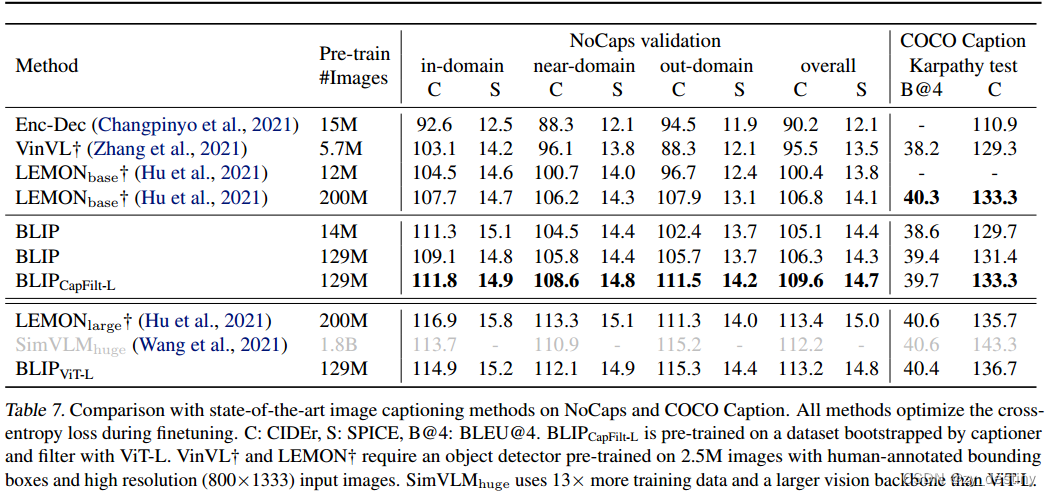
🌴4.2图像字幕
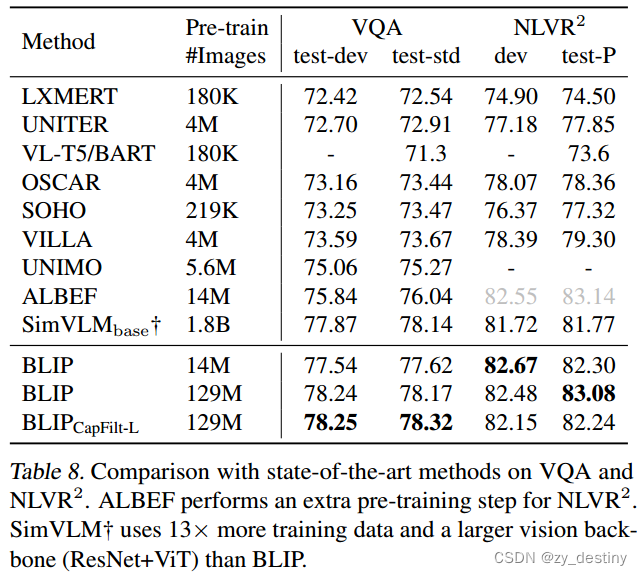
🌲4.3VQA和NLVR2
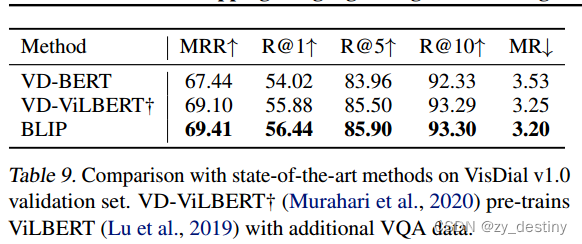
🌳4.4视觉对话
🌱4.5文本到视频检索
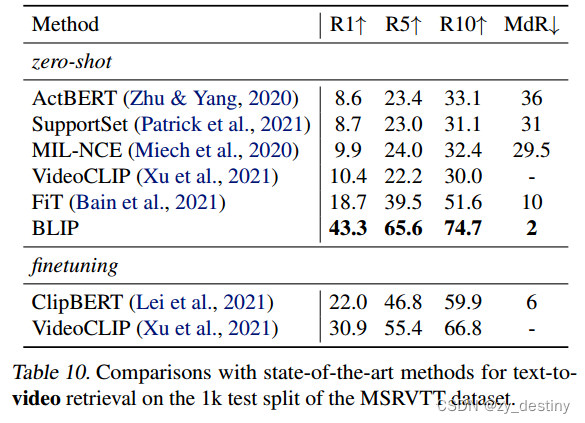
🌾4.6视频问答
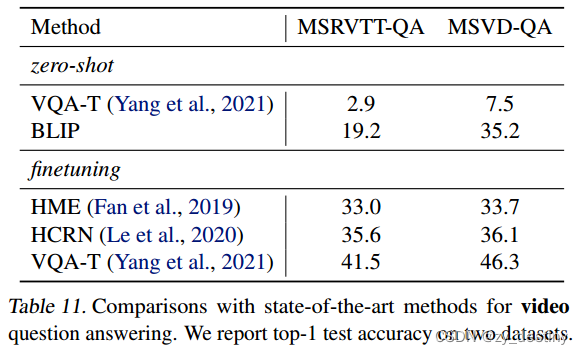
BLIP在七项视觉语言任务上实现了SOTA性能,包括:
- 图文检索
- 图像字幕
- 视觉问答
- 视觉推理
- 视觉对话
- 零样本文本视频检索
- 零镜头视频问答。
附加(本文未涉及):
还有一种多模态融合任务:Visual Entailment 视觉蕴含
输入:图像、文本
输出:3种label的概率。(entailment、neutral、contradiction)蕴含、中性、矛盾

整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷