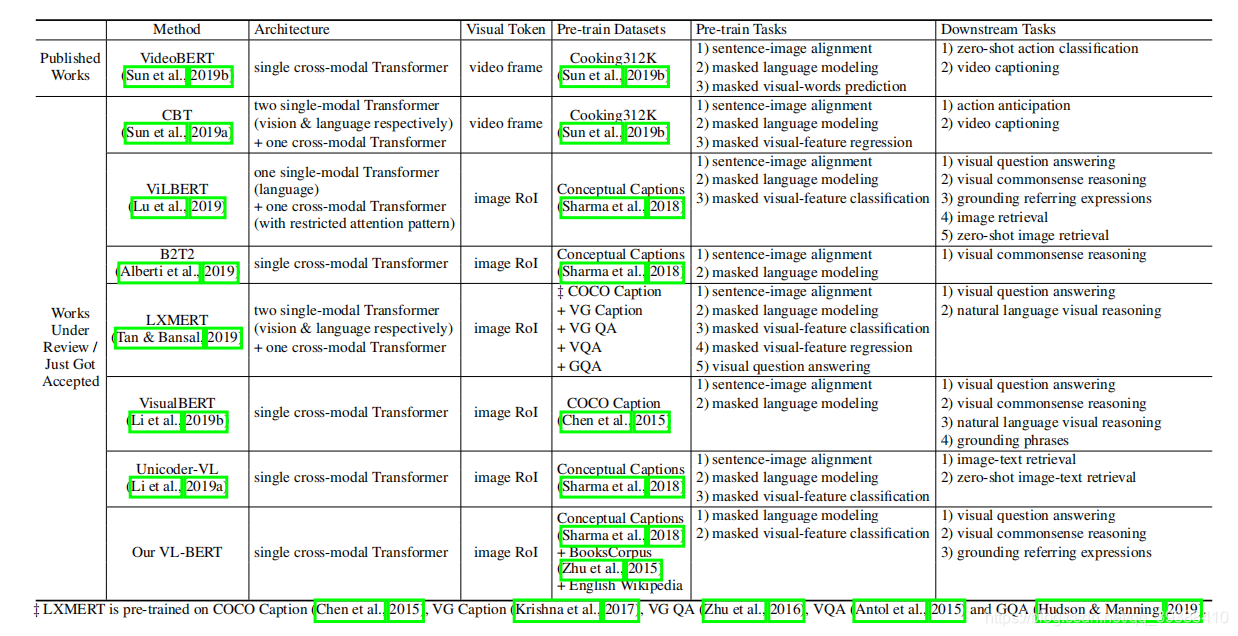
BERT以及BERT后时代在NLP各项任务上都是强势刷榜,多模态领域也不遑多让…仅在2019 年就有8+篇的跨模态预训练的论文挂到了arxiv上…上图是多篇跨模态论文中比较稍迟的VL-BERT论文中的比较图,就按这个表格的分类(Architecture)整理这几篇论文吧。
预训练优势?
- 可以从无标注数据上更加通用的知识迁移到目标任务上,进而提升任务性能
- 学习到更好的参数初始点,使得模型在目标任务上只需少量数据就能达到不错的效果
多模态优势?
- 学到不同模态之间的语义对应关系。
预训练技术上首先是BERT的基础公式,不做赘述。所有的论文都是基于BERT做改装或者暴力组合的,如果按上图的Architecture可以分为one single和two single,one single会把text和visual融合到一个模型中,two single是分别处理text和visual(early fusion和late fusion)。
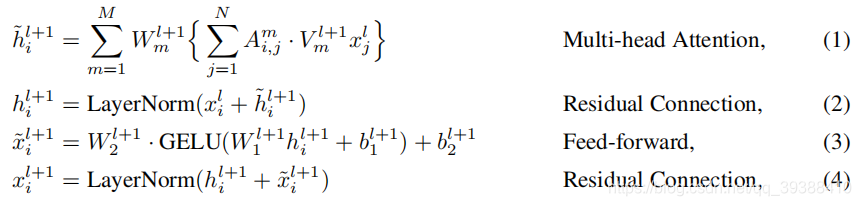
One Single
VideoBERT
VideoBERT: A Joint Model for Video and Language Representation Learning
主要思路是改进 BERT 模型。 从视频数据的向量量化和现有的语音识别输出结果上分别导出视觉帧token和语言学词 token,然后在这些 token 的序列上BERT。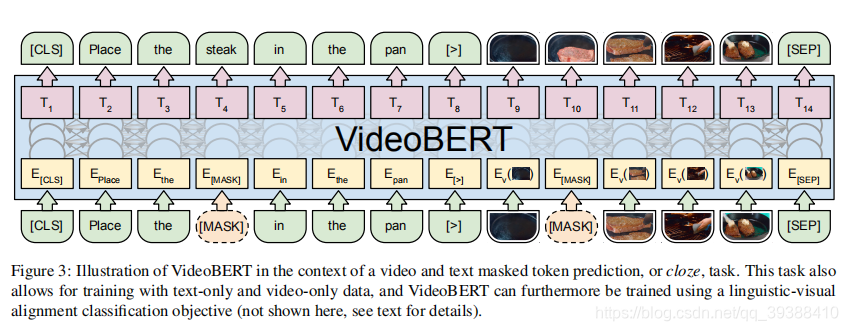
值得注意的模型细节:
- 为了将BERT扩展到视频(这其实是8+篇里面唯一一份做视频的paper),以便仍然可以利用预先训练的语言模型和可伸缩的实现进行推理和学习,作者首先将原始视觉数据(整个视频)成一个离散的图片帧 token序列,以得到“visual words”。
- 文本和视频的语义对齐存在困难,因为即使在教学视频中,演讲者也可能指的是视觉上不存在的东西。解决方案:1随机地将相邻的句子连接成一个长句子,以允许模型学习语义对应,即使两者在时间上没有很好地对齐。2即使是相同的动作,状态转换的速度也会有很大的变化,我们随机为视频令牌选择1到5步的次采样速率。 这不仅有助于该模型对视频速度的变化具有更强的鲁棒性,而且还允许该模型捕获时间动态 在更大的时间范围内学习更长的状态转换。
- 3种训练任务。 text-only, video-only,和video-text。对于单模态任务,用标准的BERT打上mask进行预测,对于跨模态任务,用语言-视觉对齐任务,即使用[CLS]的最终隐藏状态来预测语言句子是否在时间上与视觉句子对齐。
使用该预训练模型可以实现从video到text,也可以从text到video的各种任务。文章中主要验证了两个任务:zero-shot action classification和video captioning。
B2T2
Fusion of Detected Objects in Text for Visual Question Answering
应用领域是视觉问答中的检测到物体的文本融合,尝试通过BERT利用了在同一个统一架构中把单词指向图像中的一部分的参考信息。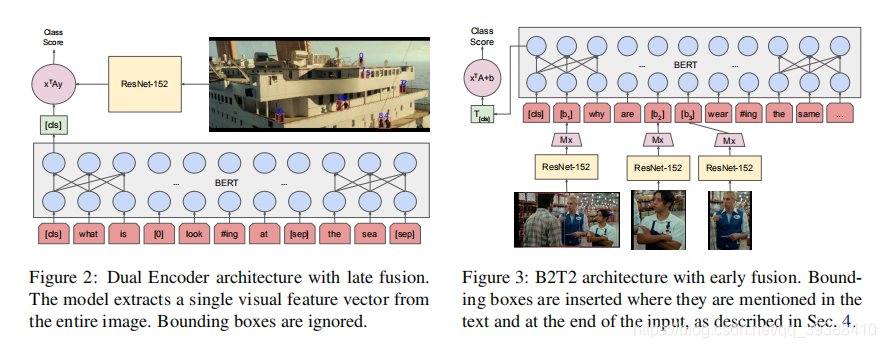
值得注意的模型细节:
- 评估了两种主要的体系结构:“双编码器(Dual Encoder)”,一种late fusion的结构,其中图像和文本被单独编码,score被计算为内积(BERT结构的[CLS]输出端引入整个图像的特征,判断图文是否匹配),如左图。而右图是完整的B2T2模型, 一种early fusion结构,其中视觉特征嵌入在与输入字标记相同的级别上,值得注意的是图像不是单独一边输入的,而是在“Mx”即masked的词位置输入改词的局部区域特征。
- 两个预训练任务: (1) impostor identification and (2) masked language model prediction.
- 只有一个下游任务就是它自己的应用领域VQA。
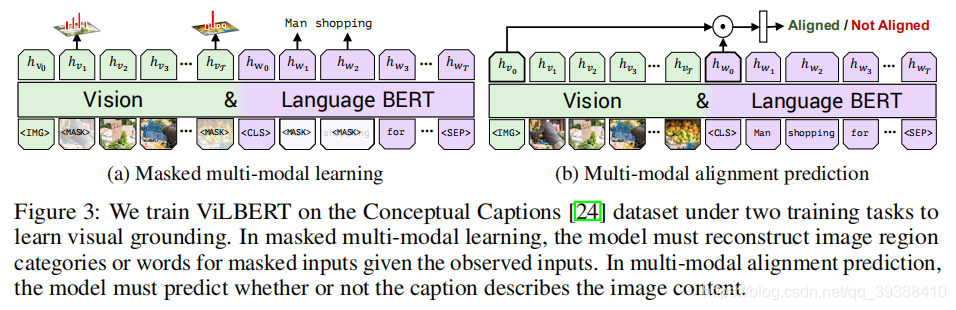
VisualBERT
VISUALBERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE.
改装BERT,以将输入一段文本中的元素(词)和一张相关的输入图像中的区域(局部)隐式地对齐起来。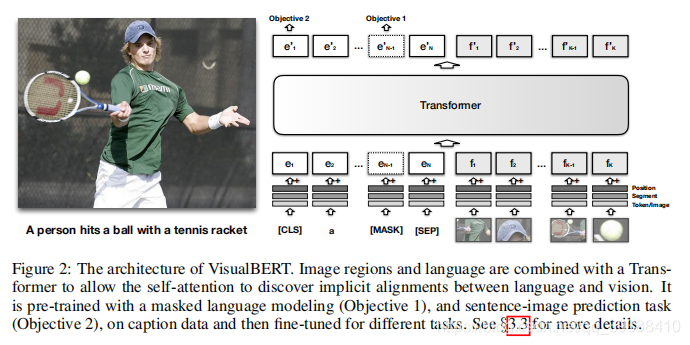
值得注意的模型细节:
- 输出使的三种embedding信息的增加,分别是position,segment,token/image。position是目标检测得到的局部位置or 句子词的位置;segment表示是图像嵌入or 文本嵌入;词or视觉特征。
- 两种训练任务:(1)部分文本被屏蔽,模型学习根据剩余文本和视觉上下文预测屏蔽词;(2)确定所提供的文本是否匹配图像。
- 预训练任务:VQA,VCR,NLVR,和Entities。
- 设备:4 Tesla V100s each with 16GBs
Unicoder-VL
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
网络结构和训练策略与VideoBert大同小异,将视频片段帧特征换成了单图的局部区域。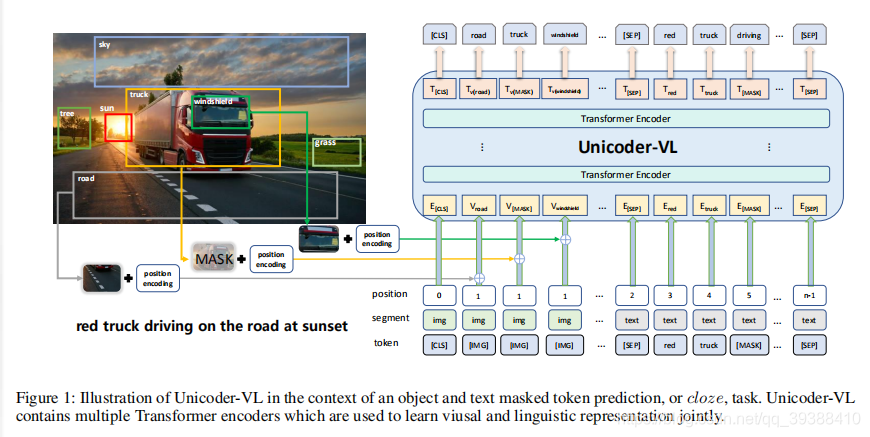
值得注意的模型细节:
- 预训练阶段使用三个任务,包括masked语言建模(MLM)、masked对象标签预测(MOC)以及视觉-语言匹配(VLM)。前两个任务会让模型学习从基于语言和视觉内容输入的联合 token 学习到内容相关的表征(都是15%masked之后,利用相应的上下文进行预测重构,其中MOC预测的不是特征而是区域的label);后一个任务尝试预测一张图像和一段文本描述之间是否相符。
- 预训练下游任务:image-text retrieval,zero-shot image-text retrival。
- 设备: 4 NVIDIA Tesla V100 GPU
VL-BERT
VL-BERT: PRE-TRAINING OF GENERIC VISUAL- LINGUISTIC REPRESENTATIONS
在VL-BERT中,视觉和语言的嵌入特征将同时作为输入,这些元素是在图像中的感兴趣区域(RoIs)上定义的特征 以及输入句子中的子词。 RoIs可以是由对象检测器产生的包围框,也可以是某些任务中的注释框。如下图的结构,不管是句子还是图片都有visual feature,用于捕捉视觉线索。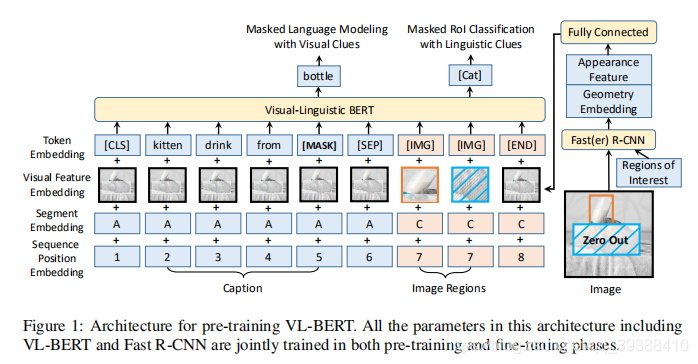
值得注意的模型细节:
- 输入由四个部分构成,token embedding, visual feature embedding, segment embedding, and sequence position embedding。token和BERT一样,对于图像的输入给特殊的[IMG]token做标记;visual feature用于捕捉视觉线索,visual appearance feature用Faster-RNN抽取, visual geometry embedding是每个框的4-d位置信息然后做正弦余弦处理,最后用FC得到特征;segment标记是句子or图片,在不同任务中标记不同,如在VQA中A denotes Question, B denotes Answer, and C denotes Image,在caption中就只有A和C两种标记,position,标识输入序列中的顺序,由于image reginos不存在顺序,所以标记都是一样的(如图中的7)。
- 三个预训练任务为:带有视觉线索的masked文字建模、带有语言线索的感兴趣区域RoI分类、句子-图像关系预测。
- 设备:Pre-training is conducted on 16 Tesla V100 GPUs for 250k iterations by SGD。
UNITER
来自ECCV 2020的UNITER: UNiversal Image-TExt Representation Learning
文章的动机来源于:能否为所有V + L任务学习通用的图像文本表示形式?所以这篇文章最重要的贡献就是不再只单独mask某个模态,而是以一种混合学习的形式进行统一的表示学习。模型架构图如下,上半部分是UNITER的模型架构,会先对image和sentence用预训练模型抽特征然后再输入到Transformer中。下半部分则是作者提出的多个预训练模型。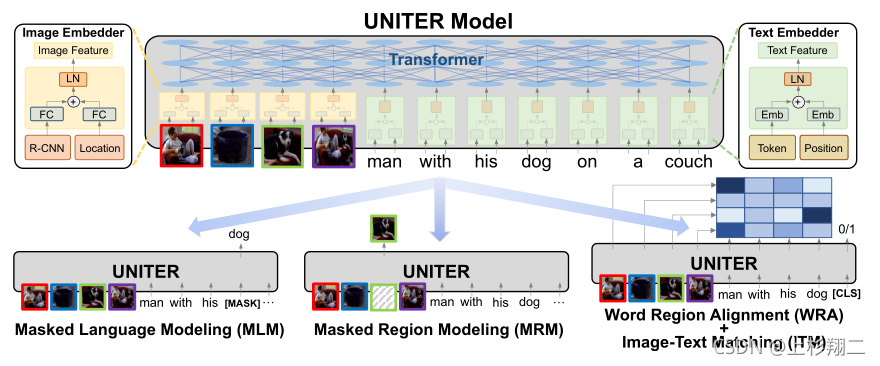
值得注意的模型细节:
- 提前预训练的效果比不使用预训练的特征效果要更好。
- 四种预训练任务:以图像为条件的掩码语言建模(MLM),以文本为条件的掩码区域建模(MRM),图像文本匹配(ITM),字区域对齐(WRA)。前两种掩码训练中是只掩盖一个模态而保持另一个模态不变,而不是像其他预训练方法那样随机掩盖两个模态。后面两种任务解决跨模态对齐问题。
- 然后还有三种MRM变体:掩码区分类(MRC),掩码区域特征回归(MRFR),具有KL散度的掩码区域分类(MRC-kl)。MRM本来是为了在给定其余区域的情况下重建掩码区域和所有单词,但与以离散标签表示的文本标记不同,被掩掉的视觉标记特征是高维且连续的,因此无法通过类可能性进行监督,所以新增这三种变体能够更好的学习。
Pixel-BERT
Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers
其实这篇文章本质上与以上其他文章差距不是很多,之所以要叫pixel-BERT的原因是在得到图像特征的时候会多学一个 local feature patch,然后再拿这种pixel feature和semantic embedding相加一起作为图像的表示即可。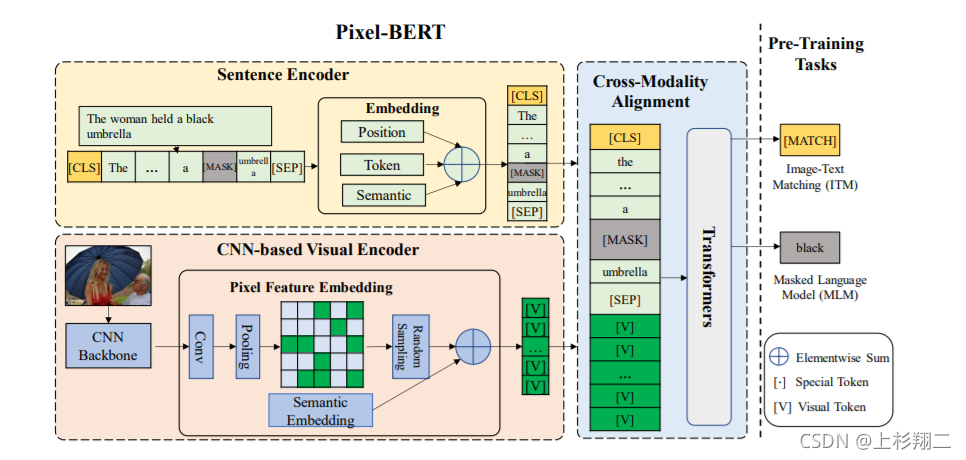
补充pixel feature好处是可以补充一些重要的视觉信息缺失,如物体的形状,空间关系等等,算是能够捕捉更细腻的信息吧。计算资源是64 张 V100 。
Oscar
也是来自ECCV20,Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
这篇文章比较有意思的是,首次引入目标检测的tag作为锚点以降低对齐的难度,并且也搭上了对比学习的车对正负例(词,目标标签,图像区域)的学习进行优化。如下图展示了word-tag-region的三元组应该如何对齐,以及它主要可以解决的下游任务。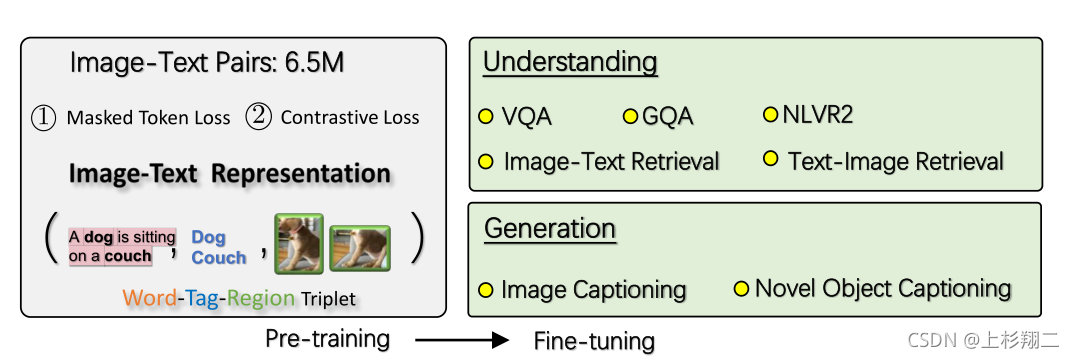
模型图如下,Transformer的输入也是三个部分,其中tag是和word共享dictionary的。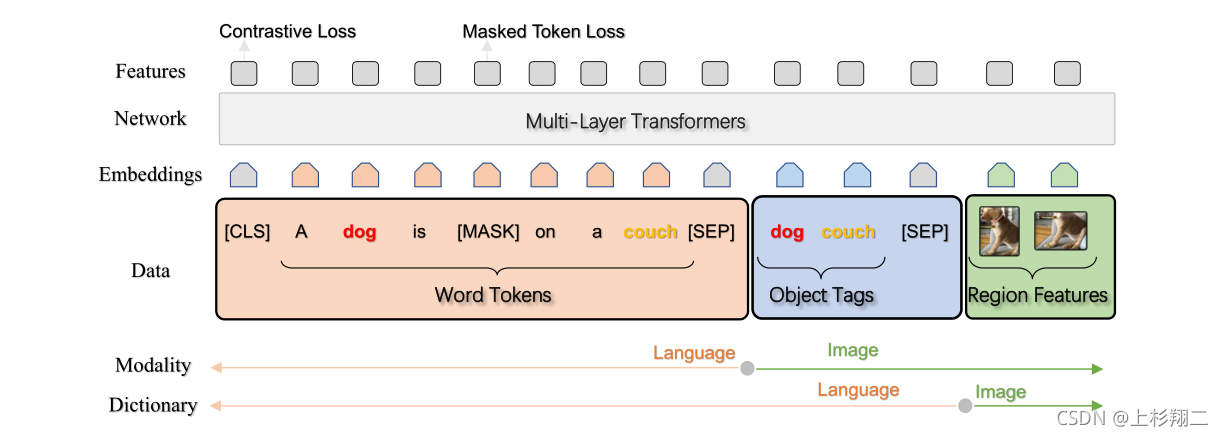
然后就是两个任务Masked Token Loss (MTL) 和Contrastive Loss了。
Two Single
ViLBERT
两个BERT流中分别预处理视觉和文本输入,并在 transformer 层中进行交互(co-Transformer…),具体如下图。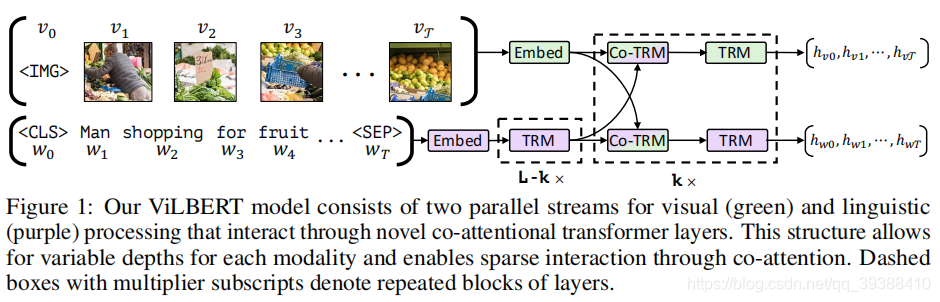
所谓co-Transformer如下,将原encoder的部分,变成co-Attention的形式,分别向对方Query然后优化特征。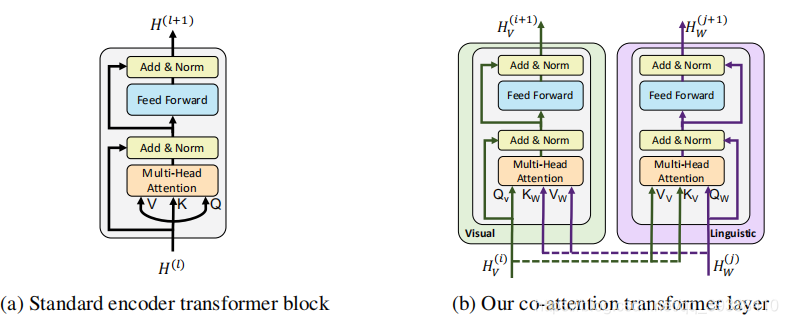
值得注意的模型细节:
- 仍然是尝试masked图片局部和masked文字建模,与image-text pair。任务细节如下图,其中图片的区域的构造是5-d,多加入了 局部区域覆盖比(fraction of image area covered),对于图像BERT也是给的IMG token。
- 下游任务:VQA,VCR,Grounding Referring Expressions,Caption-Based Image Retrieval,‘Zero-shot’ Caption-Based Image Retrieval。
- We train on 8 TitanX GPUs with a total batch size of 512 for 10 epochs.
LXMERT
LXMERT: Learning Cross-Modality Encoder Representations from Transformers
三个编码器:一个对象关系编码器、一个语言编码器和一个跨模态编码器(是cross-Transformer)。图像经过目标检测模型得到区域块的特征序列,并经过Transformer进一步编码;文本侧通过BERT结构得到文本的特征序列,最后两者做cross-Transformer进行多任务的预训练。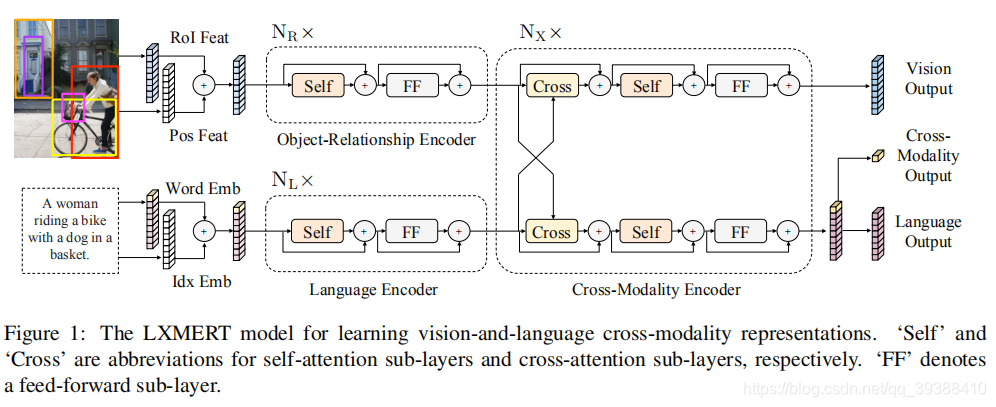
值得注意的模型细节:
- 使用了 5 个不同的、有代表性的预训练任务:masked语言建模、masked对象预测(特征回归和标签检测)、跨模态对齐以及图像问答。
- 在vision output会做RoI-Feature Regression和Detected Label Classification,cross output会做Cross-Modality Matching & QA,language output会做Masked Cross-Modality LM。
- The whole pre-training process takes 10 days on 4 Titan Xp。 Adam,le-4,256.
ERNIE-ViL
Knowledge enhanced vision-language representations through scene graph
架构上也是对于图像和文本分别使用单模编码器进行编码,然后使用跨模态Transformer实现两个模态的信息交融。比较不一样的就是视觉场景图它来了,尝试把场景图中的关系知识融入多模态预训练中,使得模型更能精准把握图像和文本之间细粒度的对齐信息。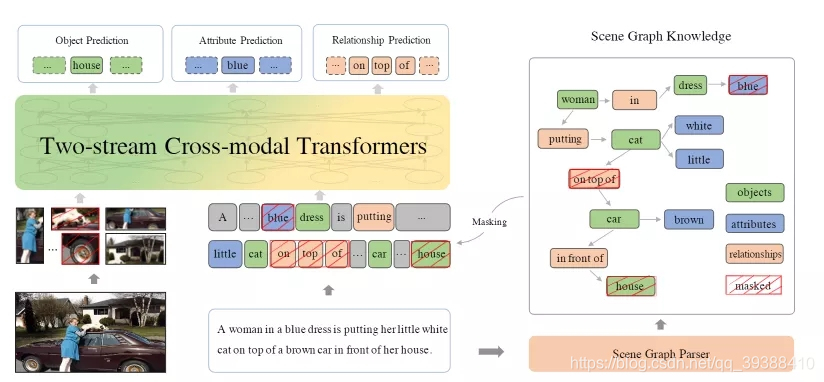
值得注意的模型细节:
- 场景图预测(Scene Graph Prediction)预训练任务。即根据给定的一段文本解析出场景图结构,然后根据解析出的场景图设计三个子任务,分别是目标预测(object prediction)、属性预测(attribute prediction)、关系预测(relationship prediction),通过掩蔽图像和文本中场景图解析出来的目标、属性以及关系,使用模型进行预测,以让模型学习到跨模态之间的细粒度语义对齐信息。
- 其他预训练任务:Masked Cross-Modality LM、Detected-Label Classification,Cross-Modality Matching
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
补上一篇ICML2021的文章。
首先作者归纳了一下,目前有的4种不同类型的Vision-and-Language Pretraining(VLP),如下图: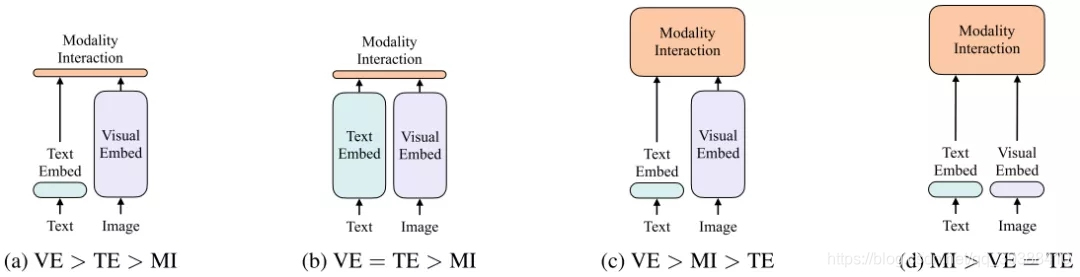
- a。对图像和文本双流使用encoder,其中图像的更重,文本的更轻,然后使用简单的点积或者浅层attention层来表示两种模态特征的相似性。
- b。每个模态单独使用比较重重的transformer encoder,然后使用池化后的图像特征点积计算特征相似性。
- c。使用深层transformer进行交互作用,但是由于VE仍然使用重的卷积网络进行特征抽取,导致计算量依然很大。
- d。这是作者自己提出的模型,目的是提出ViLT是首个将VE设计的如TE一样轻量的方法,该方法的主要计算量都集中在模态交互上。
如何实现这种轻量呢?如下图的模型图
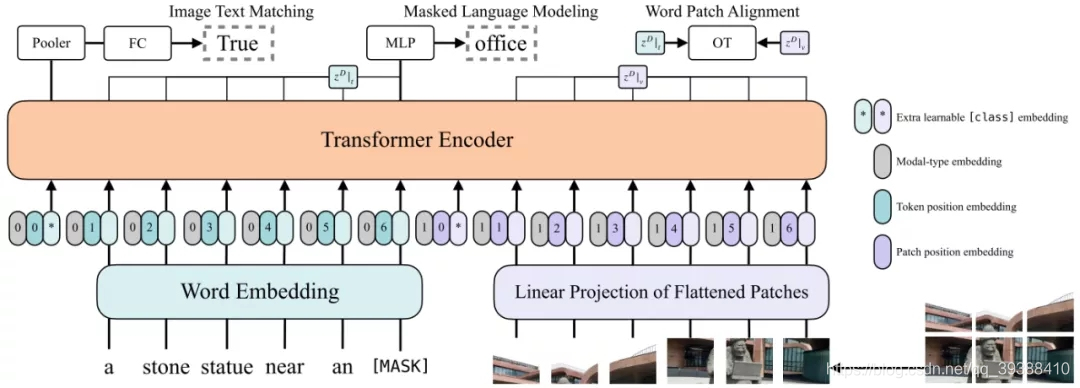
主要是图像端VE使用预训练的ViT做patch projection。即直接将图像切块看成一个图像块序列,通过linear projection转化成visual embedding,然后和postion embedding进行相加,最后和modal-type embedding进行concate。然后做3个预训练任务:
- ImageText Matching:随机以0.5的概率将文本对应的图片替换成不同的图片,然后判断图像文本是否匹配
- Masked Language Modeling:随机以0.15的概率mask掉tokens,通过文本的上下文信息去预测masked的文本tokens
- Whole Word Masking:将连续的子词tokens进行mask的技巧,而不使用图像信息
paper:https://arxiv.org/abs/2102.03334
code:https://github.com/dandelin/ViLT
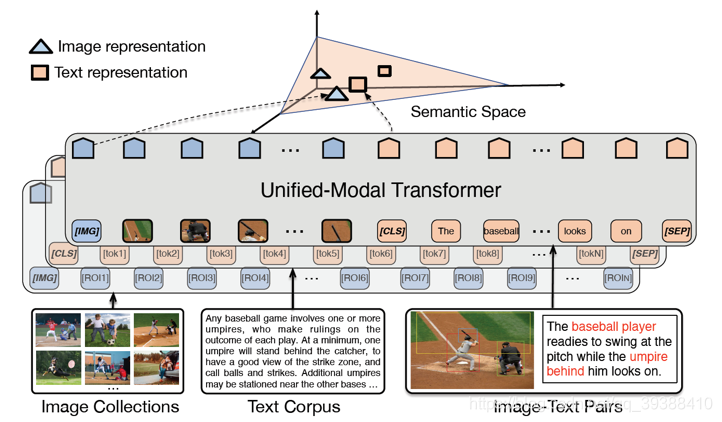
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
继续补文ACL2021的文章,这篇文章的重点是“统一模态”,即跨模态多模态模型能否同时做单模和多模场景呢?即多模态模型不应该对模态的缺失而那么的敏感。具体的模型如上图,思路仍然是依靠大量的数据+预训练任务,由于想同时处理单模和多模,所以任务分为这两种:
- 视觉学习。mask掉区域,用剩下区域来还原该部分+用文本和剩下区域来还原该部分。
- 文本学习。mask掉词,和视觉类似操作。另外为了让模型能同时支持生成和理解两类目标,UNIMO设计了双向预测(Bidirectional prediction)和 序列生成(Seq2Seq Generation)两种损失。
- 跨模态学习。文本改写(Text Rewriting),从句子级(利用回译扩增)、短语级和词汇级别(利用场景图替换object)三个粒度进行了改写。
- 跨模态学习。图文检索,分别对锚样本做图像检索和文本检索两个任务,得到loss为L C M C L ( V , W ) = − l o g p o s p + p o s I + p o s T ( n e g p + n e g I + n e g T ) + ( p o s p + p o s I + p o s T ) L_{CMCL}(V,W)=-log\frac{pos_p+pos_I+pos_T}{(neg_p+neg_I+neg_T)+(pos_p+pos_I+pos_T)}LCMCL(V,W)=−log(negp+negI+negT)+(posp+posI+posT)posp+posI+posT
按正负例样本对p o s p + p o s I + p o s T pos_p+pos_I+pos_Tposp+posI+posT别代表强正例集合,图像检索的弱相关集合,文本检索的弱相关集合。n e g p + n e g I + n e g T neg_p+neg_I+neg_Tnegp+negI+negT表示对应的负例集合。
paper:https://arxiv.org/pdf/2012.15409:
code:https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO
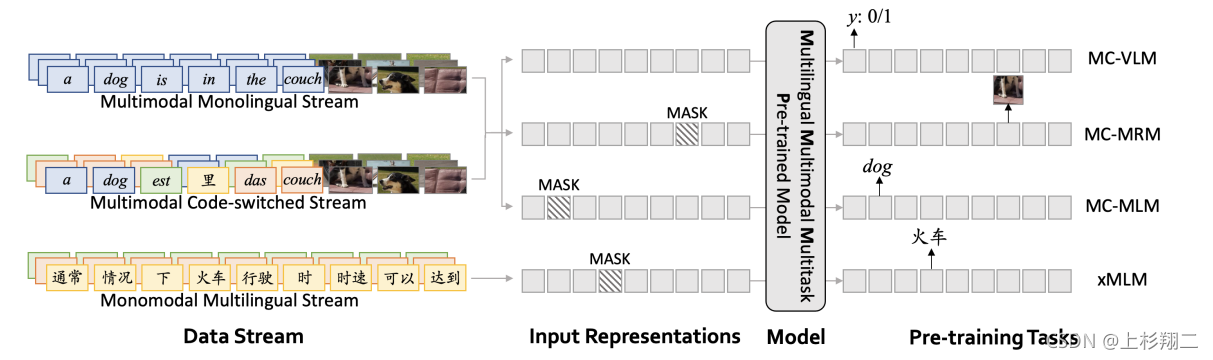
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
继续补文CVPR2021,与前面的文章稍有不同的是,这篇文章主打的是多任务多语言多模态预训练的模型,即M3P模型。模型框架如上图,其实重要的部分主要是输入的那三块:多模态单语言,多模态混合语言,单模态多语言三个输入,然后做多个预训练任务,包括VLM,MRM,MLM,xMLM这些。其中混合语言通过code-switched来实现,即多语言相同词直接进行替换来提高丰富度。
paper:arXiv:2006.02635v4
总结:
- 单模型主要改进BERT的输入,双模型主要做co/cross的BERT。
- 全图片只能预测特征,masked的精髓在于图片的局部区域,可特征可label。
- 预训练任务的单模态以mask为主,视频可以打乱帧时序,细化可以到object关系。多模态以语义对齐为主,一直做到caption的细粒度对齐。
- 大规模,多任务的训练,多显卡高算力。可以看一下OpenAI发布的必看论文 CLIP,DALL-E,论文解读传送门。
- 下游任务丰富。
- 个人偏向于单流模型,参数较少较轻便且端到端,性能不差。
Cross-modal Pretraining in BERT(跨模态预训练)_上杉翔二的博客-CSDN博客_基于跨模态知识提取与融合的模型预训练方法
![[LeetCode 1781]所有子字符串美丽值之和](https://img-blog.csdnimg.cn/448d58cb17f64ff8b7d108db552dd9af.png)