问题发现:
1、正常上班的一天,突然间有运营同事反馈,我们在添加数据的时候,发现添加了🐸之后,对应的💩没有了,添加了💩然后🐸就没有了,需要研发帮忙分析一下为什么。
原因分析:
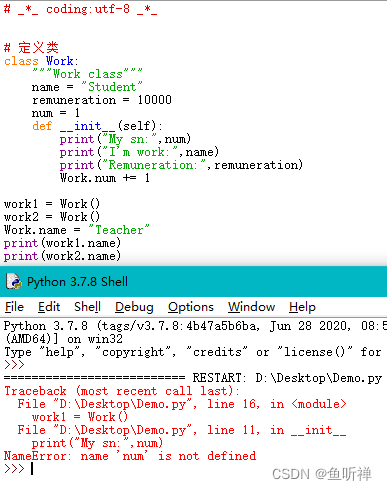
1、从运营的反馈我第一印象应该是前端搞错了,把本应该调用新增的接口调错成了修改接口,于是让前端先排查,前端反馈新增和修改是同一个接口,这着实让我心头一紧,咋回事?程序BUG了?
2、一通排查一下了,程序并没有发现什么问题,可为什么会被替换了?只能继续向后排查,那就到了MySQL了。我们使用的是INSERT INTO ON DUPLICATE KEY UPDATE,针对该字段使用了唯一索引,如果发现存在相同的值就直接替换掉,建表语句如下:
CREATE TABLE `du_test` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`tt` VARCHAR(50) NOT NULL DEFAULT '' COLLATE 'utf8mb4_general_ci',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `tt` (`tt`) USING BTREE
)
COLLATE='utf8mb4_general_ci'
ENGINE=InnoDB
AUTO_INCREMENT=4
;
3、当我们插入了💩以后,再插入一下🐸,就会报唯一键冲突错误:
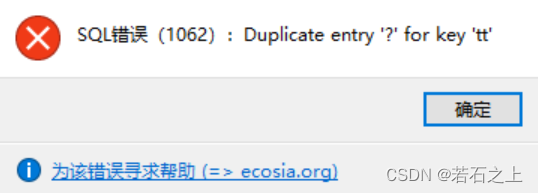
4、明明💩和🐸是不同的字符,单独存储也都没有问题,可为什么在唯一键验证的时候,会报冲突的错误的,这个时候突然间想起来了字符集的比较规则,也就是MySQL的关键字:
COLLATE='utf8mb4_general_ci'
utf8mb4 默认排序规则是utf8mb4_general_ci,它只区分 BMP 字符,而我们的emoji字符其实不在这个范围内的,也就是唯一索引校验的时候,根本就不会对带上emoji字符,知道原因之后,那就需要找一种能处理emoji字符的比较规则。
解决方案:
1、_bin的比较规则是怎么比较的?
二进制字符串是字节序列。对于binary collation,比较和排序基于字节数字值。非二进制字符串(CHAR, VARCHAR,TEXT )是字符序列,可能是多字节的。非二进制字符串的比较规则定义了用于比较和排序的字符值的顺序。对于_bin collation,这种排序基于字符代码数字值,这与二进制字符串的排序类似,只是字符代码值可能是多字节的。
2、修改原来的字段的字符集为utf8mb4_bin,问题解决
CREATE TABLE `du_test_1` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`tt` VARCHAR(50) NOT NULL DEFAULT '' COLLATE 'utf8mb4_bin',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `tt` (`tt`) USING BTREE
)
COMMENT='名单操作历史表'
COLLATE='utf8mb4_bin'
ENGINE=InnoDB
AUTO_INCREMENT=8
;
3、测试:
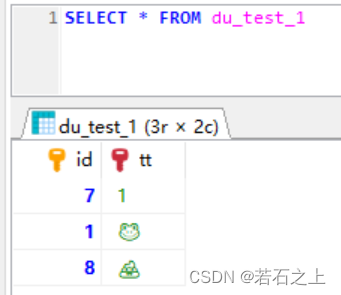
从上图可以看到,🐸和💩都正常插入进去了。
最后:
很多文档或者工具把MySQL的COLLATE翻译成排序规则,我认为稍微有点欠妥,或者说不够直观,其实它的英文是“perform comparisons according to a variety of collations”,翻译成比较规则更合适一些,需要排序的场景肯定需要比较,需要比较的场景不一定需要排序。

![[毕业设计]2022-2023年最新最全计算机专业毕设选题推荐汇总](https://img-blog.csdnimg.cn/887a898b20664b399694dcf15cedcd68.png)