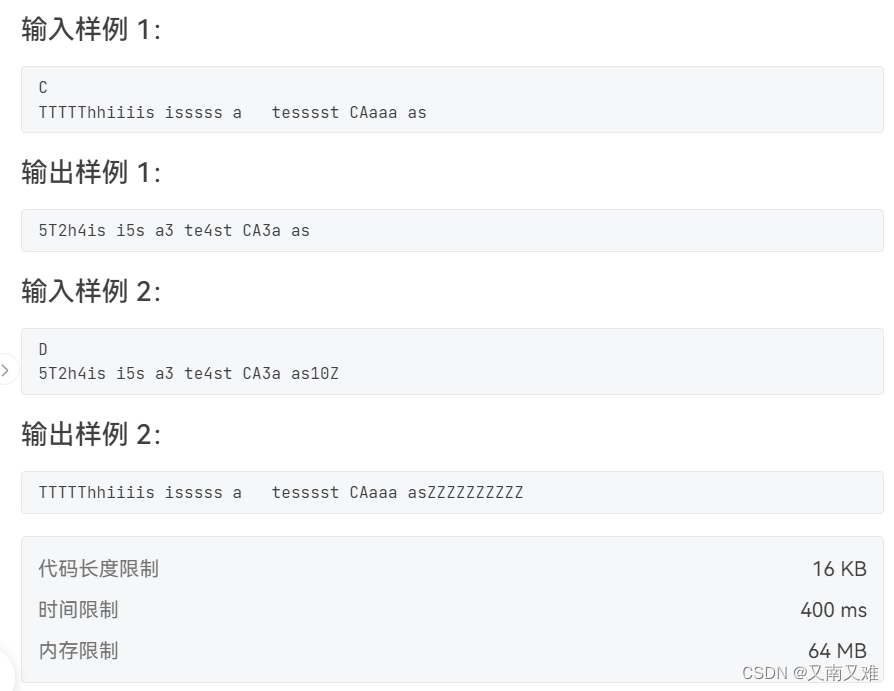
https://arxiv.org/abs/2102.05918
【写在前面】
学习良好的视觉和视觉语言表征对于解决计算机视觉问题(图像检索、图像分类、视频理解)是至关重要的,目前,预训练的特征在许多NLP任务中已经展现了非常大的潜力。虽然NLP中的表示学习已经可以用没有人工注释的原始文本训练,但视觉和视觉语言表示仍然严重依赖于昂贵或需要专家知识的训练数据集。对于视觉任务,特征表示的学习主要依赖具有显式的class标签的数据集,如ImageNet或OpenImages。
对于视觉语言任务,一些使用广泛的数据集像Conceptual Captions、MS COCO以及CLIP都涉及到了数据收集和清洗的过程。这类数据预处理的工作严重阻碍了获得更大规模的数据集。在本文中,作者利用了超过10亿的图像文本对的噪声数据集,没有进行数据过滤或后处理步骤 。基于对比学习损失,使用一个简单的双编码器结构来学习对齐图像和文本对的视觉和语言表示 。
作者证明了,语料库规模的巨大提升可以弥补数据内部存在的噪声,因此即使使用简单的学习方式,模型也能达到SOTA的特征表示。当本文模型的视觉表示转移到ImageNet和VTAB等分类任务时,也能取得很强的性能。对齐的视觉和语言表示支持zero-shot的图像分类,并在Flickr30K和MSCOCO图像-文本检索基准数据集上达到了SOTA的结果。
1. 论文和代码地址

Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
论文地址:https://arxiv.org/abs/2102.05918
代码地址:未开源
2. Motivation
在现有工作中,视觉和视觉语言表示学习大多是分别使用不同的训练数据源进行研究的。在视觉领域,对大规模监督数据(如ImageNet、OpenImages和JFT-300M)进行预训练对提高下游任务的性能是至关重要的。获得这种预训练的数据集需要在数据收集、采样和人工标注方面进行大量的工作,数据获取成本非常大,因此难以扩展。
预训练也是视觉语言建模的方法。然而,视觉语言的预训练数据集,如Conceptual Captions、Visual Genome Dense Captions和 ImageBERT,需要在人类标注、语义解析、清理和平衡方面进行更重的工作。因此,这些数据集的规模仅在10M个样本左右。这至少比视觉领域的数据集小一个数量级,而且比预训练的NLP数据集也小得多。
在这项工作中,作者利用了超过10亿个有噪声的图像文本对的数据集来扩展视觉和视觉语言表示学习。作者采用了Conceptual Captions的方式来获取一个大的噪声数据集。与其不同的是,作者没有用复杂的数据滤波和后处理步骤来清理数据集,而是只应用简单的基于数据频率的过滤。虽然得到的数据集有噪声,但比Conceptual Captions数据集大两个数量级。作者发现,在这样的大规模噪声数据集上预训练的视觉和视觉语言表示在广泛的任务上取得了非常强的性能。
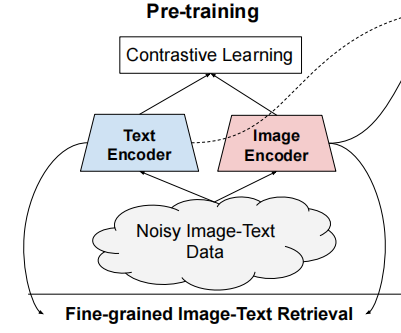
作者基于在一个共享的embedding空间中对齐视觉和语言表示的训练目标,使用一个简单的双编码器体系结构来训练模型。作者将这个模型命名为ALIGN(A L arge-scale I maG e and N oisy-text embedding),图像和文本编码器是通过对比损失函数学习的,将匹配的图像文本对的embedding推在一起,同时将不匹配的图像文本对的embedding分开。
这也是自监督和监督表示学习的最有效的损失函数之一。考虑到ALIGN用文本作为图像的细粒度标签,因此图像对文本的对比损失类似于传统的基于标签的分类目标;关键的区别在于这里的label是由文本编码器生成“标签”权重,而不是像ImageNet那样离散的标签。(ALIGN的模型结构如上图所示)

对齐的图像和文本表示自然适用于跨模态匹配/检索任务,并在相应的基准数据集测试中实现了SOTA结果。此外,这种跨模态匹配也适用于zero-shot图像分类,在不使用任何训练样本的情况下,在ImageNet中获得了76.4%的Top-1准确率 。此外,图像表示在各种下游视觉任务中也取得了不错的性能。例如,ALIGN在ImageNet中达到了88.64%的Top-1准确率 。(上图展示了跨模态检索的示例)
3. 方法
3.1. A Large-Scale Noisy Image-Text Dataset

本文的重点是扩大视觉和语言表示学习的规模。为此,作者创建了一个比现有数据集大得多的数据集。具体来说,作者遵循构建Conceptual Captions数据集的方法,以获得更大规模的图像-文本数据集。
但是,Conceptual Captions数据集还进行了大量的数据过滤和后处理工作,为了获取更大规模的数据,作者通过减轻Conceptual Captions工作中的大部分数据清洗工作来减少数据处理的工作量(作者仅根据数据的频率做了非常简单的数据过滤)。因此,作者获得了一个更大规模的数据集(18亿的图像文本对)。上图展示了数据集中的一些随机采样的例子。
3.2. 预训练与任务迁移

ALIGN的大致框架如上图所示。
3.2.1. 预训练
作者使用双编码器结构用于训练对齐特征,该模型由一对图像编码器和文本编码器组成。作者使用具有全局池化的EfficientNet作为图像编码器,使用带有[CLS] token embedding的BERT作为文本编码器。在BERT编码器的顶部,作者添加了一个带激活函数的全连接层,以匹配图像的维度。
图像和文本编码器都是通过normalized softmax损失函数进行优化。在训练中,将匹配的图像-文本对视为正样本,并将当前训练batch中的其他随机图像-文本对视为负样本。在训练过程中,优化以下两个损失函数:
image-to-text的对比损失:
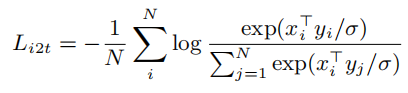
text-to-image的对比损失:

其中,xi和yj的分别是第i个图像和第j个文本的 normalized embedding。N是batch size,σ是temperature系数。在这里,temperature系数是非常重要的,因为图像和文本的embedding都经过了L2-normalized。在本文中,公式中的temperature系数是通过训练来获得,而不是一个超参数。
3.2.2. 任务迁移之Image-Text Matching & Retrieval
作者评估了ALIGN在图像对文本和文本对图像的检索任务上的性能(有finetuning和无finetuning)。测试的数据集包括Flickr30K和MSCOCO。此外,作者也在Crisscrossed Captions (CxC)数据集上测试ALIGN的性能(Crisscrossed Captions是MSCOCO的一个扩展数据集,它对caption-caption、 image-image和image-caption对进行了额外的语义相似性判断)。
通过这些扩展的标注,CxC可以实现四个模态内和模式内的检索任务,包括图像到文本检索、文本到图像检索、文本到文本检索和图像到图像的检索任务,以及三个语义文本相似性任务,包括语义文本相似性(STS)、语义图像相似性(SIS)和语义图像-文本相似度(SITS)。
3.2.3. 任务迁移之 Visual Classification
作者首先将ALIGN基于zero-shot方式应用到视觉分类任务上,数据集包括ImageNet ILSVRC-2012 benchmark、ImageNet-R、ImageNet-A、ImageNet-V2。这些ImageNet数据集变种都是ImageNet的一个子集,ImageNet-R和 ImageNet-A是根据不同的分布对ImageNet采样得到的。
作者还将图像编码器迁移到了下游的视觉分类任务中,为此,作者使用了ImageNet以及一些较小的细粒度分类数据集Oxford Flowers-102、 Oxford-IIIT Pets、Stanford Cars、 Food101。
对于ImageNet,作者展示了来自两个设置的结果:只训练顶级分类层(使用冻结的对齐图像编码器)和完全微调(不冻结的对齐图像编码器)。对于细粒度的分类基准数据集测试,作者只展示了后一种设置的结果。此外,作者还在Visual Task Adaptation Benchmark数据集(由19个不同的视觉分类任务组成,每个任务有1000个训练样本)上测试了模型的鲁棒性。
4.实验
4.1. Image-Text Matching & Retrieval

上表展示了ALIGN在Flickr30K和MSCOCO数据集上基于Zero-shot和fine-tued设置下和其他SOTA方法的对比。可以看出在Zero-shot的设置下,ALIGN在图像检索任务上比CLIP获得了7%以上的性能改进。通过微调,ALIGN的性能大大优于所有现有方法。
4.2. Zero-shot Visual Classification

如果直接将类名的文本输入文本编码器,ALIGN就可以通过图像-文本检索任务对图像进行分类。上表展示了ALIGN和CLIP在不同分类数据集上Zero-Shot的结果,可以看出,相比于CLIP,ALIGN在大多数数据集具备性能上的明显优势。
4.3. Visual Classification w/ Image Encoder Only

上表展示了ALIGN和其他方法在ImageNet数据集上的比较结果。通过冻结参数,ALIGN的性能略优于CLIP,并达到85.5%的SOTA准确率。微调后,ALIGN比BiT和ViT模型获得更高的精度。

上表展示了在VTAB(19个任务)上,ALIGN和BiT-L之间的结果比较。结果表明,采用类似的超参数选择方法,ALIGN的性能优于BiT-L。
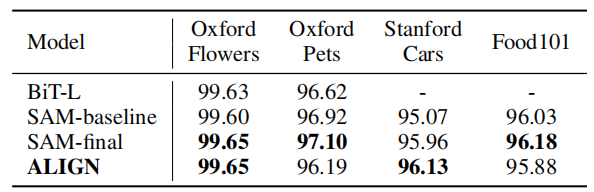
上表展示了不同模型在细粒度分类任务上的迁移学习结果。
4.4. Ablation Study
4.4.1. Model Architectures

上图显示了不同图像和文本Backbone组合下的MSCOCO zero-shot检索和ImageNet KNN结果。

上表展示了一些ALIGN模型变体与baseline模型(第一行)的比较。第2-4行显示,embedding维度越高,模型性能越高。第5行和第6行显示,在softmax损失中使用更少的in-batch negatives(50%和25%)会降低性能。第7-9行研究了temperature参数对softmax损失的影响。
4.4.2. Pre-training Datasets
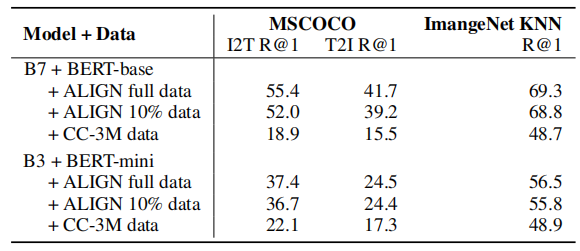
上表的结果表明一个大规模的训练集对于扩展ALIGN模型和实现更好的性能是至关重要的。
4.5. Analysis of Learned Embeddings

作者建立了一个简单的图像检索系统,来研究通过ALIGN训练的embedding行为。上图显示了用不存在于训练集中 text queries进行text-to-image检索的top-1结果。

上图显示了用“图像±文本查询”进行图像检索的结果。
4.6. Multilingual ALIGN Model
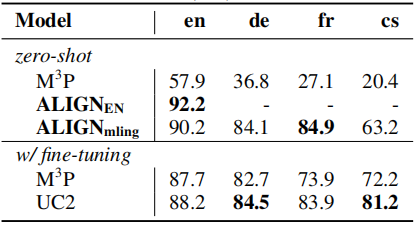
ALIGN的一个优点是,该模型是在有噪声的网络图像文本数据上进行非常简单的过滤之后训练得到的,并且没有对特定语言进行过滤。因此该模型不受语言的约束。上表显示了不同语言下zero-shot和fine-tuning的结果。
5. 总结
在本文中,作者提出了一种简单的方法(ALIGN),利用大规模噪声图像-文本数据来扩大视觉和视觉语言的表示学习。作者避免了对数据预处理和标注的工作量,只需要基于数据频率的简单过滤。
在这个数据集上,作者基于对比学习损失函数训练一个非常简单的双编码器模型ALIGN。ALIGN能够进行跨模态检索,并显著优于SOTA的VSE和基于cross-attention的视觉语言模型。在视觉的下游任务中,ALIGN也可以达到与用大规模标注数据训练的SOTA模型相似的性能,甚至优于SOTA模型。
ICML2021-《ALIGN》-大力出奇迹,谷歌用18亿的图像-文本对训练了一个这样的模型。 - 知乎

![[附源码]计算机毕业设计高校学生宿舍管理系统Springboot程序](https://img-blog.csdnimg.cn/c91debfb7081402fa00d1bd443fede6a.png)