目录
1.clickhouse数据库安装说明
2.clickhouse数据库安装介质
3.clickhouse数据库安装前配置
3.1配置操作系统yum源(可选)
3.2配置NTP客户端
3.3配置sudo、NetworkManager、firewalld、selinux
3.4创建用户
3.5修改系统参数与限制
3.6修改主机名称与host文件
3.7关闭透明大页、调整CPU固定高频、关闭SWAP
4. clickhouse数据库安装
4.1创建目录
4.2安装数据库软件
4.3编辑配置文件
4.4启动数据库
4.5创建数据副本表
4.6创建分布式表
5. zookeeper集群安装
5.1安装要求
5.2创建目录
5.3 安装zookeeper,编辑配置文件
5.4 创建 zookeeper 用户
5.5 启动zookeeper集群
1.clickhouse数据库安装说明
clickhouse提供了集群机制支持,集群有两种实现方式,一是数据副本,即全量数据冗余到另外的机器,提供高可用保证。二是分布式表,即以表为单位将数据分散到多个节点上保存,用以解决单机存储不足问题。
生产环境通常使用数据副本架构,确保数据安全与生产业务的高可用性;对于分布式表,由于数据分布在多个节点,查询可能从多节点获取数据再组合加工,因网络延时等原因查询效率相对较低,也有数据不一致的风险,适用场景较少。
部署clickhouse采用数据副本架构,2台机器作为clickhouse专用服务器,即2个节点保存相同数据;3台机器部署zookeeper集群,为clickhouse数据同步提供服务。因zookeeper对数据延迟非常敏,而clickhouse数据库可能占用所用可用的系统资源,所以强烈推荐生产环境zookeeper与clickhouse使用不同的服务器部署,或者已有zookeeper集群且未超载的情况下,复用现有的zookeeper。
部署clickhouse所需服务器资源配置如下表,生产环境根据实际业务量调整资源配置,推荐使用SSD存储设备。
| 服务器名 | ip | 操作系统 | cpu | 内存 | 用途1 | 用途2 |
| ch01 | 10.82.88.182 | CentOS Linux release 7.9 | 8c | 16G | clickhouse集群 | zookeeper集群 |
| ch02 | 10.82.88.183 | CentOS Linux release 7.9 | 8c | 16G | clickhouse集群 | zookeeper集群 |
| ch03 | 10.82.88.184 | CentOS Linux release 7.9 | 8c | 16G |
| zookeeper集群 |
2.clickhouse数据库安装介质
官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,检查当前CPU是否支持SSE 4.2的命令。
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
服务器CPU检查通过,选择RPM包进行安装,数据库版本使用更加稳定的最新的LTS(Long Term Support)版本 22.8,下载以下3个安装包。
https://packages.clickhouse.com/rpm/stable/
clickhouse-common-static-22.8.9.24.x86_64.rpm
clickhouse-client-22.8.9.24.x86_64.rpm
clickhouse-server-22.8.9.24.x86_64.rpm
3.clickhouse数据库安装前配置
3.1配置操作系统yum源(可选)
通常操作系统以最小化方式安装,配置yum源可以为后续安装软件提供很大的便利。yum源推荐使用内网环境提供的地址,若无法获得,则挂载操作系统安装盘,配置本地yum源。注意yum源需要和操作系统版本相同,安装使用的操作系统为CentOS Linux release 7.9.2009,配置本地yum源操作如下。
挂载光盘文件 CentOS-7-x86_64-Everything-2009.iso,编辑repo文件,注意 "/run/media/root/CentOS\ 7\ x86_64" 替换为对应的挂载路径。
cat >/etc/yum.repos.d/Centos7_local.repo <<EOF
[CentOS7]
name=CentOS-server
baseurl=file:///run/media/root/CentOS\ 7\ x86_64
enabled=1
gpgcheck=0
EOF
3.2配置NTP客户端
根据现网使用的实际ntp server进行调整。
ip=xxx.xxx.xxx.xxx
ntpdate $ip
sed -i "s/server 3.centos.pool.ntp.org/server $ip/g" /etc/chrony.conf
sed -i "s/server 0.centos.pool.ntp.org/#server 0.centos.pool.ntp.org/g" /etc/chrony.conf
sed -i "s/server 1.centos.pool.ntp.org/#server 0.centos.pool.ntp.org/g" /etc/chrony.conf
sed -i "s/server 2.centos.pool.ntp.org/#server 0.centos.pool.ntp.org/g" /etc/chrony.conf
systemctl enable chronyd
systemctl start chronyd
systemctl status chronyd
3.3配置sudo、NetworkManager、firewalld、selinux
echo "clickhouse ALL=(ALL) NOPASSWD: /bin/su - root" >> /etc/sudoers
systemctl disable NetworkManager
systemctl stop NetworkManager
systemctl disable firewalld
systemctl stop firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
3.4创建用户
新建用户,替换命令中的密码,进行密码设置。
groupadd clickhouse
useradd -g clickhouse clickhouse
echo "umask 022" >> /home/clickhouse/.bash_profile
echo "xxxx" | passwd --stdin clickhouse
3.5修改系统参数与限制
cat >> /etc/security/limits.conf << EOF
* soft nproc 65536
* hard nproc 65536
* soft nofile 655360
* hard nofile 655360
EOF
3.6修改主机名称与host文件
根据实际情况修改主机名,3台机器分别执行:
hostnamectl set-hostname ch01
hostnamectl set-hostname ch02
hostnamectl set-hostname ch03
cat >> /etc/hosts << EOF
10.82.88.182 ch01
10.82.88.183 ch02
10.82.88.184 ch03
EOF
每台机器的名称和IP映射关系都需要写入到host文件中,zookeeper集群机器IP信息也需要写入到host文件。
3.7关闭透明大页、调整CPU固定高频、关闭SWAP
查看是否使用透明大页
cat /sys/kernel/mm/transparent_hugepage/enabled
查看CPU频率策略
cpupower frequency-info --policy
a.执行 tuned-adm list 命令查看当前操作系统的 tuned 策略。
b.创建新的 tuned 策略。
mkdir /etc/tuned/balanced-ch-optimal/
cat > /etc/tuned/balanced-ch-optimal/tuned.conf <<EOF
[main]
include=balanced
[cpu]
governor=performance
[vm]
transparent_hugepages=never
EOF
c.应用新的 tuned 策略。
tuned-adm profile balanced-ch-optimal
修改后检查:
cat /sys/kernel/mm/transparent_hugepage/enabled
cpupower frequency-info --policy
关闭swap
echo "vm.swappiness = 0">> /etc/sysctl.conf
swapoff -a && swapon -a
sysctl -p
调整内存分配策略
echo 0 | sudo tee /proc/sys/vm/overcommit_memory
至此,完成操作系统相关设置,下一章节进行数据库安装。
4. clickhouse数据库安装
数据库集群部署在节点ch01 (10.82.88.182)与ch02(10.82.88.183),需要在两个节点均执行以下操作。
4.1创建目录
创建clickhouse日志目录与数据文件目录,可根据实际情况调整。
mkdir -p /opt/clickhouse_logs
mkdir -p /opt/clickhouse
chown -R clickhouse:clickhouse /opt/clickhouse_logs
chown -R clickhouse:clickhouse /opt/clickhouse
4.2安装数据库软件
上传安装包,检查安装包md5值
md5sum clickhouse-common-static-22.8.9.24.x86_64.rpm
f3c6bb13102ca5418b778b9f6ce7c3bf clickhouse-common-static-22.8.9.24.x86_64.rpm
md5sum clickhouse-client-22.8.9.24.x86_64.rpm
44bfe6eb388905c2037ce3e6717b3e4c clickhouse-client-22.8.9.24.x86_64.rpm
md5sum clickhouse-server-22.8.9.24.x86_64.rpm
c1acc4debcc1fab2ee0257b8689d140a clickhouse-server-22.8.9.24.x86_64.rpm
依次执行
rpm -ivh clickhouse-common-static-22.8.9.24.x86_64.rpm
rpm -ivh clickhouse-client-22.8.9.24.x86_64.rpm
rpm -ivh clickhouse-server-22.8.9.24.x86_64.rpm
在安装clickhouse-server-22.8.9.24.x86_64.rpm时需要输入数据库用户default的密码,请输入并记住密码,后续登录数据库需要使用。

至此,完成数据库软件安装。
数据库的默认配置文件目录是 /etc/clickhouse-server
默认日志目录是 /var/log/clickhouse-server/
默认数据文件目录是 /var/lib/ clickhouse
默认提供sytemclt启停,先不启动数据库,编辑配置文件后再启动数据库,数据库在启动时会自动初始化。
4.3编辑配置文件
clickhouse安装后生成两个配置文件,/etc/clickhouse-server/ config.xml 服务器级配置文件;/etc/clickhouse-server/ users.xml 用户级配置文件。
4.3.1编辑 /etc/clickhouse-server/config.xml
可以使用vi /etc/clickhouse-server/config.xml 修改文件,或者使用sed命令,注意本文件属性为只读,vi保存时需要使用 wq!
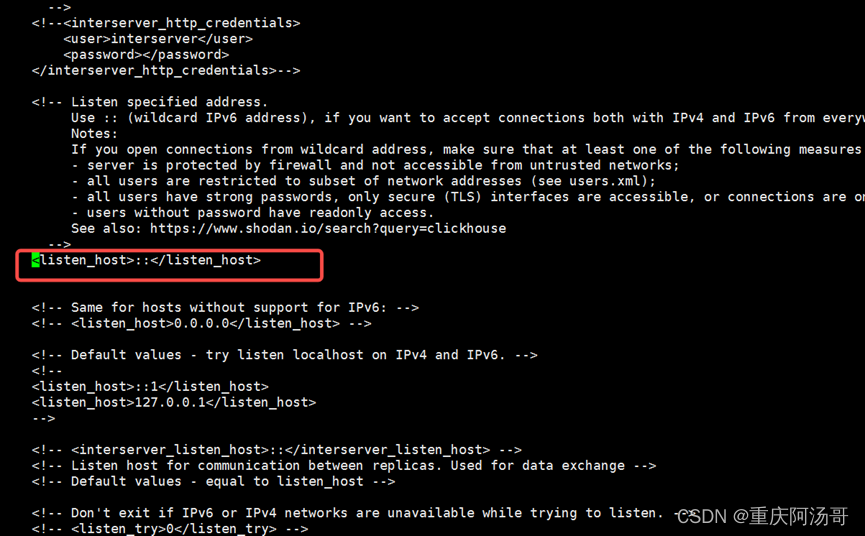
(1)允许远程访问
<!-- <listen_host>::</listen_host> --> 去掉注释。
sed -i 's/<!-- <listen_host>::<\/listen_host> -->/<listen_host>::<\/listen_host>/g' /etc/clickhouse-server/config.xml
修改后入下图:
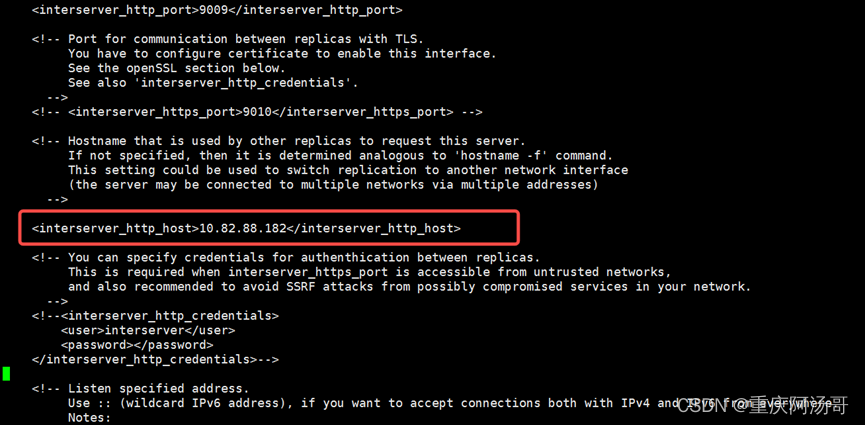
(2)interserver_http_host去掉注释,修改为本机IP,注意两节点IP不相同。
修改前:
<!--
<interserver_http_host>example.clickhouse.com</interserver_http_host>
-->
修改后ch01节点如下图:
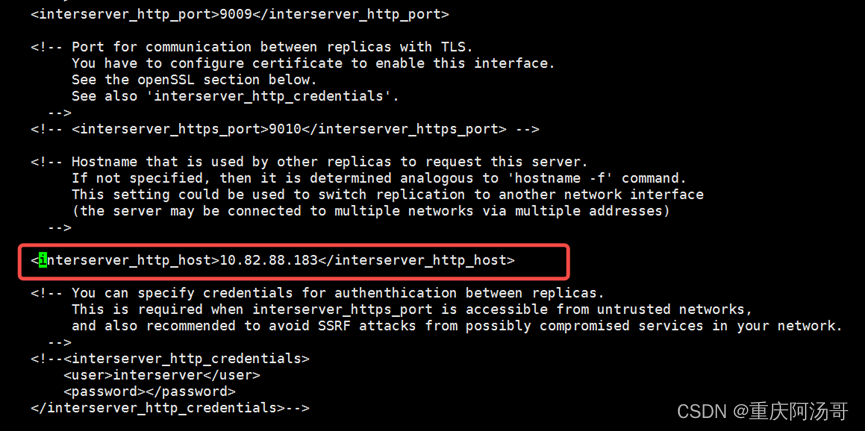
修改后ch02节点如下图:
(3)启用zookeeper
找到zookeeper相关内容,修改前如下图:

zookeeper相关内容默认处于注释状态,使用zookeeper则要去掉注释,并且修改host中example1,example2,example3分别为zookeeper集群3个节点的IP(10.82.88.182/183/184)。修改后如下图:

(4)启用宏(macros)
找到macros相关内容,修改前如下图:

macros相关内容默认处于注释状态,使用macros则去掉注释;修改example01-01-1为本节点的主机名,不同节点值不同,比如节点ch01把example01-01-1修改为ch01,节点ch02把example01-01-1修改为ch02。
ch01节点修改后如下图:
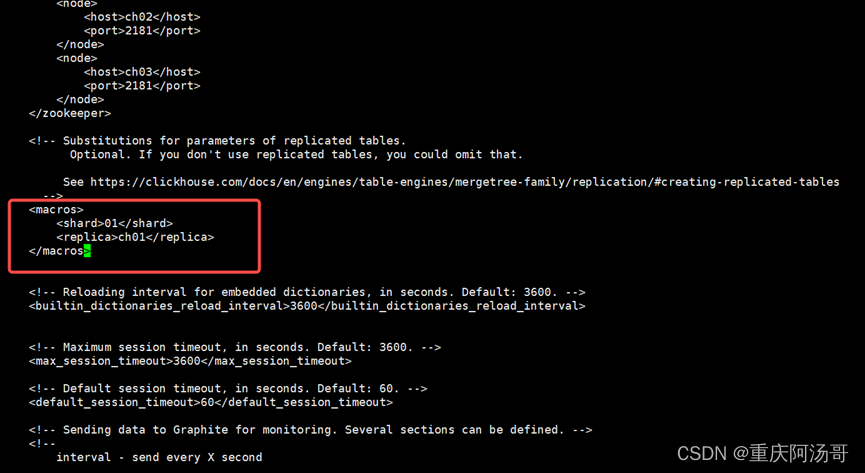
ch02节点修改后如下图:

(5)修改目录
日志默认路径是 /var/log/clickhouse-server ,修改为/opt/clickhouse_logs,根据实际情况修改。
数据默认路径是 /var/lib/clickhouse ,修改为/opt/clickhouse,可根据实际情况修改。
修改命令:
sed -i 's/\/var\/log\/clickhouse-server/\/opt\/clickhouse_logs/g' /etc/clickhouse-server/config.xml
sed -i 's/\/var\/lib\/clickhouse/\/opt\/clickhouse/g' /etc/clickhouse-server/config.xml
4.3.2编辑 /etc/clickhouse-server/user.xml
以下参数需要调优,具体参数值根据实际情况进行调整。
background_pool_size :后台线程数,默认16,建议调整为cpu逻辑线程数的2倍(cpu逻辑线程数cat /proc/cpuinfo |grep processor|wc -l)。
background_distributed_schedule_pool_size :分布式后台任务线程数,默认16,建议改成cpu个数的2倍(线程数)。
max_memory_usage :单次查询可使用的内存最大值,clickhouse数据库专用服务器可以设置为服务器内存的60%以上。
max_memory_usage_for_all_queries : 所有查询可使用的内存最大值,建议与 max_memory_usage 相同。
max_bytes_before_external_group_by :group by 内存量使用量,建议设置为 max_memory_usage的一半,当group by使用内存超过设置值后会使用磁盘进行排序。
max_bytes_before_external_sort : order by 内存使用量,建议与max_bytes_before_external_group_by相同,当order by使用内存超过设置值后会使用磁盘进行排序。
执行如下命令:
sed -i '/<load_balancing>/i\ <max_memory_usage>10737418240</max_memory_usage>' /etc/clickhouse-server/users.xml
sed -i '/<load_balancing>/i\ <max_memory_usage_for_all_queries>10737418240</max_memory_usage_for_all_queries>' /etc/clickhouse-server/users.xml
sed -i '/<load_balancing>/i\ <max_bytes_before_external_group_by>5368709120</max_bytes_before_external_group_by>' /etc/clickhouse-server/users.xml
sed -i '/<load_balancing>/i\ <max_bytes_before_external_sort>5368709120</max_bytes_before_external_sort>' /etc/clickhouse-server/users.xml
sed -i '/<load_balancing>/i\ <background_pool_size>16</background_pool_size>' /etc/clickhouse-server/users.xml
sed -i '/<load_balancing>/i\ <background_distributed_schedule_pool_size>16</background_distributed_schedule_pool_size>' /etc/clickhouse-server/users.xml
增加default用户访问权限
sed -i 's/<!-- <access_management>1<\/access_management> -->/<access_management>1<\/access_management>/g' /etc/clickhouse-server/users.xml
执行后如下图:
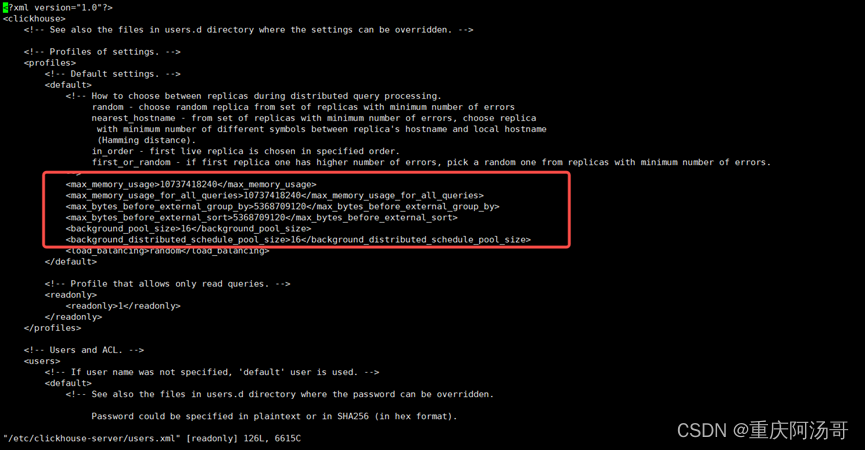
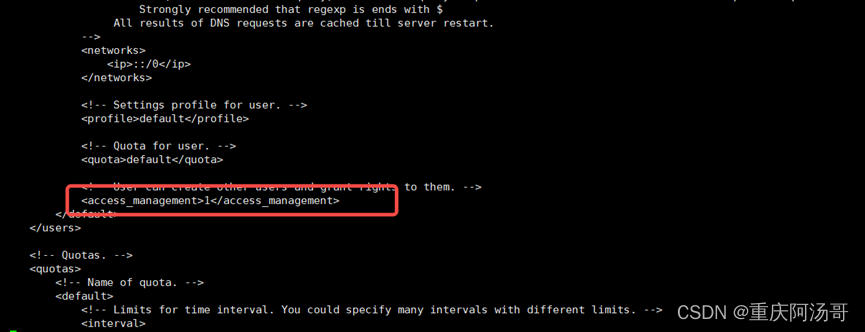
4.4启动数据库
zookeeper启动后方可启动clickhouse数据库,若还未安装zookeeper集群,请先安装并启动。zookeeper安装部署请参见第5章。
systemclt 相关命令如下:
systemctl start clickhouse-server
systemctl stop clickhouse-server
systemctl restart clickhouse-server
systemctl status clickhouse-server
clickhouse-client登录命令:
clickhouse-client --host 10.82.88.182 -m --password xxxx
4.5创建数据副本表
副本的目的是保障数据的高可用。当一台clickhouse节点宕机了,可以从其他备份服务器获得相同的数据。clickhosue只有MergeTree系列的表引擎可以支持副本。针对MergeTree系列的表引擎,clickhouse都提供了对应的Replicated*MergeTree表引擎来支持数据副本。
clickhouse的数据副本机制是表级别的,也就是说只针对表进行复制,一个数据库中可以同时包含复制表和非复制表。副本机制对于select查询是没有影响的,查询复制表和非复制表的速度是一样的。而写入数据时,clickhouse的集群没有主从之分,大家都是平等的。只不过配置了复制表后,insert以及alter操作会同步到对应的副本机器中。
搭建两节点clickhouse,通过zk进行数据同步,创建库表的操作需要在两节点执行。分别登录到两节点创建数据库和表,执行如下语句。
create database test;
use test;
create table t_stock(id UInt32,sku_id String,total_amount decimal(16, 2),create_time datetime) engine = ReplicatedMergeTree('/clickhouse/tables/test/t_stock','{replica}') primary key id ;
建表语句语法:
create table table_name(...) engine=ReplicatedMergeTree('zoo_path','replica_name')
引擎使用 ReplicatedMergeTree ,zoo_path为 /clickhouse/tables/test/t_stock ,是ZooKeeper中该表的路径 ; replica_name为 {replica} ,是ZooKeeper 中的该表的副本名称。
复制表路径必须一致,"/clickhouse/tables"为固定前缀,"test"是库名,"t_stock"是表名
副本名称必须不相同,所以使用宏 {replica},创建时匹配配置文件中的值。
在某个节点写入数据,数据会自动同步到另外一个节点。
insert into t_stock values(1,'10000',2000,'2022-12-12');
如果删除表drop table 需要加sync。
drop table t_stock sync;
4.6创建分布式表
完成步骤4.1-4.4后,编辑配置文件/etc/clickhouse-server/config.xml,使用分布式表。找到config.xml中 remote_servers 部分,删除<remote_servers> </remote_servers>之间所有内容,加入以下内容。
<bigdata>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>10.82.88.182</host>
<port>9000</port>
<user>default</user>
<password>xxx</password>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>false</internal_replication>
<replica>
<host>10.82.88.183</host>
<port>9000</port>
<user>default</user>
<password>xxx</password>
</replica>
</shard>
</bigdata>
<host>10.82.88.182</host>为clickhouse的IP,根据实际情况修改,<port>9000<port>,<user>default</user>是数据库用户,<password>xxx</password>是安装rpm包时输入的密码。配置了2个分片,分别节点为10.82.88.182和10.82.88.183,权重相等都是1,若有更多分片,可以再此基础上增加。每个节点均进行相同配置,然后重启数据库
登录到任意一台数据库,执行语句创建库表,语句使用“on cluster saxo”,在每个分片节点创建相同的库表,t_stock_local为本地表,是数据实际存储位置;t_stock_distributed为分布式表,是本地表的映射表。
分布式表中ENGINE = Distributed(saxo,test02,t_stock_local,hiveHash(sku_id)),saxo为集群名称,test02为数据库名,t_stock_local为本地表名,hiveHash(sku_id)分片键。
create database test02 on cluster saxo;
use test02;
CREATE TABLE t_stock_local on cluster saxo
(
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time DateTime
)
ENGINE = MergeTree()
PRIMARY KEY id
ORDER BY (id, sku_id);
CREATE TABLE t_stock_distributed on cluster saxo
(
id UInt32,
sku_id String,
total_amount Decimal(16, 2),
create_time DateTime
)
ENGINE = Distributed(saxo,test02,t_stock_local,hiveHash(sku_id));
insert into t_stock_distributed values (1,101,1000,'2022-12-08');
insert into t_stock_distributed values (2,102,1000,'2022-12-08');
insert into t_stock_distributed values (3,103,1000,'2022-12-08');
insert into t_stock_distributed values (4,104,1000,'2022-12-08');
insert into t_stock_distributed values (5,105,1000,'2022-12-08');
insert into t_stock_distributed values (6,106,1000,'2022-12-08');
insert into t_stock_distributed values (7,107,1000,'2022-12-08');
insert into t_stock_distributed values (8,108,1000,'2022-12-08');
insert into t_stock_distributed values (9,109,1000,'2022-12-08');
insert into t_stock_distributed values (10,110,1000,'2022-12-08');
insert into t_stock_distributed values (11,111,1000,'2022-12-08');
insert into t_stock_distributed values (12,112,1000,'2022-12-08');
往分布式表t_stock_distributed中写入数据,其他分片节点查询t_stock_distributed获取全量数据,同时查询到本地表t_stock_local只包含部分数据。
5. zookeeper集群安装
zookeeper集群安装节点为10.82.88.182、10.82.88.183、10.82.88.184,需要在3个节点均执行创建目录,安装软件、编辑配置文件、创建用户、启动集群等操作。
5.1安装要求
clickhouse要求zookeeper版本不低于3.4.5,下载最新稳定版本 apache-zookeeper-3.7.1-bin.tar.gz。下载链接:
https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
zookeeper需要JDK环境支持,自行安装一个jdk8即可

5.2创建目录
mkdir /opt/zookeeper/
mkdir -p /opt/zookeeper/cluster_clickhouse/data
mkdir -p /opt/zookeeper/cluster_clickhouse/log
5.3 安装zookeeper,编辑配置文件
tar -xvf apache-zookeeper-3.7.1-bin.tar.gz
mv apache-zookeeper-3.7.1-bin /opt/zookeeper/zookeeper-3.7.1
根据clickhouse官方推荐,调整zookeeper相关参数
cat > /opt/zookeeper/zookeeper-3.7.1/conf/zoo.cfg << EOF
dataDir=/opt/zookeeper/cluster_clickhouse/data/
dataLogDir=/opt/zookeeper/cluster_clickhouse/log/
clientPort=2181
tickTime=2000
initLimit=30000
syncLimit=10
maxClientCnxns=2000
maxSessionTimeout=60000000
autopurge.snapRetainCount=10
autopurge.purgeInterval=1
preAllocSize=131072
snapCount=3000000
server.1=10.82.88.182:2888:3888
server.2=10.82.88.183:2888:3888
server.3=10.82.88.184:2888:3888
EOF
节点ch01执行
echo 1 > /opt/zookeeper/cluster_clickhouse/data/myid
节点ch02执行
echo 2 > /opt/zookeeper/cluster_clickhouse/data/myid
节点ch03执行
echo 3 > /opt/zookeeper/cluster_clickhouse/data/myid
5.4 创建 zookeeper 用户
groupadd zookeeper
useradd -g zookeeper zookeeper
echo "umask 022" >> /home/zookeeper/.bash_profile
echo "xxxx" | passwd --stdin zookeeper
echo "zookeeper ALL=(ALL) NOPASSWD: /bin/su - root" >> /etc/sudoers
chown -R zookeeper:zookeeper /opt/zookeeper
5.5 启动zookeeper集群
三台机器分别执行su - zookeeper
/opt/zookeeper/zookeeper-3.7.1/bin/zkServer.sh start
启动完成后查看状态
/opt/zookeeper/zookeeper-3.7.1/bin/zkServer.sh status
应为1个leader,2个follower
集群启停命令
/opt/zookeeper/zookeeper-3.7.1/bin/zkServer.sh start
/opt/zookeeper/zookeeper-3.7.1/bin/zkServer.sh stop
/opt/zookeeper/zookeeper-3.7.1/bin/zkServer.sh restart
/opt/zookeeper/zookeeper-3.7.1/bin/zkServer.sh status





![[附源码]Python计算机毕业设计SSM基于大数据的汽车流量监控(程序+LW)](https://img-blog.csdnimg.cn/ab3714f2beda4528b2f382b32b843dfd.png)