2022 CCF BDCI 数字安全公开赛「Web攻击检测与分类识别」赛题@Cyan战队获奖方案
地址:http://go.datafountain.cn/4Zj
团队简介
团队成员来自中国科学院大学,对数据挖掘与网络安全有浓厚兴趣,曾多次获得大数据安全分析等比赛的Top名次。希望通过此次比赛,巩固数据挖掘知识,提升相关技能,同时认识更多优秀的同学,相互交流,共同进步!

摘要
针对本次Web攻击检测与分类识别问题,本团队通过数据分析、特征工程与模型构建的流程实现基于HTTP报文的Web攻击检测与分类识别。首先,对所提供的样本数据进行详细的分析与梳理,并从Web攻击的角度分析数据字段与攻击类型间的关联;然后通过特征工程,提取出拆分特征、统计特征、TF-IDF特征三类有效特征;最后的模型构建部分,对数据不平衡进行处理的同时,采用LightGBM模型对平衡后的训练数据进行特征学习,并对测试样本进行预测,最终模型的Macro F1值达到了0.96861578,并且测试速度仅需0.695 ms/样本,实现快速准确的Web攻击检测与分类识别。
关键词
数据挖掘、机器学习、Web攻击检测
背景介绍
如今,随着Web攻击数量的日益增加,传统威胁检测手段通过分析已知攻击特征进行规则匹配,无法检测未知漏洞或攻击手法。如何快速准确地识别未知威胁攻击并且将不同攻击正确分类,对提升Web攻击检测能力至关重要。利用AI技术对攻击报文进行识别和分类已经成为解决该问题的创新思路,同时也有利于推动AI技术在威胁检测分析场景的研究与应用。
本次Web攻击检测与分类识别任务主要是依据给出的HTTP报文样本,对Web攻击进行检测与分类。在对训练集进行分析的基础上,通过特征工程、机器学习等方法构建AI模型,实现对每一条样本正确且快速的分类。
方案设计
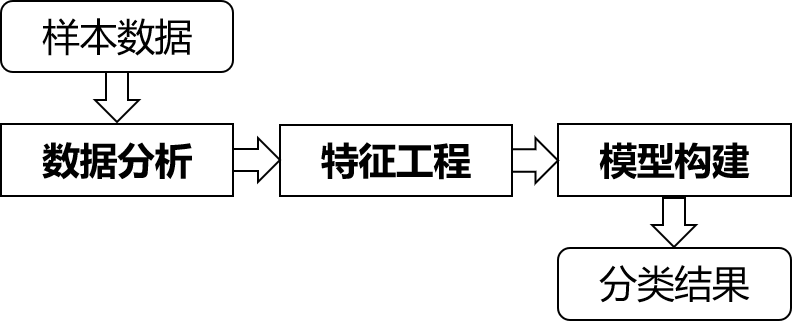
图1:方案设计框架
如图1所示,本团队对该赛题的主要思路可以主要分为三个部分,数据分析部分将对所提供的Method、User Agent、URL、Refer、Body进行分析,从Web攻击的角度分析数据字段与攻击类型的关联;特征工程部分则针对性地对所提供的数据字段进行特征工程,挖掘与攻击类型相关的特征,并根据分析结果对特征进行对应的处理;最后的模型构建部分则通过构建相应模型进行特征学习,并对测试样本进行预测,从而获得Web攻击类型的最终预测结果。
2.1 数据分析
数据分析部分,首先本次赛题是一个多分类任务,所提供的数据为HTTP报文样本,报文的类别可分为白样本以及SQL注入、XSS跨站脚本、命令执行、目录遍历、远程代码执行五种黑样本

图2:各类别样本数量
如图2可知,各个类别的样本的数量并不平衡,其中SQL注入的报文样本最多(为14038个)、XSS跨站脚本的报文样本最少(为659个),在后续部分也会做相应的数据不平衡处理。
从数据字段与攻击类型关联的角度,不同的攻击类型在字段中所呈现的特征也有所不同,在后续部分也会针对与攻击类型关联的特定的字符特征对各个字段进行统计,以达到Web攻击检测与分类的目的。
2.2 特征工程
特征工程部分,这里我针对所有字段均进行了特征构造,所构造的特征大致可分为拆分特征、统计特征、TF-IDF特征三类。
拆分特征主要是不同字段的文本信息中相应字段的拆分特征,如User Agent中的browser信息、os信息、device信息以及URL和Refer中的netloc信息、params信息、query信息等;
统计特征则是对不同字段中指定文本的统计信息,包含各个字段的长度、特殊字符个数、大小写字符个数、URL参数个数、URL参数长度等以及各个字段中与攻击相关的可疑字符统计,如:select个数、exec个数、script个数、eval个数等;
TF-IDF特征则是将单个样本字段看作一段文本,评估经过分词后的单词在这段文本中的重要程度,如果某个单词在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF特征包含了User Agent、URL、URL Path、URL Query、Refer、Body的TF-IDF特征。
2.3 模型构建
模型构建部分,首先对数据分析部分所发现的数据不平衡问题进行相应处理,这里采用的是SMOTE(Synthetic Minority Over-Sampling Technique,合成少数类过采样技术)方法。如图3所示,该算法的思想是针对少数类样本,在它的K近邻中随机选择一个样本,并在特征空间中两个样本之间随机选择的点创建合成样本,使得合成样本保证差异性的同时且与原始样本相近,通过SMOTE算法的不平衡处理,使得所有类别的样本数量能够保持一致,便于后面模型的学习。
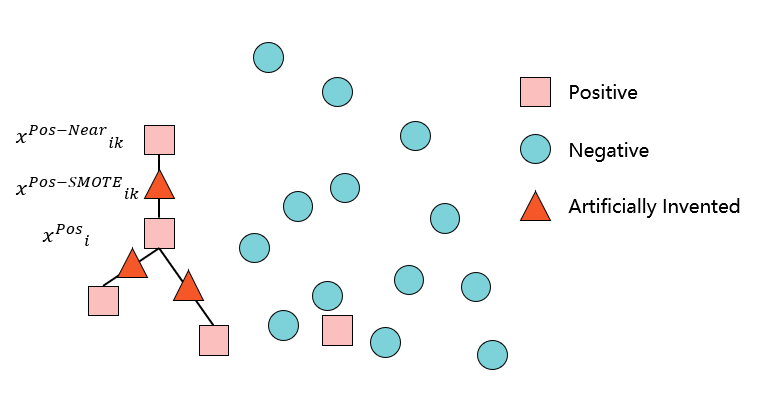
图3:SMOTE算法
在模型选择方面,这里选择的采用Macro F1指标优化的是LightGBM模型,LightGBM模型是一种基于梯度提升的决策树模型,同时也被广泛应用于学术界以及工业界。其中,验证策略采用的是如图4所示的十折分层交叉验证,保证了每一折的数据中各类别样本的比例保持一致。
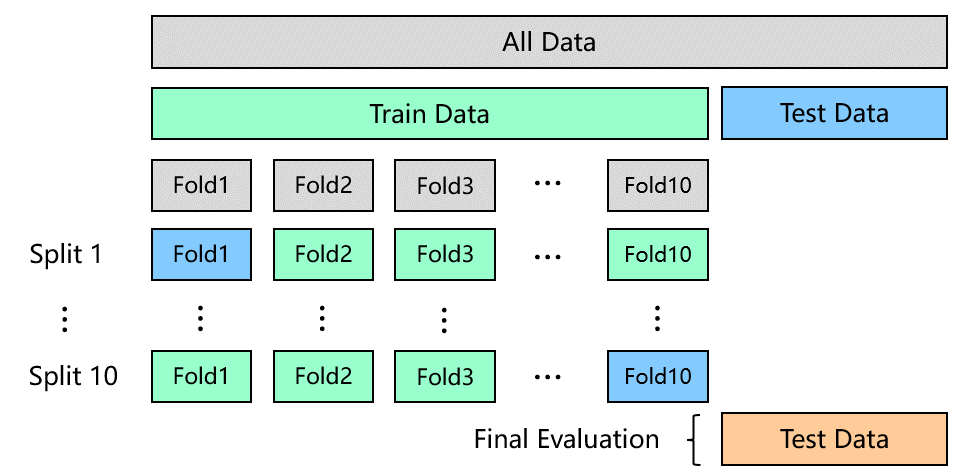
图4:十折分层交叉验证
实验结果
模型训练与测试均在Intel Core i5-10500 CPU、8GB RAM上进行,最终模型的线上Macro F1为0.96861578,整体模型的大小为64.9MB,模型对所有测试样本的测试时间为2.78s,平均每个测试样本的预测速度为0.695 ms/样本。
总结
首先,本方案从Web攻击的角度针对性地对所提供的数据字段进行了分析与梳理,并从中提取出拆分特征、统计特征、TF-IDF特征三类关键特征;
其次,针对训练数据类别不平衡的问题,对训练数据进行了平衡处理,弥补数据不平衡导致的样本量少的分类所包含的信息过少的问题;
最后,使用采用Macro F1指标优化的LightGBM单模型对平衡后的数据进行建模,相较于多个不同模型,使用LightGBM单模型的速度更快,能更好的对Web请求进行快速检测与分类。
致谢
感谢大数据协同安全技术国家工程研究中心、清华大学网络研究院-北京奇虎科技有限公司网络空间测绘联合研究中心、360信息安全中心对本赛题的悉心筹备,感谢中国计算机学会与DataFountain所提供优质的比赛平台,感谢评委专家的悉心评审与指导。
参考
[1] Yun-tao Z, Ling G, Yong-cheng W. An improved TF-IDF approach for text classification[J]. Journal of Zhejiang University-Science A, 2005, 6(1): 49-55.
[2] Xuan C D, Nguyen H D, Nikolaevich T V. Malicious URL Detection based on Machine Learning[J]. International Journal of Advanced Computer Science and Applications, 2020, 11(1): 6.
[3] Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of artificial intelligence research, 2002, 16: 321-357.
[4] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[J]. Advances in neural information processing systems, 2017, 30: 3146-3154.