100 鲜为人知的 Python 功能
这篇文章是为那些每天使用 Python,但从未真正坐下来通读所有文档的人准备的。
如果您已经使用 Python 多年,并且知道足够多的知识来完成工作,那么为了发现一些新技巧而通读几千页的文档可能不是明智之举。
因此,我列出了一个简短的(比较而言)功能列表,其中包括一些未被广泛使用,但广泛适用于一般编程任务的功能。
当然,这份清单会包含一些你已经知道的东西,也有一些你永远不会用到的东西,但我希望其中有一些对你来说是新的和有用的。
首先,做一下内务整理:
使用的 Python 3.8或以上版本。对于在此之后添加的一些功能,我会说明它们是何时添加的;
列表没有严格的顺序,但更基本的特性会放在开头;
如果你想消除我的好奇心,回复序号显示你认为有用的功能的标题。 现在,开始列表...
-
help(x)
help 可以接收字符串、对象或任何内容。对于类实例,它会收集所有父类的方法,并显示哪些方法是从哪里继承来的(以及方法的解析顺序)。
当你想得到一些难以搜索的帮助时,比如^,这也很有用。
输入 help('^') 比查找 Python 文档中描述 ^ 如何工作的部分要快得多。
Operator precedence
*******************
The following table summarizes the operator precedence in Python, from
highest precedence (most binding) to lowest precedence (least
binding). Operators in the same box have the same precedence. Unless
the syntax is explicitly given, operators are binary. Operators in
the same box group left to right (except for exponentiation, which
groups from right to left).
Note that comparisons, membership tests, and identity tests, all have
the same precedence and have a left-to-right chaining feature as
described in the Comparisons section.
+-------------------------------------------------+---------------------------------------+
| Operator | Description |
|=================================================|=======================================|
| "(expressions...)", "[expressions...]", "{key: | Binding or parenthesized expression, |
| value...}", "{expressions...}" | list display, dictionary display, set |
| | display |
+-------------------------------------------------+---------------------------------------+
| "x[index]", "x[index:index]", | Subscription, slicing, call, |
| "x(arguments...)", "x.attribute" | attribute reference |
+-------------------------------------------------+---------------------------------------+
| "await x" | Await expression |
+-------------------------------------------------+---------------------------------------+
| "**" | Exponentiation [5] |
+-------------------------------------------------+---------------------------------------+
| "+x", "-x", "~x" | Positive, negative, bitwise NOT |
+-------------------------------------------------+---------------------------------------+
| "*", "@", "/", "//", "%" | Multiplication, matrix |
| | multiplication, division, floor |
| | division, remainder [6] |
+-------------------------------------------------+---------------------------------------+
| "+", "-" | Addition and subtraction |
+-------------------------------------------------+---------------------------------------+
| "<<", ">>" | Shifts |
+-------------------------------------------------+---------------------------------------+
| "&" | Bitwise AND |
+-------------------------------------------------+---------------------------------------+
| "^" | Bitwise XOR |
+-------------------------------------------------+---------------------------------------+
| "|" | Bitwise OR |
+-------------------------------------------------+---------------------------------------+
| "in", "not in", "is", "is not", "<", "<=", ">", | Comparisons, including membership |
| ">=", "!=", "==" | tests and identity tests |
+-------------------------------------------------+---------------------------------------+
| "not x" | Boolean NOT |
+-------------------------------------------------+---------------------------------------+
| "and" | Boolean AND |
+-------------------------------------------------+---------------------------------------+
| "or" | Boolean OR |
+-------------------------------------------------+---------------------------------------+
| "if" – "else" | Conditional expression |
+-------------------------------------------------+---------------------------------------+
| "lambda" | Lambda expression |
+-------------------------------------------------+---------------------------------------+
| ":=" | Assignment expression |
+-------------------------------------------------+---------------------------------------+
-[ Footnotes ]-
[1] While "abs(x%y) < abs(y)" is true mathematically, for floats it
may not be true numerically due to roundoff. For example, and
assuming a platform on which a Python float is an IEEE 754 double-
precision number, in order that "-1e-100 % 1e100" have the same
sign as "1e100", the computed result is "-1e-100 + 1e100", which
is numerically exactly equal to "1e100". The function
"math.fmod()" returns a result whose sign matches the sign of the
first argument instead, and so returns "-1e-100" in this case.
Which approach is more appropriate depends on the application.
[2] If x is very close to an exact integer multiple of y, it’s
possible for "x//y" to be one larger than "(x-x%y)//y" due to
rounding. In such cases, Python returns the latter result, in
order to preserve that "divmod(x,y)[0] * y + x % y" be very close
to "x".
[3] The Unicode standard distinguishes between *code points* (e.g.
U+0041) and *abstract characters* (e.g. “LATIN CAPITAL LETTER A”).
While most abstract characters in Unicode are only represented
using one code point, there is a number of abstract characters
that can in addition be represented using a sequence of more than
one code point. For example, the abstract character “LATIN
CAPITAL LETTER C WITH CEDILLA” can be represented as a single
*precomposed character* at code position U+00C7, or as a sequence
of a *base character* at code position U+0043 (LATIN CAPITAL
LETTER C), followed by a *combining character* at code position
U+0327 (COMBINING CEDILLA).
The comparison operators on strings compare at the level of
Unicode code points. This may be counter-intuitive to humans. For
example, ""\u00C7" == "\u0043\u0327"" is "False", even though both
strings represent the same abstract character “LATIN CAPITAL
LETTER C WITH CEDILLA”.
To compare strings at the level of abstract characters (that is,
in a way intuitive to humans), use "unicodedata.normalize()".
[4] Due to automatic garbage-collection, free lists, and the dynamic
nature of descriptors, you may notice seemingly unusual behaviour
in certain uses of the "is" operator, like those involving
comparisons between instance methods, or constants. Check their
documentation for more info.
[5] The power operator "**" binds less tightly than an arithmetic or
bitwise unary operator on its right, that is, "2**-1" is "0.5".
[6] The "%" operator is also used for string formatting; the same
precedence applies.
Related help topics: lambda, or, and, not, in, is, BOOLEAN, COMPARISON,
BITWISE, SHIFTING, BINARY, FORMATTING, POWER, UNARY, ATTRIBUTES,
SUBSCRIPTS, SLICINGS, CALLS, TUPLES, LISTS, DICTIONARIES, BITWISE
-
1_000_000
您可以使用下划线作为千位分隔符。这使得大数字更易读。
x = 1_000_000
你也可以用这种方式格式化一个数字:
assert f"{1000000:_}" == "1_000_000"
print(f"{1000000:_}")
1_000_000
-
str.endswith() 取一个元组
if filename.endswith((".csv", ".xls", ".xlsx"))
# 做一些事情
startswith() 也是如此,👇是文档中的 endswith
https://docs.python.org/3/library/stdtypes.html#str.endswith
-
isinstance() 获取一个元组
如果要检查对象是否是多个类的实例,不需要多个 isinstance 表达式,只需传递一个类型元组作为第二个参数即可。
Python 3.10 开始 - 使用联合:
assert isinstance(7, (float, int))
assert isinstance(7, float | int)
关于 isinstance 和 union 类型的更多信息:

https://docs.python.org/3/library/functions.html#isinstance
https://docs.python.org/3/library/stdtypes.html#types-union
-
...是一个有效的函数体
我用...表示 "我很快就会处理这个问题"(在提交任何更改之前),用 pass 表示更接近于无操作的意思。
def do_something():
...
-
海象运算符 :=
海象运算符(又名赋值表达式)允许你为变量赋值,但以表达式的形式赋值,这意味着你可以对结果值做一些事情。
这在 if 语句中非常有用,在 elif 语句中更是如此:
if first_prize := get_something():
... # 对 first_prize 执行操作
elif second_prize := get_something_else():
... # 对 second_prize 进行处理
请记住,如果要将结果与其他内容进行比较,则需要用括号将 walrus 表达式包起来,如下所示:
if (first_prize := get_something()) is not None:
... # 对 first_prize 进行操作
elif (second_prize := get_something_else()) is not None:
... # 对 second_prize 进行处理
借用原始 PEP 中的一个例子,这些可以用在很多地方:
filtered_data = [y for x in data if (y := f(x)) is not None]
如果 (y := f(x)) 不是 None
-
语义分析文档 参见文档中的赋值表达式: https://docs.python.org/3/reference/expressions.html#assignment-expressions
-
attrgetter 和 itemgetter
如果需要根据对象的特定属性对对象列表进行排序,可以使用 attrgetter(当需要的值是属性时,例如类实例)或 itemgetter(当需要的值是索引或字典键时)。
例如,按 "score "键对字典列表进行排序:
from operator import itemgetter
scores = [
{"name": "Alice", "score": 12},
{"name": "Bob", "score": 7},
{"name": "Charlie", "score": 17},
]
scores.sort(key=itemgetter("score"))
assert list(map(itemgetter("name"), scores)) == ["Bob", "Alice", "Charlie"]
attrgetter 与之类似,在不使用点符号的情况下使用。它还可以嵌套访问,例如下面例子中的 name.first:
class Name(NamedTuple):
first: str
last: str
class Person(NamedTuple):
name: Name
height: float
people = [
Person(name=Name("Gertrude", "Stein"), height=1.55),
Person(name=Name("Shirley", "Temple"), height=1.57),
]
first_names = map(attrgetter("name.first"), people)
assert list(first_names) == ["Gertrude", "Shirley"]
There’s also a methodcaller that does what you might g
还有一个 methodcaller 你可能猜到的功能。如果您不知道 NamedTuple 的作用,请继续阅读...
-
语义分析文档
更多信息,请参阅操作符模块文档 https://docs.python.org/3/library/operator.html
-
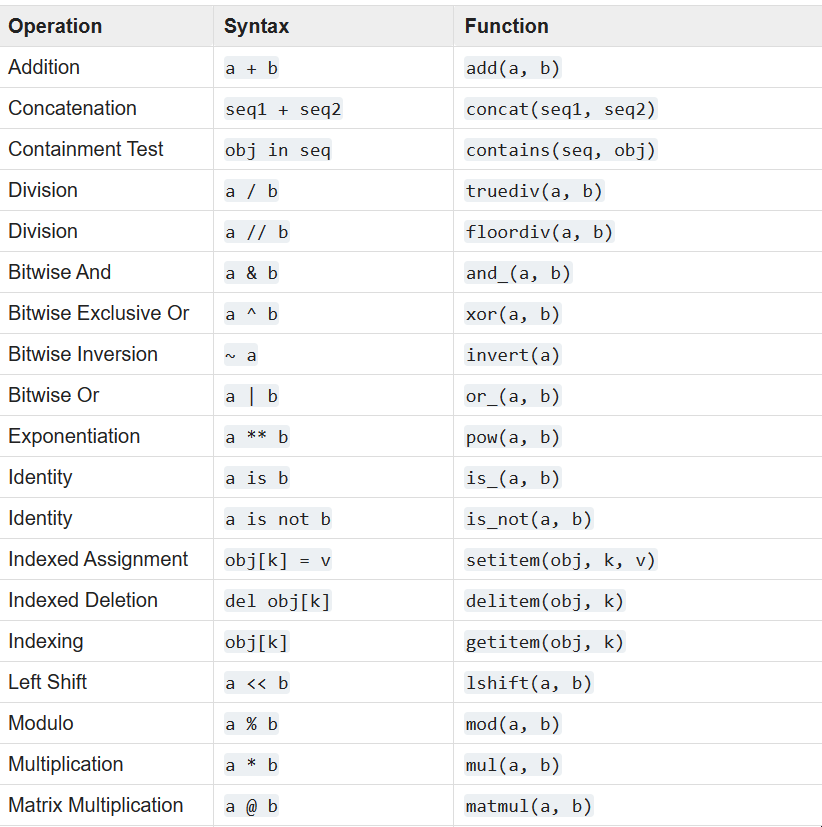
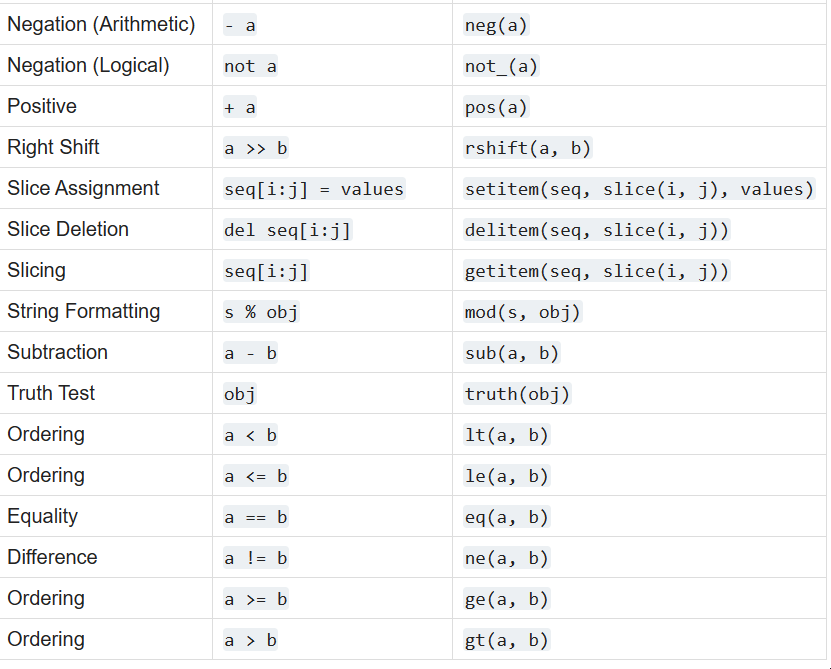
作为函数的运算符
所有我们熟悉的运算符,如 +、< != 在运算符模块中都有对应的函数。在对集合进行迭代时。
例如使用 is_not 查找两个列表之间的不匹配时,这些操作符非常有用:
import operator
list1 = [1, 2, 3, 4]
list2 = [1, 2, 7, 4]
matches = list(map(operator.is_not, list1, list2))
assert matches == [False, False, True, False]
Here’s a table of operators and their function
下面是运算符及其功能对应表:
https://docs.python.org/3/library/operator.html#mapping-operators-to-functions
-
按值对字典排序
您可以使用 key 对 dictionary 按其值排序。在这种情况下,你传递给 key 的函数将被 dict 的每个键调用,并返回一个值,这与字典的 get 方法的作用相同。
my_dict = {
"Plan A": 1,
"Plan B": 3,
"Plan C": 2,
}
my_dict = {key: my_dict[key] for key in sorted(my_dict, key=my_dict.get)}
assert list(my_dict.keys()) == ['Plan A', 'Plan C', 'Plan B']
-
语义分析文档
-
从元组创建 dict
dict() 可以接收键/值对的元组序列。因此,如果你有键和值的列表,你可以把它们压缩在一起,变成一个字典:
keys = ["a", "b", "c"]
vals = [1, 2, 3]
assert dict(zip(keys, vals)) == {'a': 1, 'b': 2, 'c': 3}
-
语义分析文档:
https://docs.python.org/3/library/stdtypes.html#mapping-types-dict
-
用 ** 组合 dict
通过使用 ** 操作符将 dict 解压缩到 dict 字面的主体中,可以组合字典:
sys_config = {
"Option A": True,
"Option B": 13,
}
user_config = {
"Option B": 33,
"Option C": "yes",
}
config = {
**sys_config,
**user_config,
"Option 12": 700,
}
这里的 user_config 将优先于 sys_config,因为它在后面。
-
语义分析文档的词典解包:
https://docs.python.org/3/reference/expressions.html#dictionary-displays
-
用 |= 更新字典
如果你想扩展一个现有的 dict,而不是一个键一个键地扩展,可以使用 |= 操作符。
config = {
"Option A": True,
"Option B": 13,
}
later 这是在 Python 3.9 中添加的:
config |= {
"Option C": 7,
"Option D": "bananas",
}
合并后:
{'Option A': True, 'Option B': 13, 'Option C': 7, 'Option D': 'bananas'}
-
语义分析文档
https://docs.python.org/3/whatsnew/3.9.html#dictionary-merge-update-operators
-
defaultdicts 或 setdefault
假设您想从一个 dict 列表创建一个列表的 dict。一个简单的方法可能是创建一个占位符 dict,然后在循环的每一步都检查是否需要创建一个新的 key。
pets = [
{"name": "Fido", "type": "dog"},
{"name": "Rex", "type": "dog"},
{"name": "Paul", "type": "cat"},
]
pets_by_type = {}
不推荐的写法:
for pet in pets:
# 如果类型还不是一个关键字
# 需要用一个空列表来创建它
if pet["type"] not in pets_by_type:
pets_by_type[pet["type"]] = []
# 现在我们可以安全地调用 .append()
pets_by_type[pet["type"]].append(pet["name"])
assert pets_by_type == {'dog': ['Fido', 'Rex'], 'cat': ['Paul']}
一种更简洁的方法是创建默认字典。
在下面的代码中,当我试图读取一个不存在的键时,它会自动创建一个默认值为空列表的键。
pets_by_type = defaultdict(list)
for pet in pets:
pets_by_type[pet["type"]].append(pet["name"])
缺点是你需要导入 defaultdict,而且如果你想在最后得到一个真正的 dict,你需要执行 dict(pets_by_type)。
另一种方法是使用普通 dict,并使用名称奇怪的 .setdefault():
pets_by_type = {}
for pet in pets:
pets_by_type.setdefault(pet["type"], []).append(pet["name"])
将 "设置默认值 "理解为 "获取,但在需要时设置默认值"。
提示:你可以使用 defaultdict(lambda: None) 创建一个在键不存在时返回 None 的 dict。
-
语义分析文档 default dict👇
https://docs.python.org/3/library/collections.html#collections.defaultdict
-
用于...类型 dict 的 TypedDict
如果你想为你的 dict 的值定义类型,你可以使用以下方法
class Config(TypedDict):
port: int
name: str
config: Config = {
'port': 4000,
'name': 'David',
'unknown': True, # warning, wrong type
}
port = config["poort"]
# warning, what's a poort?
根据你的集成开发环境(我用的是 PyCharm),你会得到正确的自动完成建议(类型不只是为了健壮代码,也是为了偷懒,减少输入字符)。
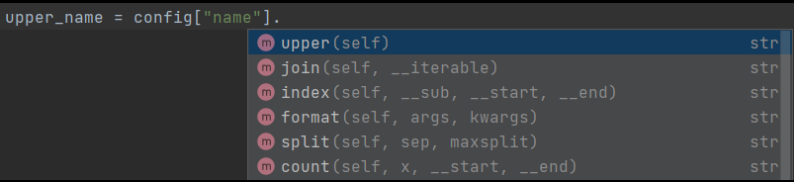
我发现这对于向来自其他来源的字典中添加类型特别有用。如果我想为自己创建的对象添加类型,我很少会使用 dict。
-
语义分析文档 TypedDict👇 https://docs.python.org/3/library/typing.html#typing.TypedDict
15、a // b 并不总是返回 int
假设有一个函数可以将一个列表分割成一定数量的批次。你能发现这段代码中的潜在错误吗?
def batch_a_list(the_list, num_batches):
batch_size = len(the_list) // num_batches
batches = []
for i in range(0, len(the_list), batch_size):
batches.append(the_list[i : i + batch_size])
return batches
my_list = list(range(13))
batched_list = batch_a_list(my_list, 4)
错误将引发 TypeError:batch_a_list(my_list,4)
出现问题的原因是,当 num_batches 是一个浮点数时,len(the_list)``// num_batches 返回的也是一个浮点数,这不是一个有效的索引,因此会引发错误。
具体地说,如果 // 的任意一边都是浮点数,那么两边都将转换为浮点数,结果也将是浮点数。
文档👇
https://docs.python.org/3.3/reference/expressions.html#:~:text=of%20their%20arguments.-,The%20numeric%20arguments%20are%20first%20converted%20to%20a%20common%20type,-.%20Division%20of%20integers
int(a / b) 是更安全的选择。
-
语义分析文档中提到了这一点,但并不是特别清楚。
-
循环引用可以不使用 "from"
你可以让两个模块分别导入另一个模块,这并不是错误。事实上,我觉得这样很好。
只有当其中一个模块从另一个模块导入某些内容时,才会出现问题。因此,如果出现循环引用错误,请考虑从有问题的导入中删除 from。
编程常见问题: 在模块中使用 import 的 "最佳实践 "是什么?
-
使用 or设置默认值
假设有一个带有可选参数的函数。默认值应该是空列表,但不能在函数签名中设置(所有对函数的调用都将共享同一个列表),因此需要在函数体中设置默认值。
你不需要像我经常看到的那样对 None 进行两行检查:
def make_list(start_list: list = None):
if start_list is None:
start_list = []
...
您可以直接使用 or
def make_list(start_list: list = None):
start_list = start_list or []
...
如果 start_list 是真实的(非空 list),就会被使用,否则就会被设置为空 list。
只有在调用函数时不会使用 bool(value) == False 的值时,这种方法才是合理的。
-
语义分析文档:
https://docs.python.org/3/reference/expressions.html#boolean-operations
-
使用 default_timer 作为......默认计时器 在 Python 中有很多获取时间的方法 default timer。
如果您的计划是计算两个时间点之间的差值,下面是一些不正确的方法:
# 错误
start_time = datetime.now()
start_time = datetime.today()
start_time = time.time()
start_time = time.gmtime()
start_time = time.localtime()
错误较少,但在 Windows 上会失败
# 错误较少,但在 Windows 上会失败
start_time = time.clock_gettime(1)
start_time = time.clock_gettime(time.CLOCK_MONOTONIC)
同理你并不希望时间倒退,但上述前五种方法允许出现这种情况(夏令时、闰秒、时钟调整等)。
由于认为时间不会倒退而导致的错误很少见,但确实存在,而且很难追查。
最好的方法是:
start_time = timeit.default_timer()
这个方法很容易记住,而且能给出一个不会倒退的时间。
从 Python 3.11 开始,它指向 time.perf_counter,所以还有两个值得一提的方法:
start_time = time.perf_counter()
start_time = time.perf_counter_ns() # 纳秒
-
语义分析文档
文档中的 default_timer https://docs.python.org/3/library/timeit.html#timeit.default_timer
-
解释器中的' _':最后的结果
如果你执行了某些操作,输出了一个值,现在你想对输出结果做一些事情,这就很方便了。
get_some_data()
# 运行需要一段时间
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16、
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39])
_.mean()
19.5
type(_) 是我经常使用的另一种类型。
但要注意的是,你只能使用一次,因为你将会有一个新的输出,这就是 _ 所指向的内容。对于 IPython 用户,可以输入 _4 来指代 Out[4]
代码展示了 '_' 在 Python 交互式解释器中的一些常见用法。
首先,执行一个函数 get_some_data(),它返回一个数组。这个数组被打印出来。
然后,我们想基于这个数组再做一些操作。通常我们需要把数组赋值给一个变量,然后在变量上操作。但是 '_' 允许我们直接引用最后一个打印的输出。
所以我们调用 _.mean() 来直接计算刚刚那个数组的平均值。
这样可以避免定义一个临时变量来存储之前的输出'_' 总是引用最后一个输出值。
另外,使用 type(_) 可以快速查看最后一个输出的类型。
'_ _',双下划线:还可以用于一些其他特殊用途,比如数字字面量中的分隔符(1_000_000),或者作为占位变量名:
for _ in range(10)
总之, '' 在交互式编程中非常方便,可以避免定义不必要的临时变量。需要注意它只引用最近的一个输出,后面新的输出会覆盖之前的 ''。
-
语义分析文档
_ 还有其他作用,更多内容请参见词法分析文档,以及下一节...
https://docs.python.org/3/reference/lexical_analysis.html#reserved-classes-of-identifiers
-
*_ 用来收集不需要的元素 如果您调用的函数返回一个元组中的多个值,但您只想要第一个值,您可以在调用时追加 [0],或者使用 *_ 忽略其他返回值:
def get_lots_of_things(): return "Puffin", (0, 1), True, 77
bird, *_ = get_lots_of_things()
-
表示迭代解包。单个下划线是未使用变量的约定(当变量名为 _ 时,大多数类型/样式检查程序不会给出 "未使用变量 "警告)。
-
语义分析文档
PEP 3132 中定义了这一行为。
21.dict.key 键不必是字符串
各种各样的东西都可以成为 dict 键:函数、元组、数字--任何可散列的东西。
比方说,你想用 dict 表示一个图Graph,其中每个键都是一对节点,而值则描述它们之间的边。
你可以用元组来表示,但如果你想让(a, b) 返回与(b, a))相同的值,你就需要一个集合。
集合不可散列,但frozen_set可以,因此我们可以使用
graph = {
frozenset(["a", "b"]): "a 和 b 之间的边",
frozenset(["b", "c"]): "b 和 c 之间的边"
}
assert graph[frozenset(["b", "a"])] == graph[frozenset(["a", "b"])]
很明显,如果你想为实数做这件事,你应该做类似扩展 dict 这样的事情:
class OrderFreeKeys(dict):
def __getitem__(self, key):
return super().__getitem__(frozenset(key))
def __setitem__(self, key, value):
return super().__setitem__(frozenset(key), value)
graph = OrderFreeKeys()
graph["A", "B"] = "A 和 B 之间有一条边"
assert graph["B", "A"] == "A 和 B 之间有一条边"
print(graph["A", "B"])
第二个示例中的 A 和 B 使用了大写字母,因为多样性是生活的调味品。
本文由 mdnice 多平台发布