一维数组的创建和初始化
数组的创建
数组的初始化
一维数组的使用
一维数组在内存中的存储
二维数组的创建和初始化
二维数组的创建
二维数组的初始化
二维数组的使用
二维数组在内存中的存储
数组越界
数组作为函数参数
冒泡排序函数的错误设计
数组名是什么?
冒泡排序函数的正确设计
一维数组的创建和初始化
数组的创建
数组是一组相同类型元素的集合.
数组的创建方式:
type_t arr_name[const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小举例:
//代码1
int arr1[10];
//代码2
int count = 10;
int arr2[count];//数组时候可以正常创建?
注意:此时是不可以创建的,因为count是变量,而[]内只能是常量
//代码3
char arr3[10];
float arr4[1];
double arr5[20];注意:数组创建,在C99标准之前,[]中要给一个常量才可以,不能使用变量.在C99标准支持了变长数组的概念,即在[]中可以用变量.
数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)
下面是例子:
int arr1[10] = { 1,2,3 };
int arr2[] = { 1,2,3,4 };
int arr3[5] = { 1,2,3,4,5 };
char arr4[3] = { 'a',98, 'c' };
char arr5[] = { 'a','b','c' };
char arr6[] = "abcdef";数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
但是对于下面的代码要区分,内容中如何分配.
char arr1[] = "abc";
char arr2[3] = { 'a','b','c' };运行结果:
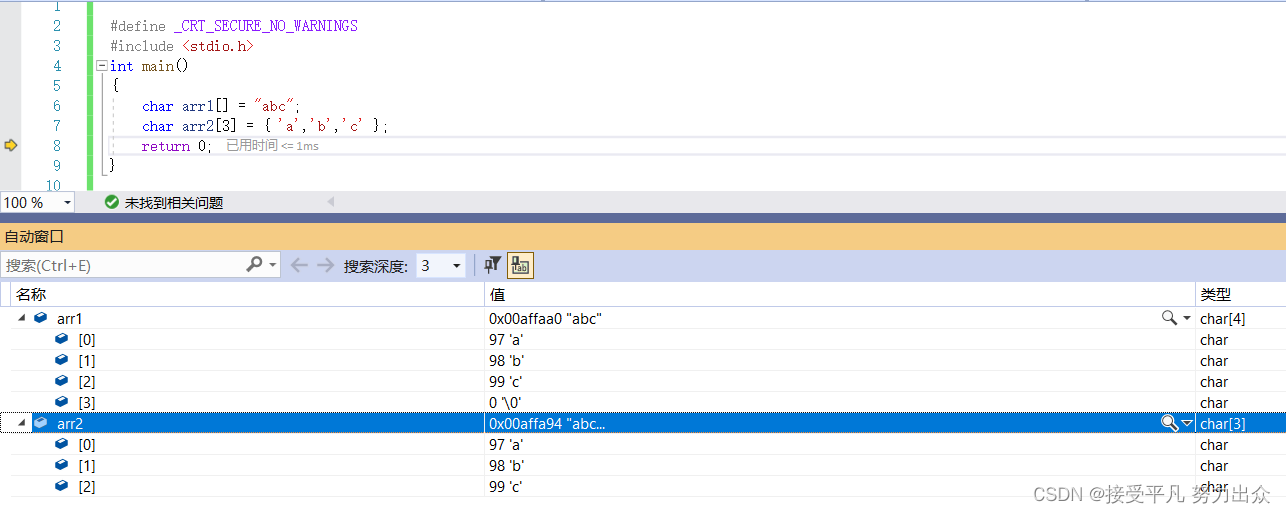
在arr1中,在内存中有4个数组元素,除了字符'a','b','c'之外,还有一个字符串的结束标志'\0',而在arr2中,则只有字符'a','b','c',对这两个字符串进行输出.
注意:printf()函数对字符串进行输出的时候,当遇到'\0'即字符串的结束标志即停止输出,在arr2中,因为没有字符串的结束标志,所以会出现乱码.
总而言之,arr2的这种初始化方式没有字符串的结束标志'\0',而arr1的这种初始化方式则包含字符串的结束标志!
一维数组的使用
对于数组的使用我门之前介绍了一个操作符:[],下标引用操作符.它其实就是数组访问的操作符.
看以下代码:
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
arr[i] = i;
}
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}总结:
1.数组是使用下标来访问的,下标是从0开始。
2.数组的大小可以通过计算得到。
那么我们如何求数组的个数呢?
int arr[10];
int sz = sizeof(arr)/sizeof(arr[0]);数组的个数即是数组所占总的空间除以一个数组元素所得的值,简单举个例子来说就有点类似于总价除以单价得到商品的个数!
一维数组在内存中的存储
接下来我们探讨数组在内存中的存储,看代码:
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}下面是运行结果:
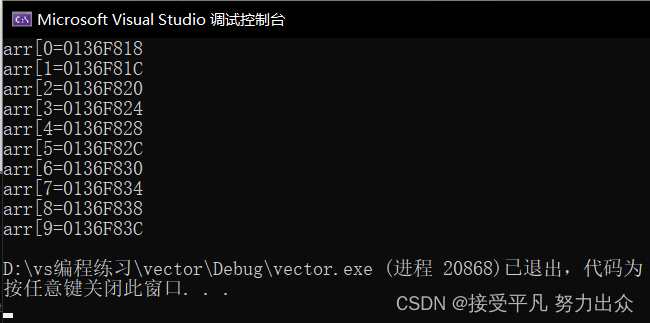
仔细观察输出的结果发现,随着数组下标的增长,元素的地址,也在有规律的递增.由此我们可以得出结论:数组在内存中是连续存放的
二维数组的创建和初始化
二维数组的创建
//数组创建
int arr[3][4];
char arr[3][5];
double arr[2][4];二维数组的初始化
//数组初始化
int arr[3][4] = {1,2,3,4};
int arr[3][4] = {{1,2},{4,5}};
int arr[][4] = {{2,3},{4,5}};//二维数组如果有初始化,行可以省略,列不能省略二维数组的使用
二维数组的使用也是通过下标的方式.看代码:
#include <stdio.h>
int main()
{
int arr[3][4] = { 0 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
arr[i][j] = i * 4 + j;
}
}
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("%d ", arr[i][j]);
}
}
return 0;
}运行结果:

二维数组在内存中的存储
像一维数组一样,这里我们尝试打印二维数组的每个元素.
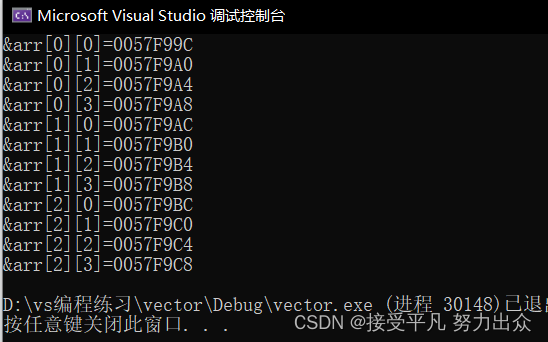
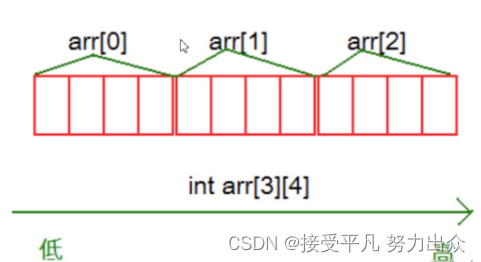
通过结果我们可以分析到,其实二维数组在内存中也是连续存储的。
数组越界
数组的下标是有范围限制的.
数组的下标规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1,所以数组的下标如果小于0,或者大于n-1,就会导致数组越界访问问题,超出了数组合法的空间访问.
C语言本身是不做数组下标的越界检查的,编译器也不一定会报错,但是编译器不报错,并不意味着程序就是正确的,所以程序员写代码时,最好自己做越界的检查.
 注意:二维数组的行和列也可能存在越界。
注意:二维数组的行和列也可能存在越界。
数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传给函数,比如:我要实现一个冒泡排序(这里要讲算法 思想)函数将一个整形数组排序。
那我们将会这样使用该函数:
冒泡排序函数的错误设计
//方法一:
#include <stdio.h>
void bubble_sort(int arr[])
{
int sz = sizeof(arr) / sizeof(arr[0]);//这样对吗?
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
bubble_sort(arr);//是否可以正常排序?
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}下面是运行结果:

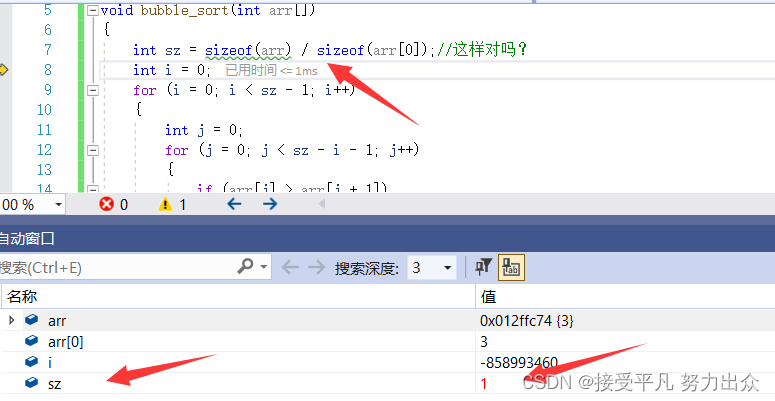 很明显,方法1出问题了,并没有实现排序的目的,那我们找一下问题,调试之后可以看到 bubble_sort 函数内部的 sz ,是1。 难道数组作为函数参数的时候,不是把整个数组的传递过去?下面就要讨论一下数组名究竟代表什么!
很明显,方法1出问题了,并没有实现排序的目的,那我们找一下问题,调试之后可以看到 bubble_sort 函数内部的 sz ,是1。 难道数组作为函数参数的时候,不是把整个数组的传递过去?下面就要讨论一下数组名究竟代表什么!
数组名是什么?
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5 };
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%d\n", *arr);
//输出结果
return 0;
}运行结果:

结论:数组名是数组首元素的地址.
1. sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数组.
2.&数组名,取出的是数组的地址.&数组名,数组名表示整个数组.
除此1,2两种情况之外,所有的数组名都表示数组首元素的地址.
冒泡排序函数的正确设计
当数组传参的时候,实际上只是把数组的首元素的地址传递过去了。 所以即使在函数参数部分写成数组的形式: int arr[] 表示的依然是一个指针: int *arr 。 那么,函数内部的 sizeof(arr) 结果是4。 既然方法1错了,那么冒泡排序法究竟该怎么设计?下面就是冒泡排序法的正确方法:
//方法2
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
//代码同上面函数
}
int main()
{
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz);//是否可以正常排序?
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}![[附源码]Python计算机毕业设计SSM基于的汉服服装租赁系统(程序+LW)](https://img-blog.csdnimg.cn/65e354d847644376830d378b25aebfe9.png)
![[附源码]Python计算机毕业设计Django大学生志愿者服务管理系统](https://img-blog.csdnimg.cn/1299e3b81b0c4deb881c95eaf162cf88.png)