论文地址:Meshed-Memory Transformer for Image Captioning (thecvf.com)
Background
本文在transformer的基础上,对于Image Caption任务,提出了一个全新的fully-attentive网络。在此之前大部分image captioning的工作还是基于CNN进行特征提取再有RNNs或者LSTMs等进行文本的生成。本文的主要创新点为:
-
图像区域及其关系以多级方式编码,其中考虑了低级和高级关系。在建模这些关系时,本文的模型可以通过使用持久的记忆向量来学习和编码先验知识;
-
句子的生成采用了多层架构,它利用了低级和高级的视觉关系,而不是只有一个来自视觉模态的单一输入。
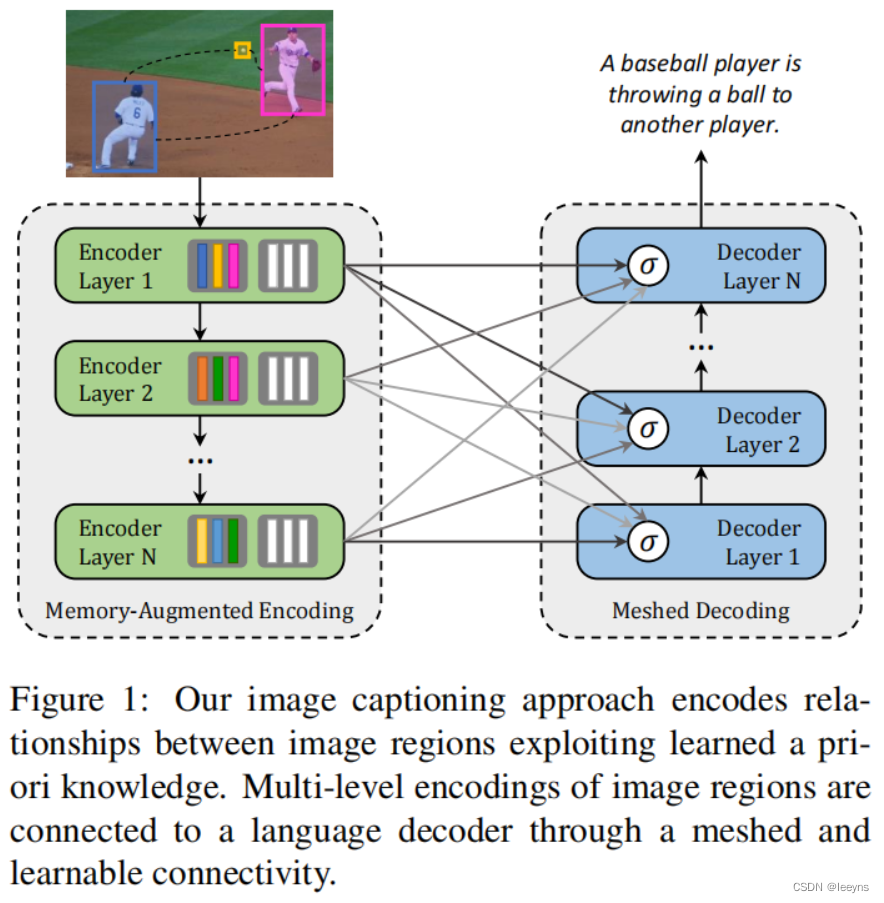
如上图所示,首先对于传统的Transformer加入了先验知识学习的vector (图中encoder layer里的白色部分)。其次对于cross attention,区别于传统的transformer只使用encoder最后一层输出来参与,本文提出将每一层的encoder layer的输出都做一次attention运算,利用了low-level 和 high-level所有的信息。
Improvement
模型的整体结构如下:
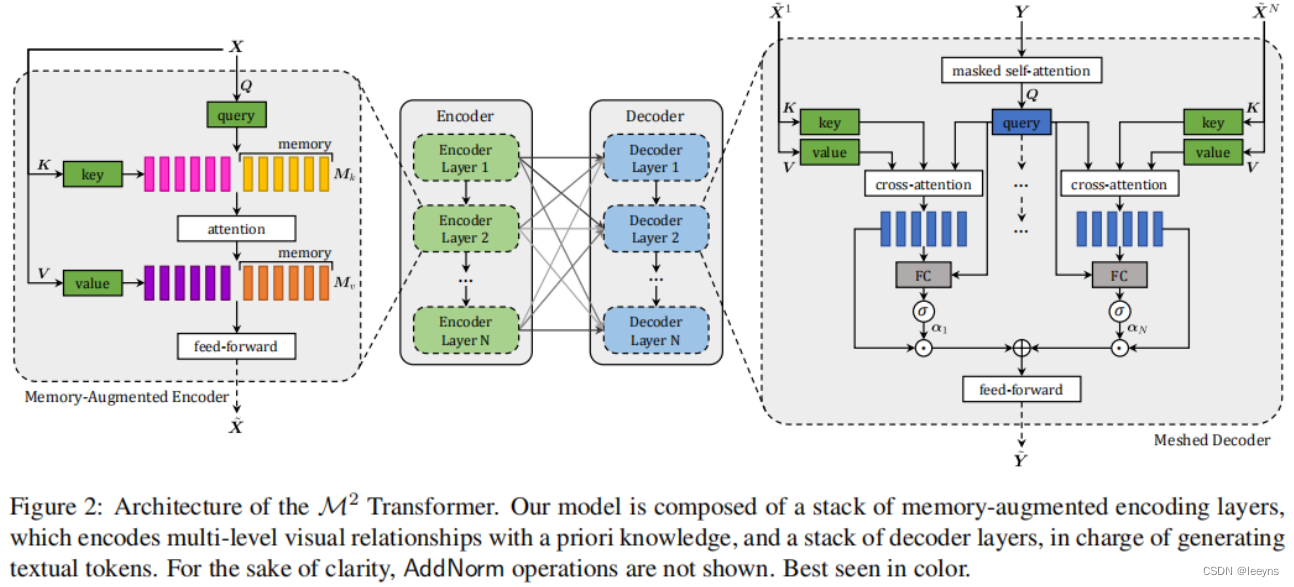
主要改进就是在传统attention中加入了memory slots,用来存储并学习先验知识。并且encoder 和 decoder之间cross attention不仅仅只是encoder最后一层的输出参与计算,而是每一层的输出都参与。
Memory-Augmented Encoder
传统的Transformer中的encoder部分的self-attention是用来提取输入数据之间的关系并提取特征,其中queries, keys 和 values都是对输入数据进行不同的线性变换得来的:
其中是可学习参数。
这种self-attention操作只提取了输入数据本身的关系,但是这样的操作并不能加入一些先验知识。例如,当输入特征包括篮球时,并不能结合先验特征得到运动员和比赛这样的概念。因此本文在encoder的self-attention操作中加入了先验知识学习的部分。因此self-attention的操作则变为:
其中是可学习参数。在代码中可以找到他们是这样定义的:
self.m_k = nn.Parameter(torch.FloatTensor(1, m, h * d_k))
self.m_v = nn.Parameter(torch.FloatTensor(1, m, h * d_v))
Meshed Cross-Attention
本文在传统Transformer只利用encoder最后的输出进行decoder 部分cross-attention计算的基础上做了改进。动机是为了结合深层和浅层的信息,并进行信息的融合,其中融合的办法是加权求和。
对于Encoder的每一层的输出为,对于Decoder的输入序列定义为.因此每一层与的cross attention 计算方法如下:
定义是一个权重矩阵,的权值调节各编码层的单一贡献,以及不同编码层之间的相对重要性。通过测量每个编码层的交叉注意结果与输入查询之间的相关性来计算这些数据,如下所示:
因此最后decoder的cross-attention的输出为:
其他部分和Transformer类似,这里就不详细介绍了。
Conclusion
本文算是首次将Transformer应用于Image captioning这项工作中,同时也考虑了结合不同层的信息的融合。主要的改进也在于信息的融合,首先是对于先验知识和encoder信息的融合,然后就是encoder不同层信息之间的融合。


![[附源码]JAVA毕业设计疫情下图书馆管理系统(系统+LW)](https://img-blog.csdnimg.cn/d639117c753741fb8e02963191b07b5d.png)