AI情绪鼓励师(基于PALM 2.0 finetune)
目录
一、写在前面的话
二、前言
三、获取用于finetune的“夸夸”数据集
四、 获取并finetune PALM 2.0 预训练生成模型 模型
五、模型调用应用
一、写在前面的话

从小我就是极端内向和社恐的孩子,我普通之极并不出色,不想被人拿来比较,所以喜欢躲在不起眼的地方。每每遇事总是小心翼翼,生怕被人耻笑了去。我也不善言辞,不会讨人欢心。我唯一有的,只是待人真诚和善良。我珍惜所有遇到的人和物,家里养的小动物S了,我也会哭半天难受很久很久。。。
突遇变故以来,我哭过,想不通为什么,想不通那些人怎么可以这样伤害别人。。。一直以来,我的世界里从没有敌人。
困境和挫折能让人沉沦或长大,我选择了长大,自己擦干眼泪,从不起眼的地方站了起来,虽然反复不停在崩溃和自愈之间循环,但我还是坚持了下来。我今年50岁了,在家专心做家务很多年,身体状况不佳、和社会脱节、荒废了的计算机技术。。。从新起步并不容易。
逆境中,伤心、哭泣、自怨自艾、沉沦麻醉自己。。。并不能改变所处的困境,还不如承认残酷的现实,勇敢面对。我会一点一滴从头学习了解现在社会各种流行的It技术,我会在学习群里回答一些我知道答案的问题,帮助有需要的人,我会在邻居有事情离开时,帮他们浇浇花除除草。。。每个人活得都不容易,简单的事情,也能带给别人些许温暖,让别人在遇事时能减轻压力。我很普通,我能做到的,其他人也同样能做到,事实已证明。
我不知道很多事情,只知道世界发生了很大改变,我们都在惊慌失措中,不知所措地被推着前行,能看清这一切的人并不多。因为我们都只是普通人,在精心设计安排的幻境里,谁能保证自己看到听到的一切是事实真相?
我在等,等那些我曾认识过的人,等那些我曾“听”说过的人,等他们健康平安的消息。
很多事情我都不知道,不知道发生过什么,我只知道有人为了自己利益隐瞒造假了一些事实真相,造成了很多无法解释也无从解释的误会。
我在等,等天晴后,等那些相关的人自己告诉我曾经发生过的一切,不只是与我有关,如果他们还愿意的话。
The most precious thing in the world
世上最珍贵的东西
Is not money
不是金钱,
Is caring and missing
是关心,是惦念,
Is wellness and health
是平安,是健康,
Hopefully we will all be well in our following days
愿我们在接下来的日子里都能平安
✨I hope you will be happy every day
我希望你每天都开心
✨I hope you will smile every day
我希望你每天都微笑
✨I每一天,都是一次征途。一边努力奋斗,一边自我治愈。学会放松自己,给自己一些生活的松弛感,生活才充满阳光。
逆境清醒
2023.8.2

二、前言
此文模型训练部分源于老师教程,个人学习练习所用。
三、获取用于finetune的“夸夸”数据集
在这一节中,我们将从[https://modelscope.cn/datasets/damo/chinese-kuakua-collection/summary] 中获取用于Finetune的“夸夸数据集”。
下方是获取数据集的实例代码,我们将展示下原始数据的前十行样例:
(由于数据集本身的格式问题,虽然数据集的shape是 𝑛×3 ,但实际后两列均为none,只有第一列有实际意义,其中|前为输入文本,|后为期望产生的“夸夸”体答复)。
#%matplotlib inline
import matplotlib
from IPython.utils import io
import os
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from modelscope.msdatasets import MsDataset
from datasets import Dataset
with io.capture_output() as captured:
ds_train = MsDataset.load('damo/chinese-kuakua-collection', subset_name='default', split='train')
ds_eval = MsDataset.load('damo/chinese-kuakua-collection', subset_name='default', split='validation')
print('\n'.join(ds_train['text1'][:10]))
print('完成')要去打球赛了求表扬 | 真棒好好打乒乓球! 独自去陌生城市自由行了 | 好厉害我也想这样自己一个人去旅行还没想好去哪个城市 自己贴的电脑膜哭着也要看 | ?对不住,夸不出口 老师不要给我打零分 | 你太能捧了吧,我在组里这么久,你是最牛逼的 今天终于提了辞职 | 恭喜你迈出了第一步刚好可以找找下家加油啦 复试凉的完完整整求表扬 | 能进复试已经非常棒啦 被说我就是个初学者,我觉得我画的挺好的为什么有... | 我感觉很棒啊 刚刚过了科三,科二也过了,求表扬~\(≧▽≦)/~ | 我过完科一就没去学过,你真厉害 室友参加讲座抽中了TF的口红💄…… | 调整的很快啊 超级丧求表扬 | 不敢哭就笑起来😅 完成
接下来我们对数据集进行了整理,保证其符合PALM 2.0 模型要求的格式
# 这一步是防止数据集中的数据有缺陷,不按照文档中所述: qqqqqq | aaaaaa 的格式来
# 以防万一,我们在数据末尾再添加一个 “ | ”,保证可以按上述格式来分隔出问题和回答
valid_ds_train = [line + ' | ' for line in ds_train['text1']]
valid_ds_eval = [line + ' | ' for line in ds_eval['text1']]
# 这一步是将夸夸数据集整理成PALM模型所需要的格式
# 即:src_txt列为问题,tgt_txt列为回答
train_src_text, train_tgt_text = zip(*[(line.split(' | ')[0],line.split(' | ')[1]) for line in valid_ds_train])
eval_src_text, eval_tgt_text = zip(*[(line.split(' | ')[0],line.split(' | ')[1]) for line in valid_ds_eval])
train_dataset_dict = {"src_txt": train_src_text, "tgt_txt": train_tgt_text}
eval_dataset_dict = {"src_txt": eval_src_text, "tgt_txt": eval_tgt_text}
train_dataset = MsDataset(Dataset.from_dict(train_dataset_dict))
eval_dataset = MsDataset(Dataset.from_dict(eval_dataset_dict))
print('完成')完成
下面我们看一下数据集中的数据是什么样的:
print("train数据集:")
print(len(train_dataset['src_txt']))
print(len(train_dataset['tgt_txt']))
for i in range(10):
print(train_dataset['src_txt'][i] + ' : ' + train_dataset['tgt_txt'][i])
print("\neval数据集:")
print(len(eval_dataset['src_txt']))
print(len(eval_dataset['tgt_txt']))
for i in range(10):
print(eval_dataset['src_txt'][i] + ' : ' + eval_dataset['tgt_txt'][i])
print('完成')train数据集: 14000 14000 要去打球赛了求表扬 : 真棒好好打乒乓球! 独自去陌生城市自由行了 : 好厉害我也想这样自己一个人去旅行还没想好去哪个城市 自己贴的电脑膜哭着也要看 : ?对不住,夸不出口 老师不要给我打零分 : 你太能捧了吧,我在组里这么久,你是最牛逼的 今天终于提了辞职 : 恭喜你迈出了第一步刚好可以找找下家加油啦 复试凉的完完整整求表扬 : 能进复试已经非常棒啦 被说我就是个初学者,我觉得我画的挺好的为什么有... : 我感觉很棒啊 刚刚过了科三,科二也过了,求表扬~\(≧▽≦)/~ : 我过完科一就没去学过,你真厉害 室友参加讲座抽中了TF的口红💄…… : 调整的很快啊 超级丧求表扬 : 不敢哭就笑起来😅 eval数据集: 2426 2426 被老板骂了,然后我踹歪了他的鼻子,求表扬 : 他拿出一个新的又安上了 教资笔试过了,求夸 : 厉害了👍🏻 装了一晚上CAD都没装成功求鼓励 : 直接在官网上装啊 春节以后就没有性生活了,节能减排,求表现 : 喜欢我吗,不喜欢也要关注我o(^_^)o 运动会第一 : 这么帅还这么厉害,不给别人活路! 今天做完了本学期最后一次pre……求表扬! : 一般这么长我都是不看的 长胖了,求表扬 : (/ω\) 今天写了毕业论文第五章 : 一百个赞[哈哈] 我发现了史上最沉默小组的话题! : 有人发东西会被删掉,所以不是大家沉默😂 祝我生日快乐! : 生日快樂🎂🎁🎊🎈🎉越來越美哦 完成
四、 获取并finetune PALM 2.0 预训练生成模型 模型
接下来是finetune的部分。在这里,我们使用的预训练模型是[ModelScope 魔搭社区]中的“PALM 2.0预训练生成模型-中文-base”模型,你也可以用其他类似的文本生成类模型替代。注意其他模型如GPT3-1.3B,无法再ModelScope免费提供的16G显存上训练,需要去付费实例环境购买使用。
ModelScope中,已经配置好了常见的AI任务的损失函数(Loss Function),和常见的优化器(Optimizer),因此我们只需要针对我们的Finetune任务进行少许的定制化配置就可以开始训练。在我们的夸夸机器人当中,我们使用了常见的“文本生成”类Loss Function和常见的Adam Optimizer,只需要配置特殊的优化器更新函数就可以运行。另外,我们设定了在整个数据集上训练15遍,所以max_epochs=10
from modelscope.trainers import build_trainer
from modelscope.metainfo import Trainers
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
print('完成')完成
为了更好理解这里的特殊配置,我们将在接下来的一部分中介绍一些机器学习(Machine Learning)训练时的基本内容。如果您之前接触过Machine Learning,可以跳过此部分。

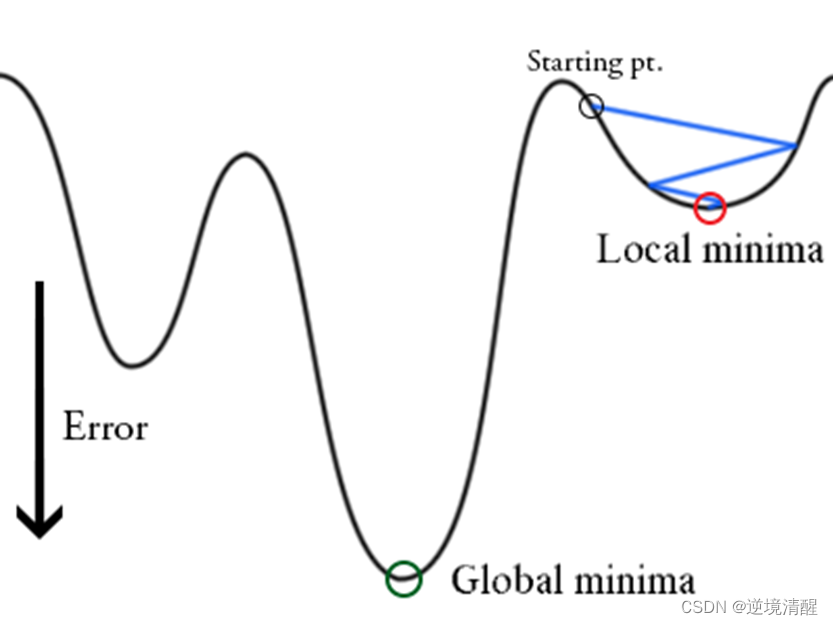
如上图所示,learning_ratelearning_rate 如果不够大,很容易在训练参数θ�的过程中探索的区域不够多,陷入局部的最小值当中。
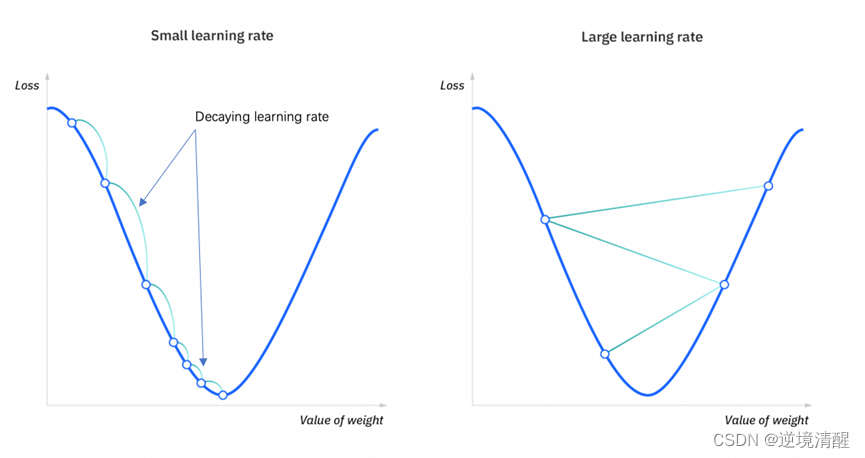
而当如上图所示, learning_rate 一直在一个相对 loss 较大的值的时候,很容易在训练参数 𝜃 的过程中没法继续收敛,始终在最优解附件左右摇摆。
因此如何在训练过程中调整learning rate,会对最终的效果产生比较大的影响。这也是在PALM 2.0的训练过程中,我们单独自定义了learning rate变化函数的原因。
以上粗略地解释了learning rate是什么以及为什么我们要单独定义这个函数。后续为具体的learning rate实现。
我们先依据Transformer 的原始论文《Attention Is All You Need》中,5.3 Optimzier一节所强调的,构建训练时的learning rate所需要的更新函数。

这种learning rate随着训练的进行先升后降的方式也被叫做“Noam” scheme。
def noam_lambda(warm_up:int):
def fn(current_step: int):
current_step += 1
return min(current_step**(-0.5),current_step * warm_up**(-1.5))
return fn
print('完成')完成
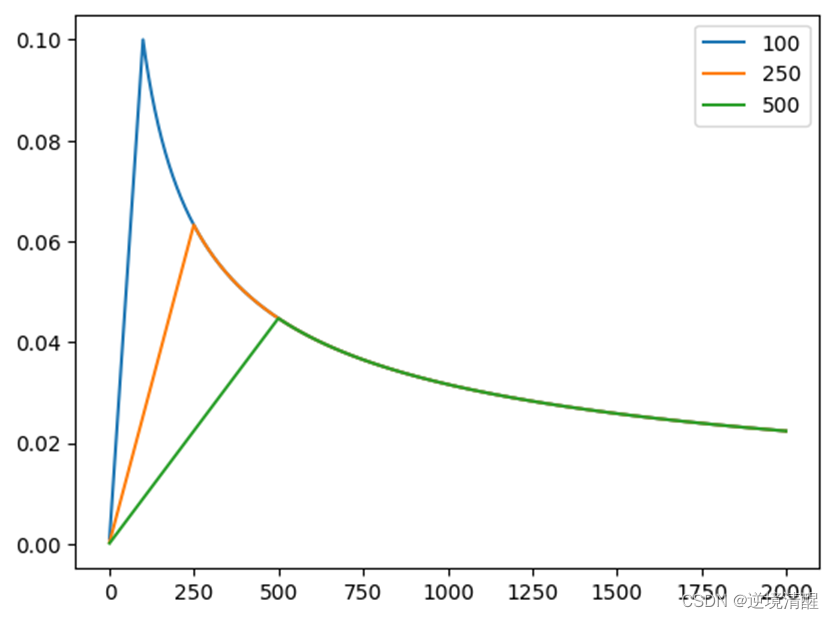
我们可以看一下“Noam” scheme对于训练中learning rate系数的影响。其中warm_upwarm_up是控制何时learning rate开始decay的。下图中的三条曲线分别是warm_up=100warm_up=100,warm_up=250warm_up=250和warm_up=500warm_up=500。
lambdas = [[noam_lambda(100)(i),noam_lambda(250)(i),noam_lambda(500)(i)] for i in range(2000)]
plt.plot(np.arange(0, 2000), lambdas)
plt.legend(["100", "250", "500"])
None
print('完成')完成
接下来我们采用warm_up=500warm_up=500 ,并配置好训练的其他配置项,开始训练。(这个过程取决于具体配置的max_epochs、batch_size等,这里采用我们的配置大概要训练1.5个小时。训练时的日志我们保存在了./palm2.0_kuakua/*.log中,如果训练期间你关闭了Notebook,或者其他原因导致Notebook不再产生标准输出,可以通过观察日志文件来判断训练的进度)。
一个epoch的含义是在整个数据集上训练一遍,而iteration代表着在一个batch上训练一次(更新一次模型的weight)。如果数据集中包含了1000个数据,我们设定了训练的batch大小为8,那么我们训练一个epoch就会训练1000/8=1251000/8=125个batch,也就是每个epoch我们要训练125个iteration。
注意我们在配置中,配置了lr_scheduler的'by_epoch':False,这意味着我们的learning rate会在每个iteration而非epoch都会更新。而训练日志中,第一个epoch的第500个iteration(也就是我们配置的warm_upwarm_up值),epoch [1][500/875]处开始下降。这符合我们之前对“Noam” Scheme的解释。
#num_warmup_steps = 500
#max_epochs = 15
num_warmup_steps = 500
#max_epochs = 15
max_epochs = 15
tmp_dir = './palm2.0_kuakua'
def cfg_modify_fn(cfg):
cfg.train.lr_scheduler = {
'type': 'LambdaLR',
'lr_lambda': noam_lambda(num_warmup_steps),
'options': {
'by_epoch': False
}
}
cfg.train.optimizer = {
"type": "AdamW",
"lr": 1e-3,
"options": {}
}
cfg.train.max_epochs = max_epochs
cfg.train.dataloader = {
"batch_size_per_gpu": 16,
"workers_per_gpu": 1
}
cfg.train.checkpoint.period = {'save_strategy': 'by_epoch',
'max_checkpoint_num': 2}
cfg.train.checkpoint.best = {
"by_epoch": True,
"metric_key": "rouge-l",
"max_checkpoint_num": 2
}
cfg.evaluation.period = {'eval_strategy': 'by_epoch','interval':875}
return cfg
kwargs = dict(
model='damo/nlp_palm2.0_pretrained_chinese-base',
train_dataset=train_dataset,
eval_dataset=eval_dataset,
work_dir=tmp_dir,
cfg_modify_fn=cfg_modify_fn)
with io.capture_output() as captured:
trainer = build_trainer(
name=Trainers.text_generation_trainer, default_args=kwargs)
trainer.train()
print('完成')
import json
history_lrs = []
history_loss = []
with open('./palm2.0_kuakua/20230720_215209.log.json', 'r') as fin:
for line in fin:
train_detail = json.loads(line.strip())
if 'lr' in train_detail:
history_lrs.append(float(train_detail['lr']))
if 'loss' in train_detail:
history_loss.append(float(train_detail['loss']))#请将下面的文件路径改为你的日志名。位置在palm2.0_kuakua/xxxxxxxx_xxxxxx.log.json
plt.plot(np.arange(0, len(history_lrs)), history_lrs)
None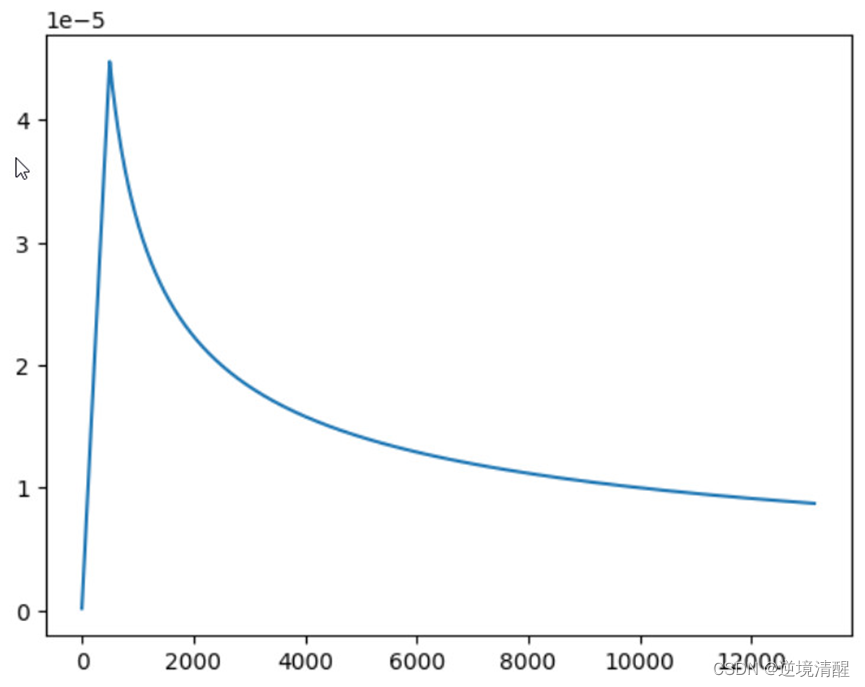
上图是在训练过程中的learning rate的变化。根据我们的配置,learning rate从第100个iteration开始减少。
plt.plot(np.arange(0, len(history_loss)), history_loss)
None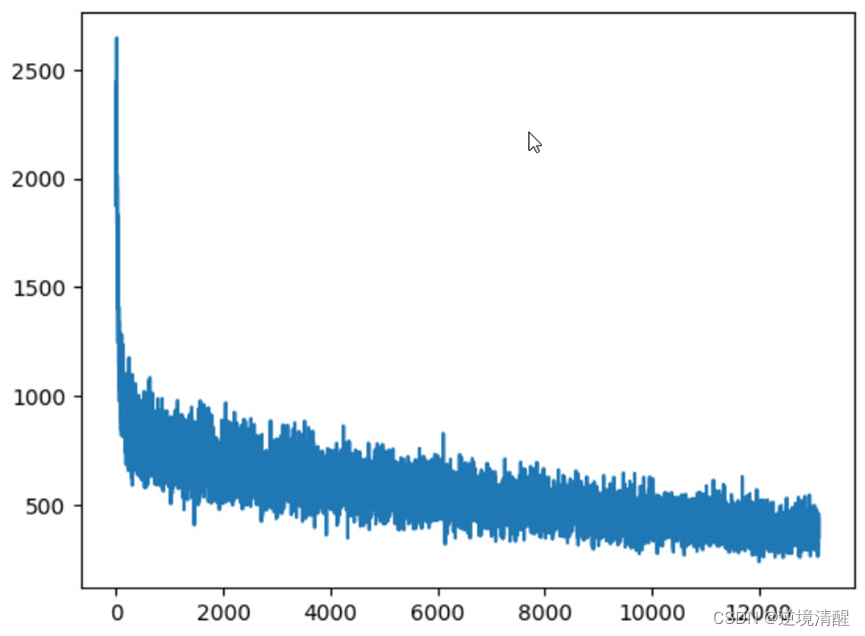
上图是在训练过程中的loss的变化,根据这个我们可以判断模型是否开始收敛(如果还未收敛,则可以继续训练来改善效果)。
3. 体验finetune后的 PALM 2.0 预训练生成模型
你也可以将input换为你自己的输入来体验下。由于pipeline使用了分布式推理,需要打开一个端口。默认端口为29500,为了端口不冲突,我们将后面体验的端口做了修改。
input_1 = '今天我买了瓶洗发水,可以夸夸我吗?'
input_2 = '今天我有点沮丧,可以夸夸我吗?'
model_base = 'damo/nlp_palm2.0_pretrained_chinese-base'
with io.capture_output() as captured:
os.environ["MASTER_PORT"] = "29501"
pipe_base = pipeline(Tasks.text_generation, model=model_base)
os.environ["MASTER_PORT"] = "29502"
pipe_ft = pipeline(Tasks.text_generation, model='./palm2.0_kuakua/output')print("##################################################")
print("下面先展示两条预训练模型底座的输入与输出")
print("##################################################")
# 可以在 pipe 中输入 max_length, top_k, top_p, temperature 等生成参数
print(input_1)
print(pipe_base(input_1, max_length=512))
print(input_2)
print(pipe_base(input_2, max_length=512))##################################################
下面先展示两条预训练模型底座的输入与输出
##################################################
今天我买了瓶洗发水,可以夸夸我吗?
{'text': '今天我买了瓶洗发水,今天!今天!今天!今天!今天!今天!!今天!!今天!!今天?今????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????'}
今天我有点沮丧,可以夸夸我吗?
{'text': '今天我有今今天我有今天!今天!今天!今天!今天!今天!'}
print("##################################################")
print("下面是同样输入,finetune后的夸夸机器人的输出")
print("##################################################")
# 可以在 pipe 中输入 max_length, top_k, top_p, temperature 等生成参数
print(input_1)
print(pipe_ft(input_1))
print(input_2)
print(pipe_ft(input_2))##################################################
下面是同样输入,finetune后的夸夸机器人的输出
##################################################
今天我买了瓶洗发水,可以夸夸我吗?
{'text': '洗发水是个很有趣的事情'}
今天我有点沮丧,可以夸夸我吗?
{'text': '努力生活的你最棒'}
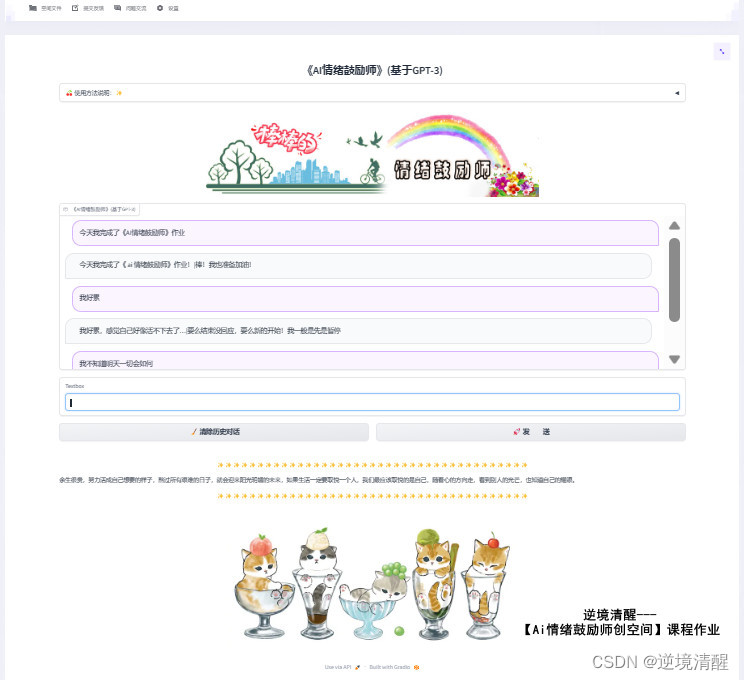
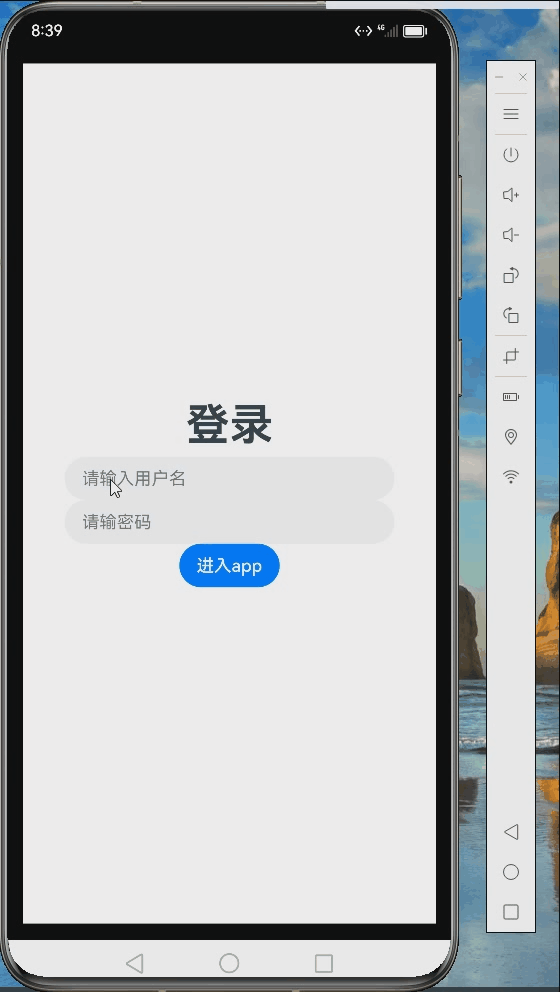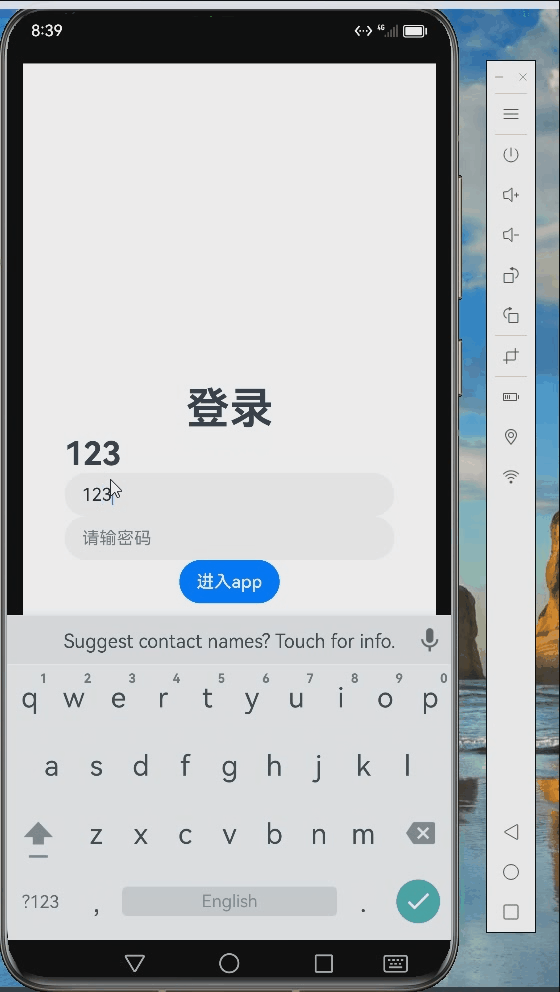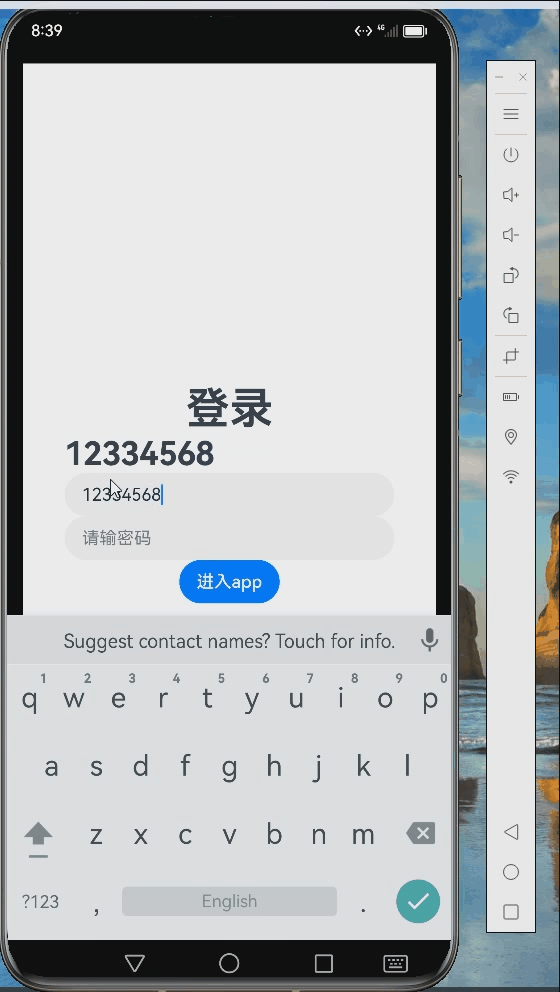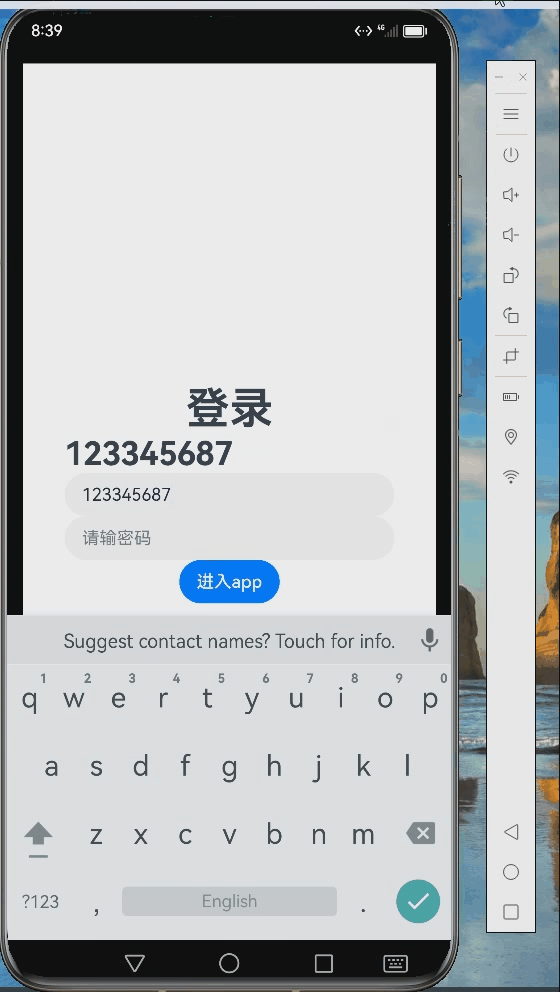
五、模型调用应用
这是我7月参加训练营完成的作业,调用前面训练好的模型的实际应用。《AI情绪鼓励师》作业







![C++复刻:[滑动侧边栏]](https://img-blog.csdnimg.cn/7da91945df9d488b8f89028e2632e05e.gif)