Dimension Relation Modeling for Click-Through Rate Prediction
摘要
对于长期用户序列行为建模,采用两阶段方法,第一阶段检索出相关子序列,第二阶段应用注意力机制建模相关子序列和目标物料关系。基于检索的方式是次优的,可能会丢失信息,而且很难平衡检索算法的性能和有效性。
本文提出的SDIM(Sampling-based Deep Interest Modeling),基于采样的端到端的方法来建模长期用户行为序列。从多个hash函数中采样产生候选物料和用户序列行为的hash签名,然后直接聚合具有和候选物料相同的hash签名的行为序列,得到用户的长期序列兴趣向量。
1. 简介
针对建模用户的兴趣,提出了各种模型。DIN通过考虑给定一个目标项目的历史行为的相关性,自适应地计算用户的兴趣。DIN引入了一种新的注意力机制,其中目标物料作为查询Q,历史用户行为作为关键K和值v。由于其优越的性能,基于DIN的方法近年来已成为用户兴趣建模的主流解决方案。但是,对在线服务时间的严格要求限制了可以使用的用户行为序列的长度。因此,大多数工业系统截断了用户行为序列,只提供最近的50个行为用于用户兴趣建模,从而导致信息丢失。随着互联网的快速发展,用户在电子商务平台上积累了越来越多的行为数据。以淘宝为例,他们报告说23%的用户在六个月内在淘宝APP上有超过1000种行为。在美团APP中,有超过60%的用户至少有1000种行为,超过10%的用户在一年内至少有5000种行为。如何有效地利用更多的用户行为来进行更准确的用户兴趣估计,在工业系统中变得越来越重要。
最近,人们提出了一些方法来从长行为序列中模拟用户的长期兴趣[3,10-12]。MIMN [10]通过设计一个单独的用户兴趣中心(UIC)模块,将用户兴趣建模与整个模型解耦。虽然UIC可以节省大量的在线服务时间,但它使得CTR模型不可能利用来自目标项目的信息,这已被证明对用户感兴趣的建模[3]至关重要。因此,MIMN只能模拟较浅的用户兴趣。SIM [11]和UBR4CTR [12]采用了两阶段的框架来处理长期的用户行为。他们从序列中检索top-𝑘相似的项目,然后将这些项目输入后续的注意模块[18]。正如[3]所指出的,这些方法的检索目标与CTR模型的目标是不同的,并且预先训练的离线反向索引嵌入不适合在线学习系统。为了提高检索算法的质量,ETA [3]提出了一种基于LSH的方法,以端到端的方式从用户行为中检索top-𝑘相似项。他们使用局部敏感哈希(LSH)将项目转换为哈希签名,然后根据它们与候选项目的汉明距离检索top-k相似项目。LSH的使用大大降低了计算项目间相似性的成本,ETA比SIM和UBR4CTR获得了更好的结果。
SIM、UBR4CTR和ETA都是基于检索的方法。基于重试的方法存在以下缺点:从整个序列中检索top-k项是次优的,会对用户的长期利益产生有偏的估计。在用户具有丰富的行为的情况下,检索到的top-k项可能都与候选项相似,并且估计的用户兴趣表示将是不准确的。此外,检索算法的有效性和效率也难以达到平衡。以SIM(hard)为例,使用了简单的检索算法,其性能不如其他方法。相比之下,UBR4CTR在复杂检索模块的帮助下取得了显著的改进,但其推理速度变慢了4×的[12],这阻止了UBR4CTR在线部署,特别是对于长期用户行为建模。
在本文中,我们提出了一种简单的基于哈希抽样的方法来建模长期用户行为。首先,我们从多个哈希函数中进行采样,以生成目标项和用户行为序列中的每个项的哈希签名。我们没有使用特定的度量来检索top-𝑘相似的项,而是直接从整个序列中收集与目标项共享相同哈希签名的行为项,以形成用户的兴趣。我们的方法的内在思想是用LSH碰撞概率近似用户兴趣的软最大分布。我们从理论上证明,这种简单的基于抽样的方法产生了与基于软tmax的目标注意非常相似的注意模式,并实现了一致的模型性能,同时更有效。因此,我们的方法的行为就像直接在原始的长序列上计算注意力,而没有信息丢失。我们将该方法命名为SDIM(即基于采样的深度兴趣建模)。
我们还介绍了我们关于在线部署SDIM的实际实践。具体来说,我们将我们的框架解耦为两部分: (1)行为序列哈希(BSE)服务器,和(2) CTR服务器,其中这两个部分是分别部署的。行为序列哈希是整个算法中最耗时的部分,而这部分的解耦大大减少了服务时间。更多的细节将在第4.4节中介绍。
我们在公共和工业数据集上都进行了实验。实验结果表明,SDIM取得了与基于注意的标准方法一致的结果,并且在对长期用户行为的建模方面优于所有竞争基线,并具有相当大的速度。SDIM已部署在中国最大的生活方式服务电子商务平台美团2的搜索系统中,带来了2.98%的CTR和2.69%的VBR提升,这对我们的业务非常重要。综上所述,本文的主要贡献总结如下:
我们提出了SDIM,一个基于哈希采样的框架,用于建模CTR预测的长期用户行为。我们证明了这种简单的基于抽样的策略产生了与目标注意非常相似的注意模式。
我们详细介绍了我们关于在线部署SDIM的实际实践。我们相信这项工作将有助于推进社区,特别是在建模长期用户行为方面。
在公共和工业数据集上进行了大量的实验,结果证明了SDIM在效率和有效性方面的优越性。SDIM已部署在美团的搜索系统中,对业务有了重大改善。
2. 相关工作
长期用户序列建模
用户行为建模在工业应用中表现出了良好的性能。在CTR模型中探索更丰富的用户行为已经引起了广泛的关注。然而,长期的用户行为建模面临着一些挑战,如复杂的模型部署和系统延迟。在MIMN [10]中,提出了具有基于内存的架构设计的用户兴趣中心(UIC)块来解决这一挑战。该块由用户行为事件更新,并且只需要存储有限的用户兴趣内存。MIMN很难建模用户行为序列和目标项目之间的交互,这在CTR建模中被证明是重要的。在SIM [11]中,提出了一种两阶段的方法来建模长期的用户行为序列。首先,利用通用搜索单元(GSU)提取与目标项目相关的相关行为。其次,提出了一个精确的搜索单元来端到端建模相关行为。UBR4CTR [12]使用了与SIM [11]类似的基于搜索的方法来面对挑战。最近,ETA [3]提出了一种端到端目标注意方法来建模长期用户行为序列。他们应用局部敏感哈希(LSH)来减少训练和推理的时间成本。除了上述在CTR预测领域的相关工作外,在自然语言处理(NLP)领域也有大量旨在提高自我注意[6,15,16,19]效率的工作。这些方法可以降低自注意从𝑂(𝐿2)到𝑂(𝐿log(𝐿))的时间复杂度,其中𝐿为序列长度,但不能用于降低目标注意的𝑂(𝐿)时间复杂度。
3. 模型方法
我们将介绍在系统中实现SDIM的框架。在下图中可以看到一个抽象的概述。该框架由两个独立的服务器组成:行为序列编码(BSE)服务器和CTR服务器,这将在后面详细介绍。
3.1 User Behavior Modeling via Hash-Based Sampling
Hash Sampling-Based Attention 和ETA一样,我们从多个hash函数中采样生成用户序列行为和候选物料的hash签名。ETA选择用hash签名的汉明距离来近似用户的兴趣,选择topK相关的用户子序列,这里SDIM剔除一个更有用及有效的方法来预估用户的兴趣。
由于局部保留属性(locality-preserving),相似的向量以高概率落在同一哈希桶中,因此用户行为项和候选物料之间的相似性可以用它们具有相同哈希码(签名)的频率或碰撞概率来近似。这使得我们假设哈希碰撞的概率可以是用户兴趣的有效估计器。
在此基础上,我们提出了一种利用LSH获取用户兴趣的新方法。在哈希之后,我们通过将与具有相同签名的候选项q相关联的行为项s𝑗相加,直接形成用户的兴趣。在单个哈希函数r中,所提出的估计用户兴趣的方法可以通过以下方法来计算。
输入的行为embedding向量为
x
∈
R
d
\mathbf x \in R^d
x∈Rd,hash函数向量为
r
∈
R
d
\mathbf r \in R^d
r∈Rd,其中
r
i
∼
N
(
0
,
1
)
r_i \sim N(0, 1)
ri∼N(0,1),hash计算过程如下
h
(
x
,
r
)
=
s
i
g
n
(
r
T
x
)
=
±
1
h(\mathbf x, \mathbf r) = sign (\mathbf r^T \mathbf x) = \pm 1
h(x,r)=sign(rTx)=±1
如果输入向量
x
1
\mathbf x_1
x1和向量
x
2
\mathbf x_2
x2相似,那么他们的hash码相同
P
(
r
)
=
1
h
(
x
1
,
r
)
=
h
(
x
2
,
r
)
P^{(r)} = 1_{h(\mathbf x_1, \mathbf r) = h(\mathbf x_2, \mathbf r)}
P(r)=1h(x1,r)=h(x2,r)
上面hash是对每个维度使用一个hash函数,实际应用中每个维度使用多个hash函数,能有效降低碰撞概率,假设采用 m m m个hash函数,则有hash函数矩阵 R ∈ R m × d \mathbf R \in R^{m \times d} R∈Rm×d
h ( x , R ) = s i g n ( R x ) ∈ R m h(\mathbf x, \mathbf R) = sign(\mathbf R \mathbf x) \in R^{m} h(x,R)=sign(Rx)∈Rm
这样就得到了输入向量的hash签名(长度为 m m m),然后再将hash签名分隔成 τ \tau τ组,每组视作一个hash桶,用这个hash桶作为索引,保存落入到这个hash桶的输入embedding列表,并对每个embedding使用L2归一化。
下图是 m = 4 m=4 m=4且 τ = 2 \tau =2 τ=2,将每个序列行为embedding hash成4个bit,然后这4个bit分成2组(黄色和绿色2组),然后每组的签名值作为key建立索引,保存对应的经过L2归一化的embedding。
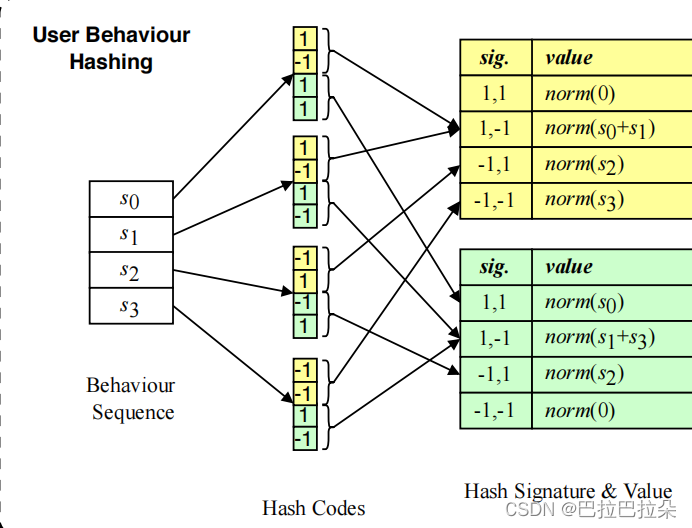
对于序列行为
s
j
\mathbf s_j
sj,候选物料为
q
\mathbf q
q,那么根据用户序列可以得到用户行为向量
l
2
(
P
(
r
)
S
)
=
l
2
(
∑
j
=
1
L
p
j
(
r
)
s
j
)
l_2(\mathbf P^{(\mathbf r)} \mathbf S)=l_2(\sum_{j=1}^L\mathbf p_j^{(\mathbf r)} \mathbf s_j)
l2(P(r)S)=l2(j=1∑Lpj(r)sj)
其中
S
\mathbf S
S为用户序列Embedding,
p
j
r
=
{
0
,
1
}
\mathbf p_j^{r}=\{0, 1\}
pjr={0,1},当序列
s
j
\mathbf s_j
sj和候选物料
q
\mathbf q
q在hash函数向量
r
\mathbf r
r下的签名一样时为1,否则为0。
q
j
(
r
)
=
1
h
(
s
j
,
r
)
=
h
(
q
,
r
)
\mathbf q^{(r)}_j=1_{ h(\mathbf s_j, \mathbf r) = h(\mathbf q, \mathbf r)}
qj(r)=1h(sj,r)=h(q,r)
用户兴趣表示为和候选物料签名一致的序列向量的attention值
A
t
t
e
n
t
i
o
n
(
q
,
S
)
=
1
m
/
τ
∑
i
=
1
m
/
τ
l
2
(
P
(
r
i
)
S
)
=
1
m
/
τ
∑
i
=
1
m
/
τ
l
2
(
∑
j
=
1
L
p
j
(
r
i
)
s
j
)
Attention(\mathbf q, \mathbf S)=\frac{1}{ {m}/ {\tau} } \sum_{i=1}^{m/ \tau} l_2(\mathbf P^{(\mathbf r_i)} \mathbf S) = \frac{1}{ {m}/ {\tau} } \sum_{i=1}^{m/ \tau} l_2( \sum_{j=1}^L \mathbf p^{(\mathbf r_i)}_j \mathbf s_j)
Attention(q,S)=m/τ1i=1∑m/τl2(P(ri)S)=m/τ1i=1∑m/τl2(j=1∑Lpj(ri)sj)
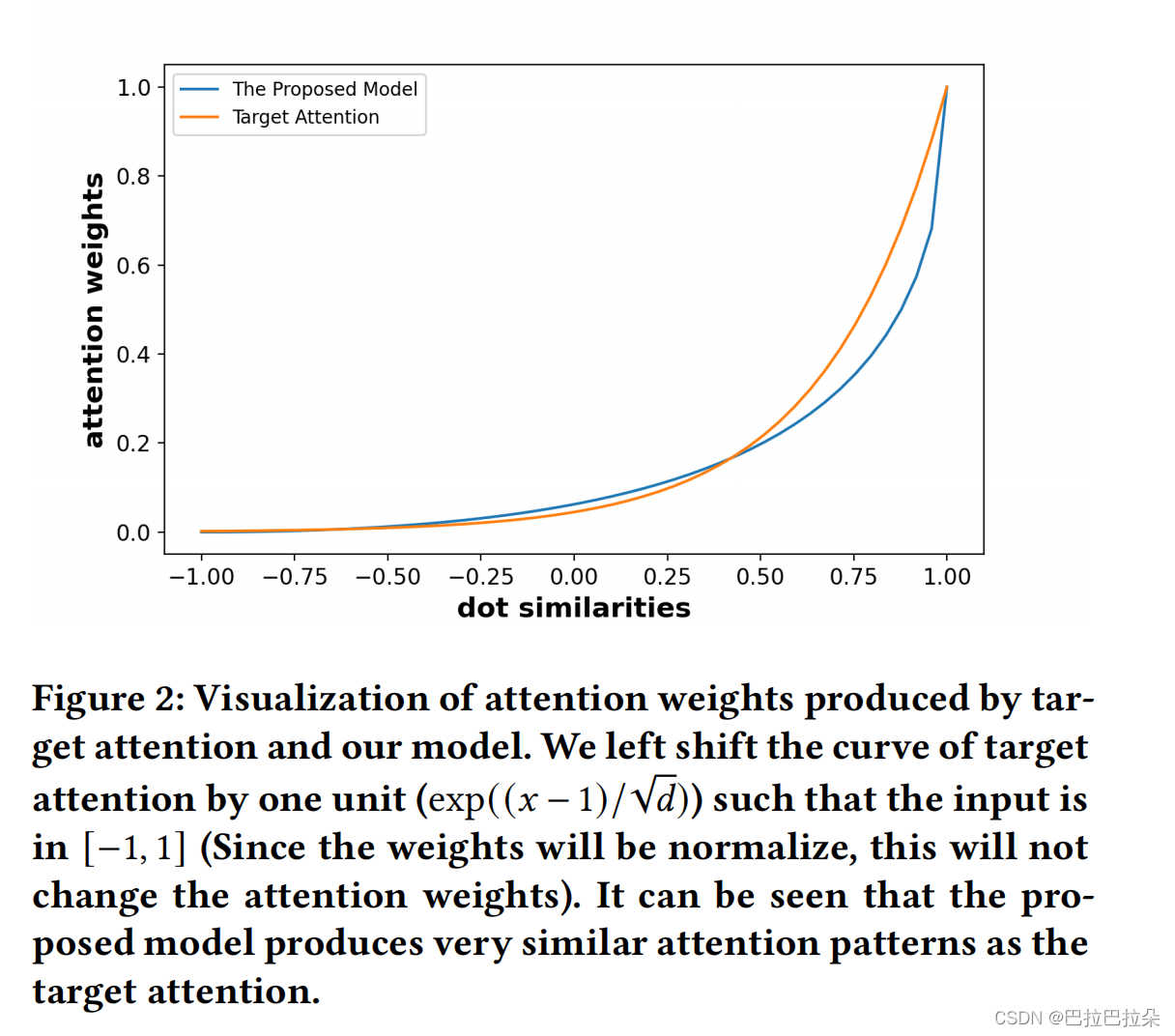
相当于直接在用户长期序列上面做attention操作,具体证明如下:

attention权重和
τ
\tau
τ的关系
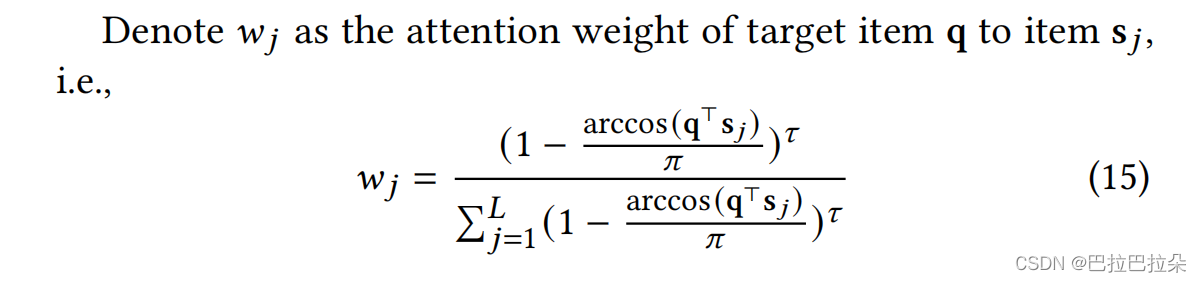
3.2 复杂度分析
序列长度为 L L L,Embedding维度为 d d d,候选物料数量为 B B B,DIN使用attention的时间复杂度为 O ( L ∗ B ∗ d ) O(L*B*d) O(L∗B∗d)。当模型训练好之后,用户的兴趣向量就固定了,与infer时具体的候选物料就无关了,因此每次请求只需要计算一次用户序列的hash转换,在时间复杂度上相当于将 B B B降为1,这相比标准的attention计算要快非常多。SDIM最耗时的地方在于计算用户序列的hash转换,将 L L L个 d d d维序列向量转为 m m m维的hash编码向量,时间复杂度为 O ( L ∗ m ∗ d ) O(L*m*d) O(L∗m∗d),可以通过 Approximating Random Projection algorithm近似算法降低到 O ( L ∗ m ∗ log ( d ) ) O(L*m*\log(d)) O(L∗m∗log(d)),因为 m ≪ L m \ll L m≪L,且 d ≪ log ( d ) d \ll \log(d) d≪log(d),因此速度有很大提升,在美团场景有10-20倍的提升。
4. 部署
将系统分为2部分 Behavior Sequence Encoding (BSE) server 和 CTR Server
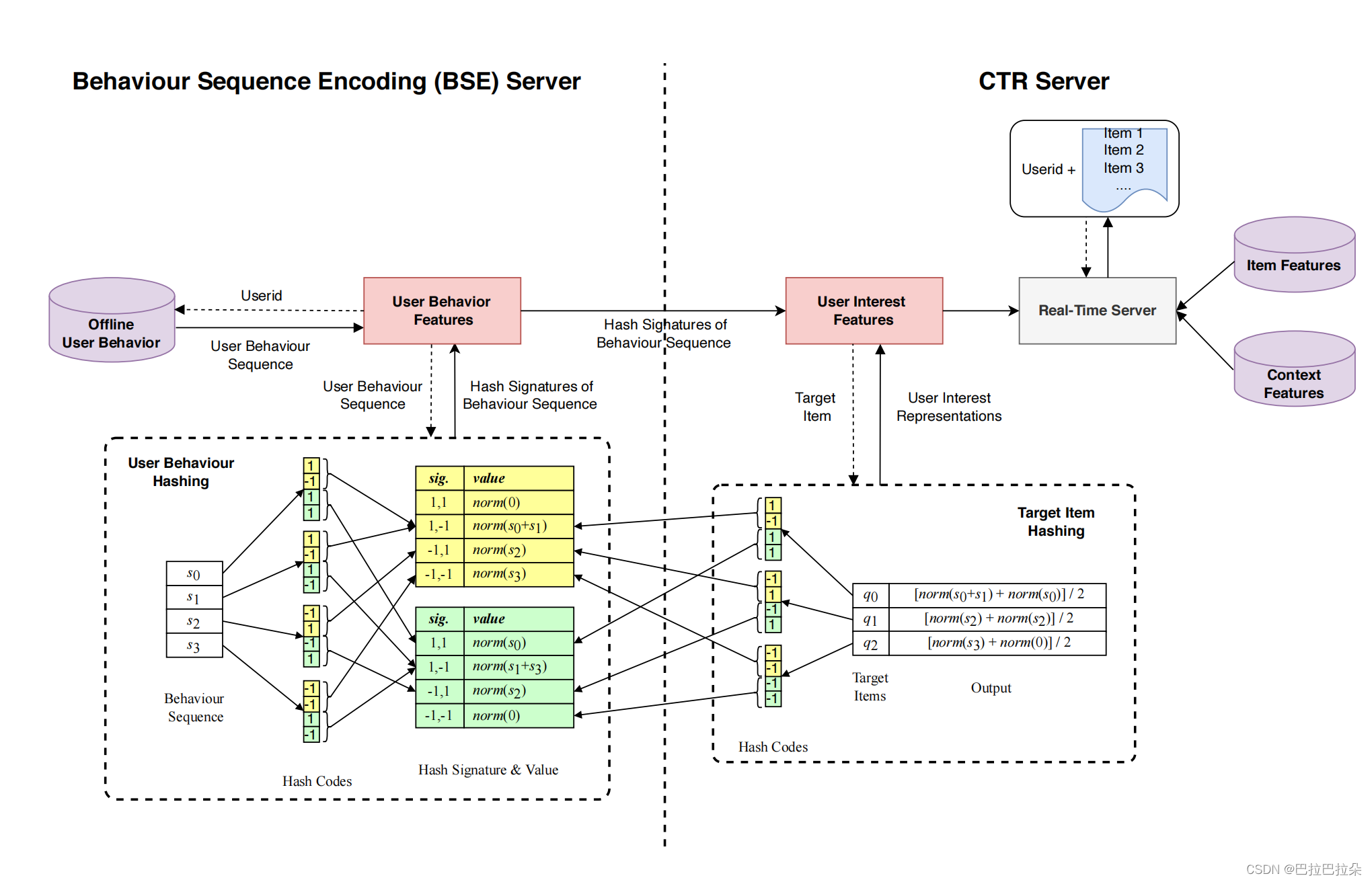
CTR模型结构如下图
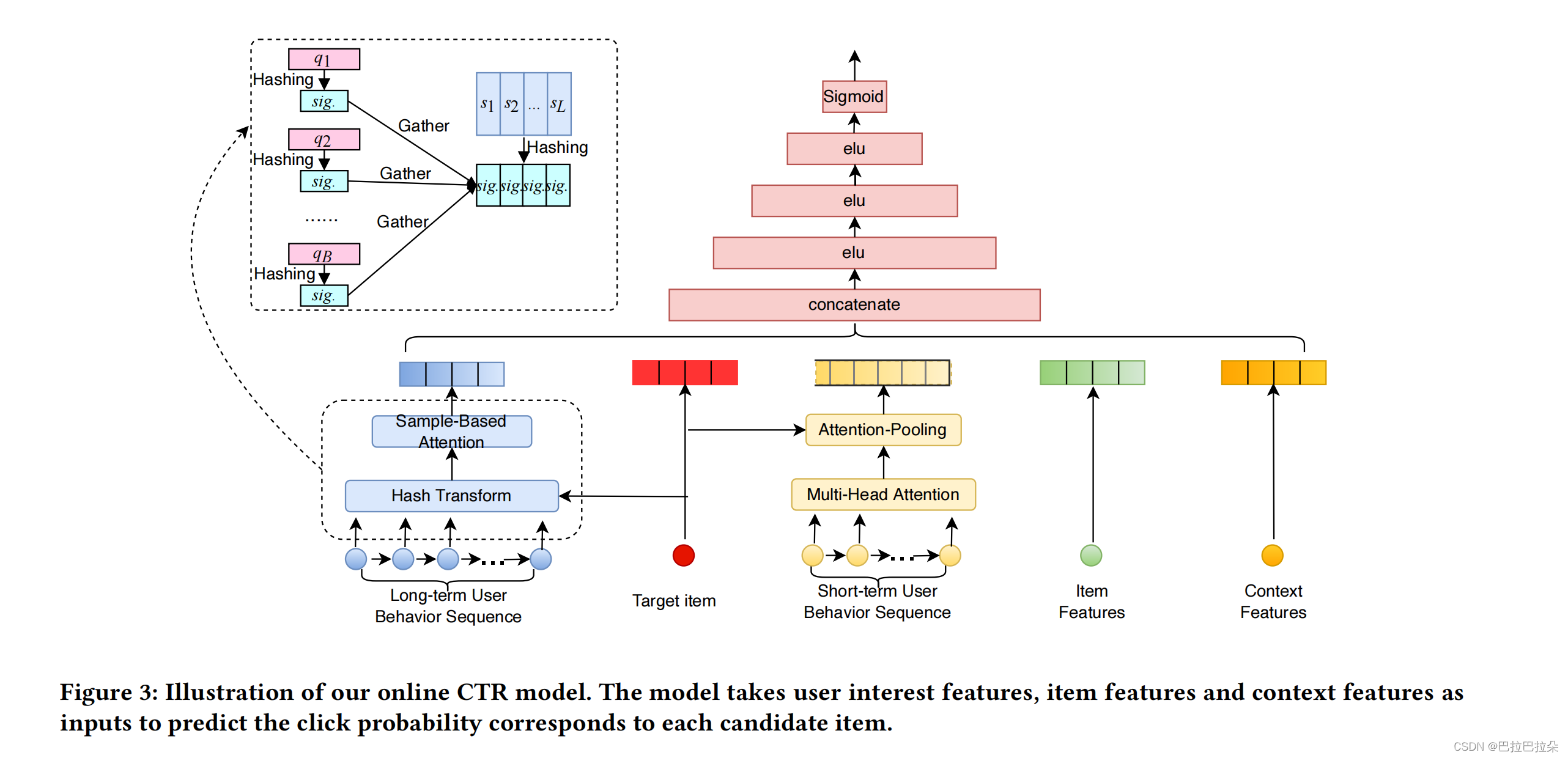
5. 实验
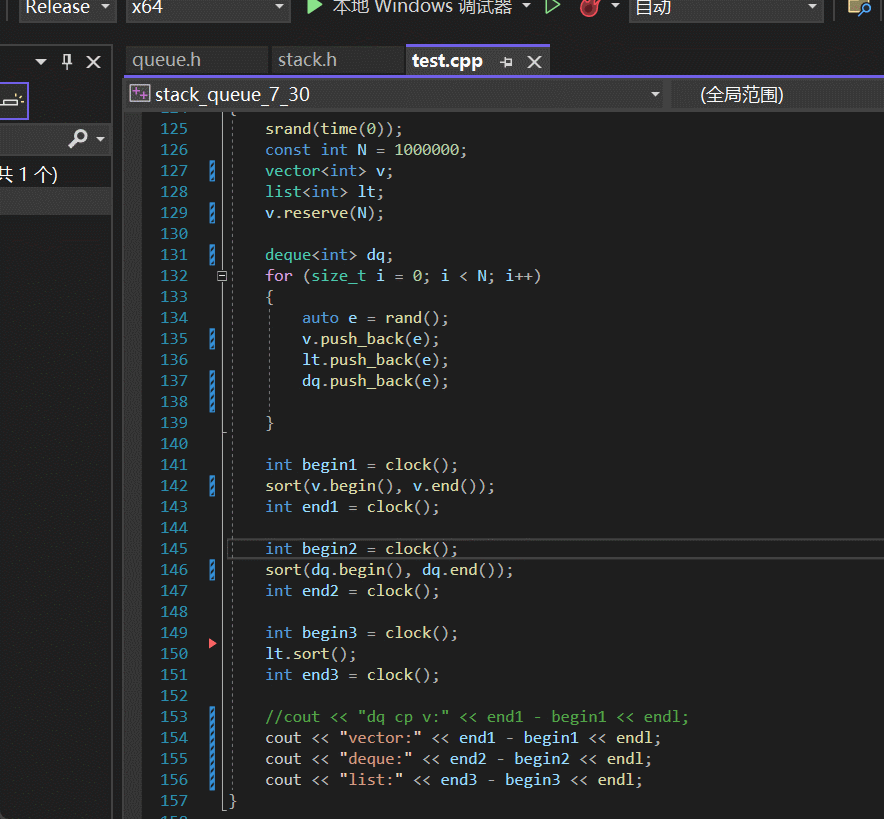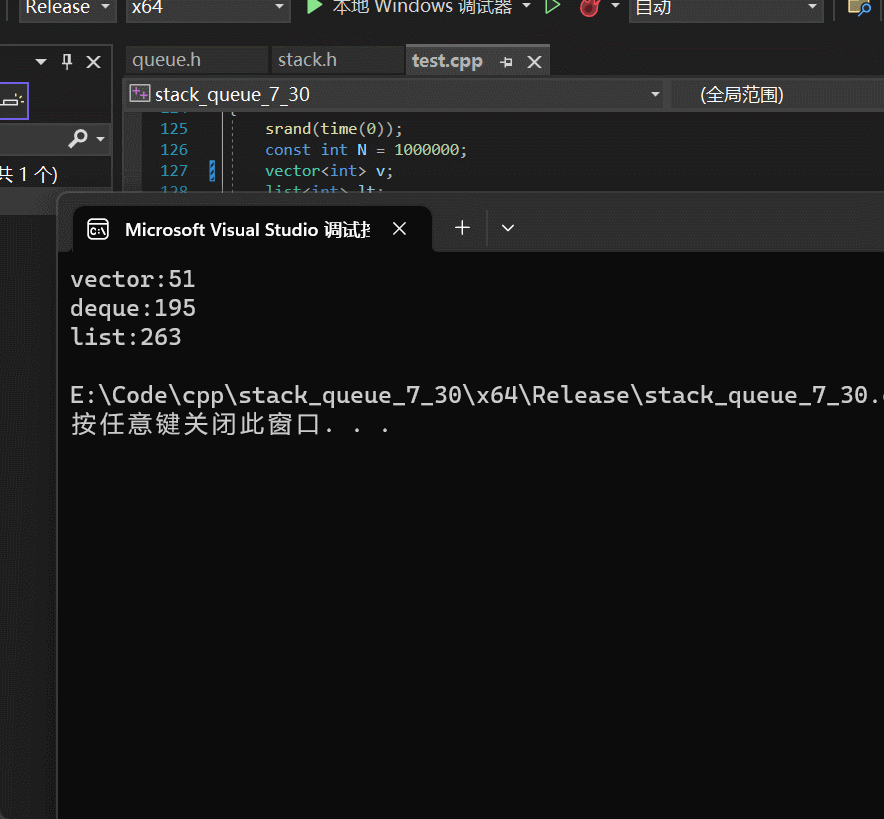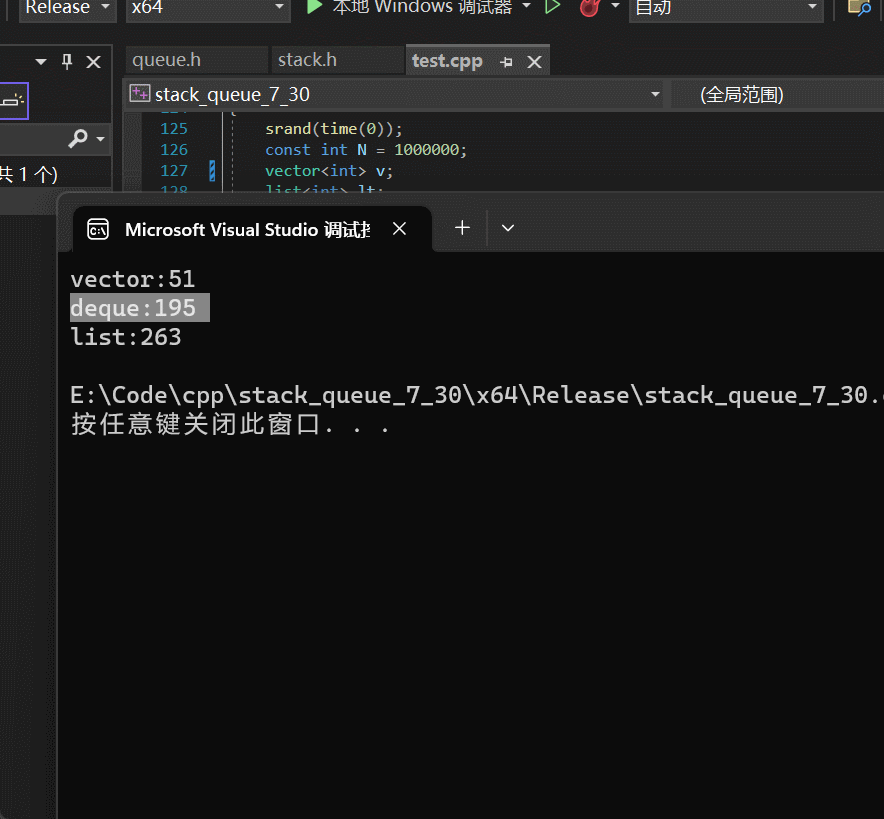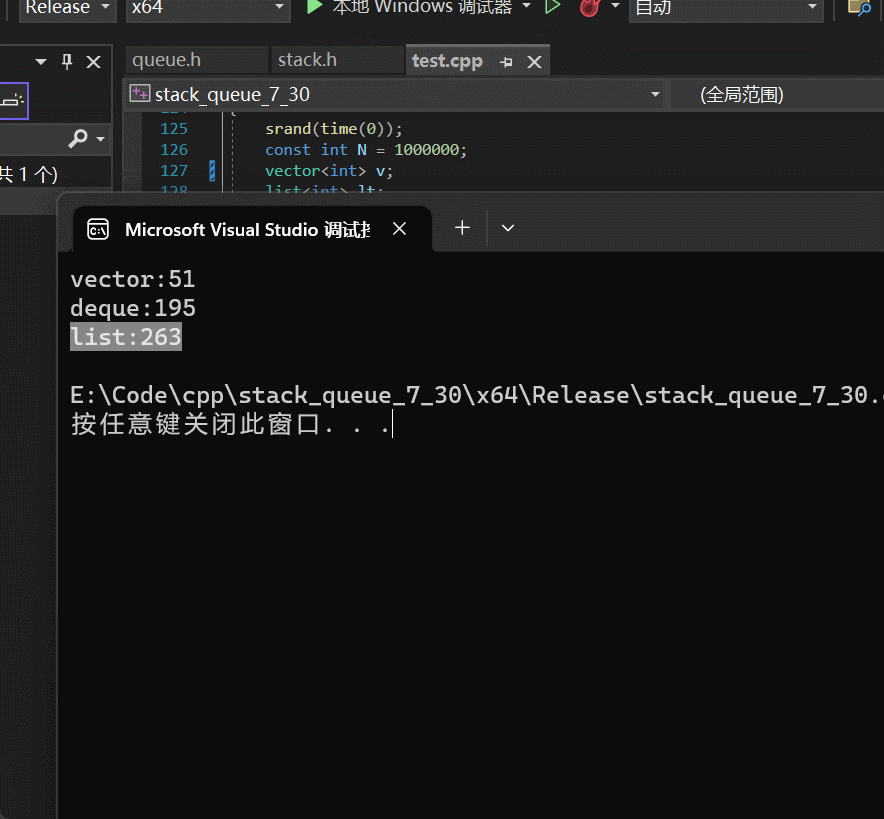
在taobao数据集上面的AUC及速度提升

在工业数据集上面的AUC及速度提升
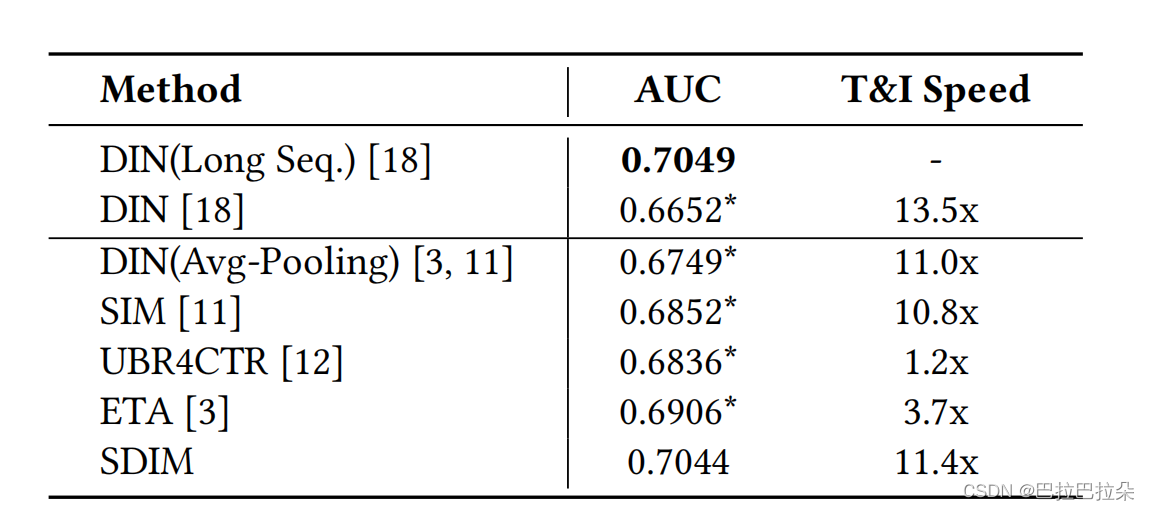
T=256 for Taobao and T=1024 for industrial dataset
超参数分析
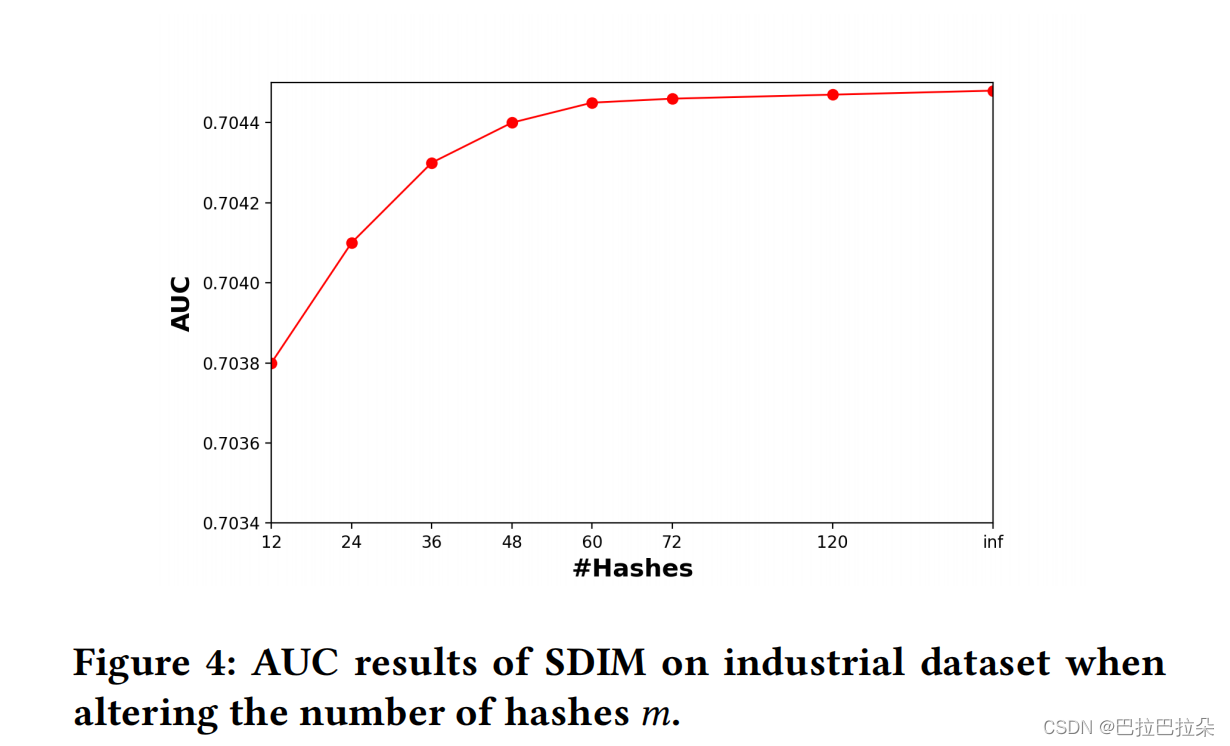
hash函数数量
m
m
m,当
m
>
48
m>48
m>48时几乎不变,线上取48.
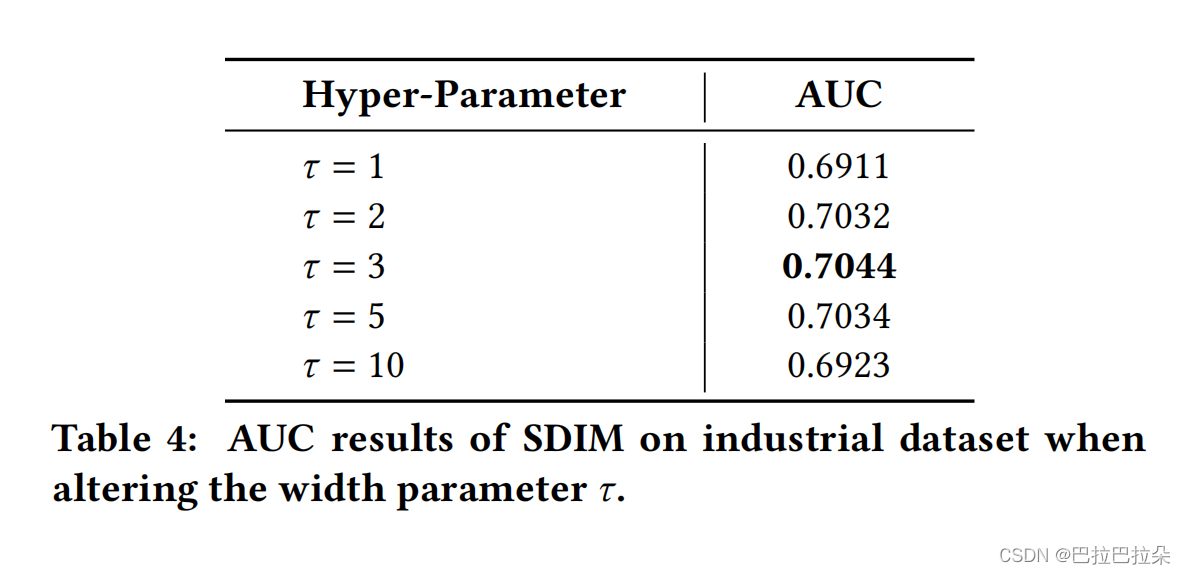
hash签名的宽度 τ \tau τ
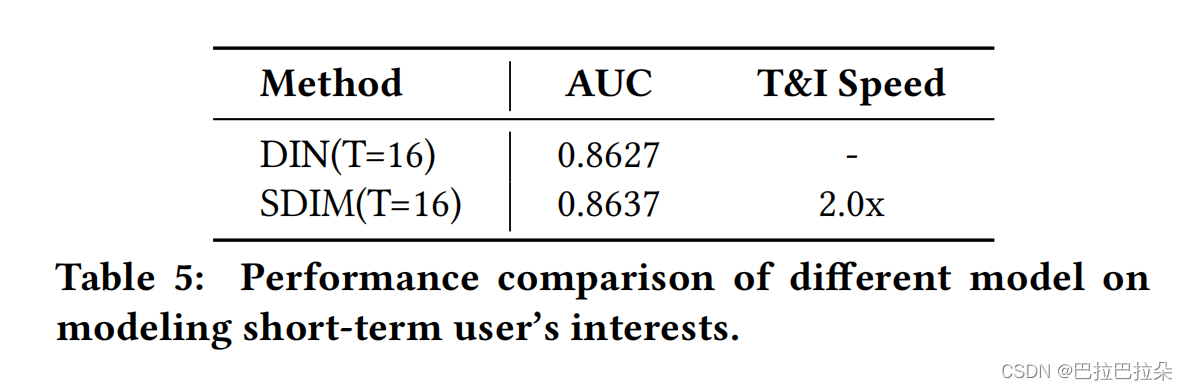
短期用户兴趣建模上的表现,SDIM也要好些,而且速度有2倍提升。
总结
通过使用hash函数签名的方式处理长期用户序列建模,摒弃了一贯使用的attention方式,开创了新的用户序列提取方式,在效果及效率上有显著提升。