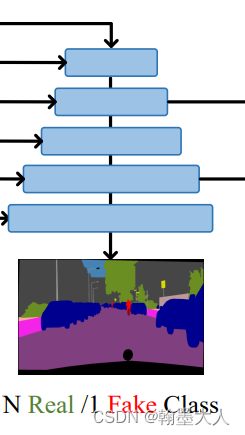
在前面我们看了生成器和判别器的组成。
生成器损失公式:

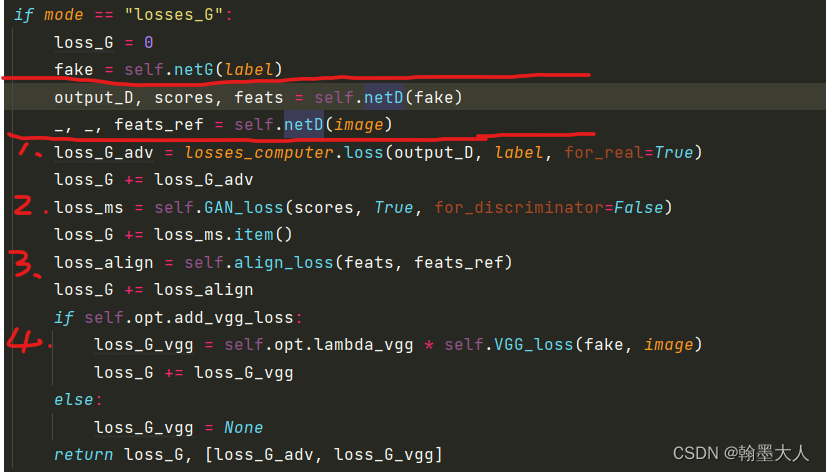
首先将fake image 和真实的 image输入到判别器中:
接着看第一个损失:参数分别为fake image经过判别器的输出mask,和真实的label进行损失计算。对应于:
其中loss对应于:
class losses_computer():
def __init__(self, opt):
self.opt = opt
if not opt.no_labelmix:
self.labelmix_function = torch.nn.MSELoss()
def loss(self, input, label, for_real):#true
#--- balancing classes ---
weight_map = get_class_balancing(self.opt, input, label)
#--- n+1 loss ---
target = get_n1_target(self.opt, input, label, for_real)
loss = F.cross_entropy(input, target, reduction='none')
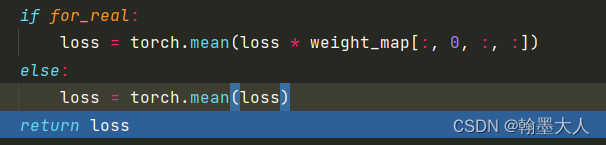
if for_real:
loss = torch.mean(loss * weight_map[:, 0, :, :])
else:
loss = torch.mean(loss)
return loss
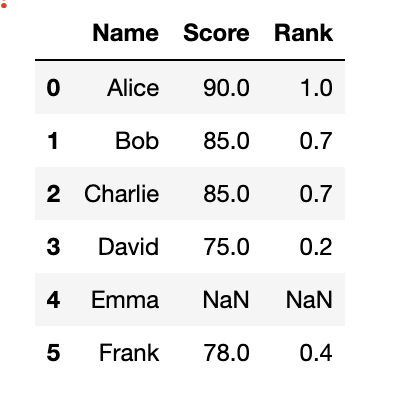
1:首先平衡类别,input大小为(1,36,256,512),label大小为(1,35,256,512).
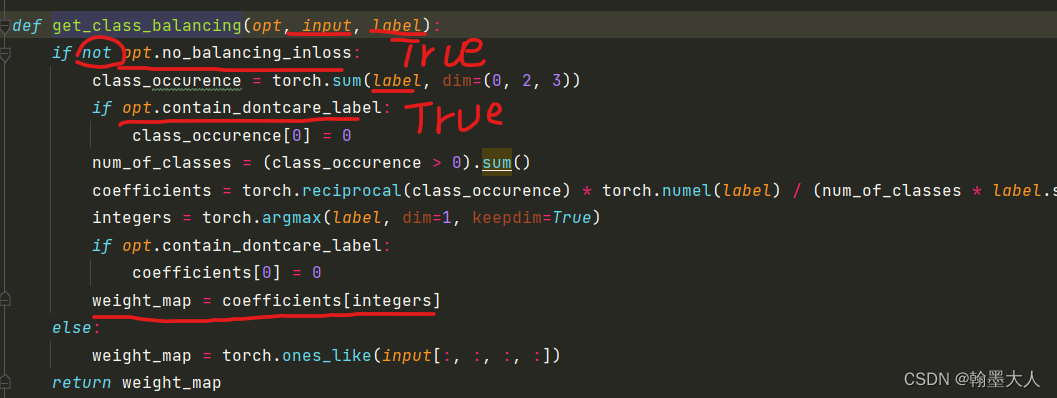
首先将label每个通道所有的值相加,最后只剩下C个值。

接着将class_occurence第一个值替换为0(在标签中第一个值为空).然后将列表值和0进行比较,统计为True的个数,就是总的类别。
然后求总的类别权重,一张图有24个类别,总的标签图有35各类别,缺失的类别为inf。

根据argmax获得label的通道索引,输出通道为一的mask图。

根据类别找对应的权重值。

接着标签和label输入到: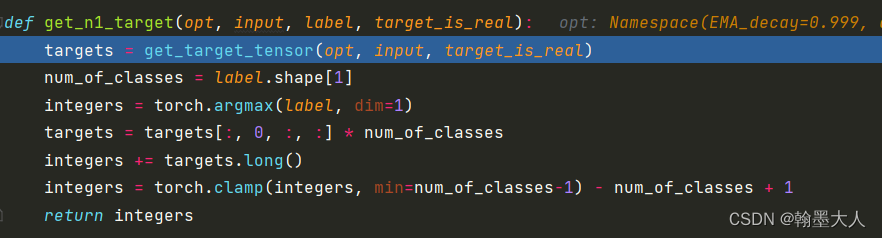
首先得到一个和input相同大小的全1矩阵。这个矩阵是放在cuda上,用1填充,不需要更新,和input相同维度。
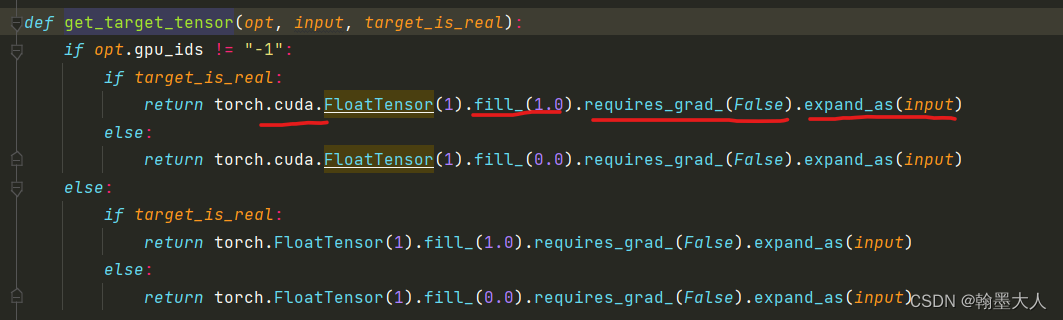
接着取label的索引,将全1矩阵target压缩通道维度和numclass相乘,这样所有的值都是35,在和label的类别值相加。因为相加之后的值肯定大于35,即clamp将小于34的值替换为34.(感觉clamp并没有起作用),减去35加1,相当于将label类别值全部加1了。
最后将辨别器的decoder输出和真实的label进行交叉熵计算。

将loss和类别权重相乘,再求均值得到最终的损失。
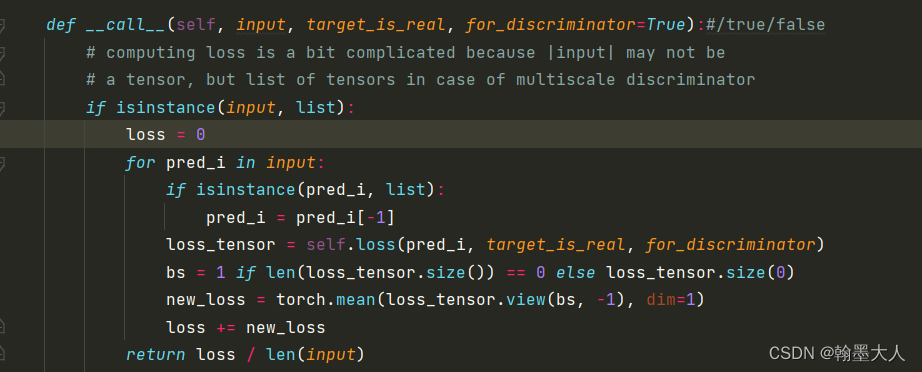
接着是第二个损失:生成器希望生成的结果可以骗过判别器,fake产生的图片要尽可能的真实。

score是判别器encoder部分的两个输出。
在GANloss中:
在loss中:
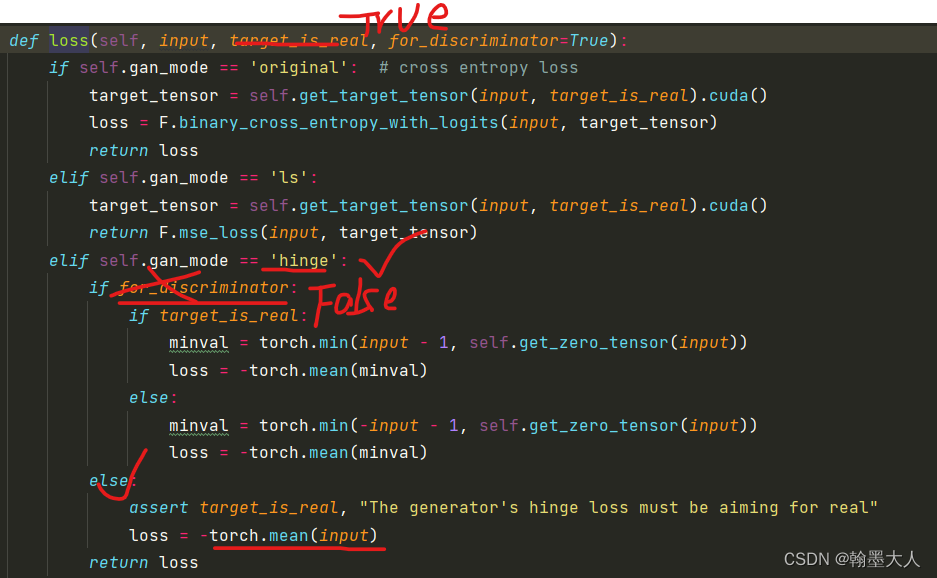
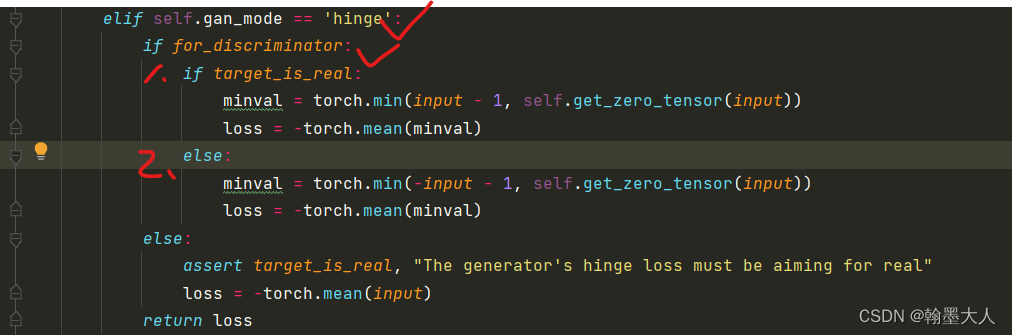
生成器是不完全执行patch_loss,为了使损失更小,则-1+D(x)就要趋近于0,因为D最后是输出一个通道为1的值,即经过sigmoid每个像素输出值在[0,1]之内,为了使-1+D(x)最小,则输出就要尽可能为1,即输出要尽可能正确。

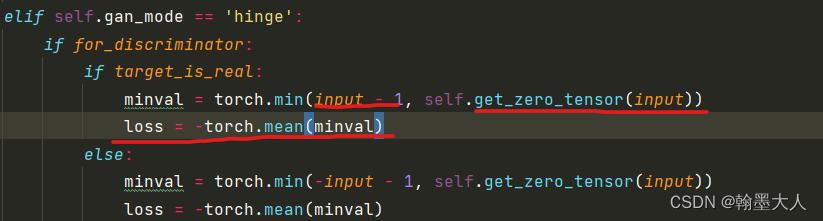
得到的两个GANloss相加求均值,再和之前的对抗损失相加。
第三个是特征匹配损失:输入是real image和fake image经过decoder的五个中间变量输出。

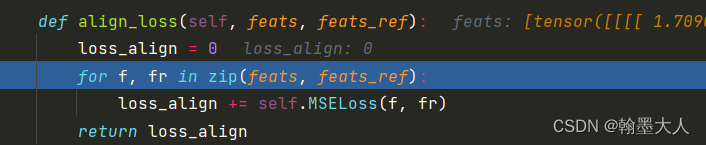
通过循环计算每一个输出对之间的MSE损失。
将生成的结果和前面两种损失相加。
最后输出:总损失,[对抗损失,None]。

接着损失取均值,然后反向传播。
然后说判别器的损失:
按照公式:GAN loss需要计算fake image 和 real image产生的中间变量,然后相加。而生成器不用计算E(z,l)。
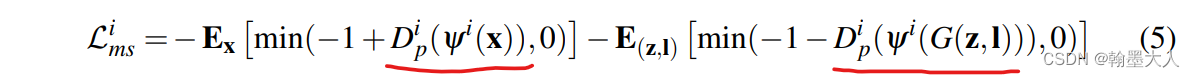
在代码中通过控制target的True和False来计算两个loss。
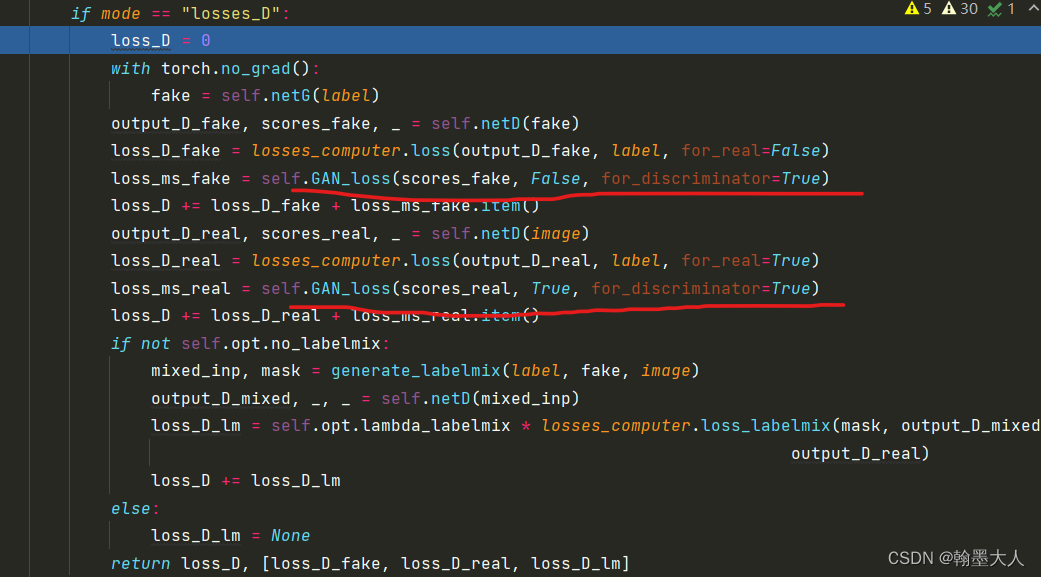
损失包含:
1:fake image经过判别器得到的mask和真实的label计算对抗损失。
2:real image经过判别器得到的mask和真实的label计算对抗损失。
3:两个GAN loss。
4:label mix

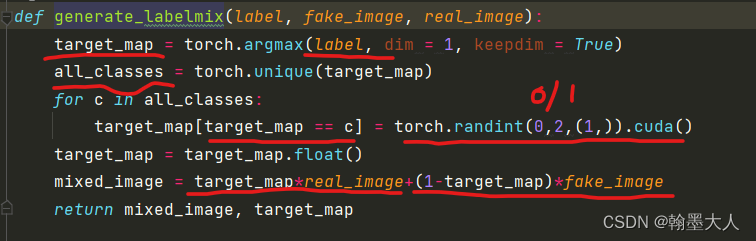
首先获得label上的类别值,然后遍历类别值,将mask中的类别随机替换为0或者1,然后和真实的image相乘,对target_map取反后和fake_image相乘最后相加。最终输出混合的image和新的target_map。
混合的image输入判别器中后计算labelmix损失:
四个参数:进过[0,1]替换后的mask,mix_image经过判别器的输出,fake_image经过判别器的输出和real_image经过判别器的输出。

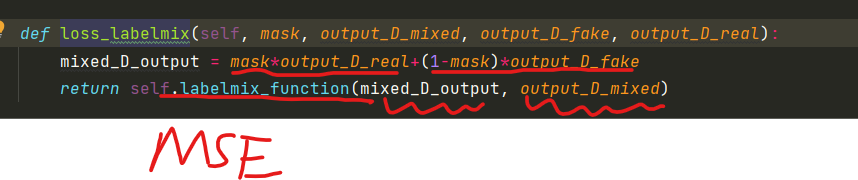
生成的label_mix loss和原始的三个loss相加。
这样就计算完了辨别器损失。



![[python]conda激活环境后pip -V显示在base路径](https://img-blog.csdnimg.cn/09a1978d3519414990960ceb6c1bd6cf.jpeg)

![#P0994. [NOIP2004普及组] 花生采摘](https://img-blog.csdnimg.cn/img_convert/0c1bbf5fb275efb7c8e5f8f26d037929.png)