【问题】
Here's the problem statement:
In a folder in HDFS, there're a few csv files with each row being a record with the schema (ID, attribute1, attribute2, attribute3).
Some of the columns (except ID) could be null or empty strings, and no 2 records with the same ID can have the same non-empty value.
We'd like to merge all records with the same ID, and write all merged records also in HDFS. For example:
Record R1: ID = 1, attribute1 = "hello", attribute2 = null, attribute3 = "";
Record R2: ID = 1, attribute1 = null, attribute2 = null, attribute3 = "testa";
Record R3: ID = 1 attribute1 = null, attribute2 = "okk", attribute3 = "testa";
Merged record should be: ID = 1, attribute1 = "hello", attribute2 = "okk", attribute3 = "testa"
I'm just starting to learn Spark. Could anybody share some thoughts on how to write this in Java with Spark? Thanks!
Here're some sample csv files:
file1.csv:
ID,str1,str2,str3
1,hello,,
file2.csv:
ID,str1,str2,str3
1,,,testa
file3.csv:
ID,str1,str2,str3
1,,okk,testa
The merged file should be:
ID,str1,str2,str3
1,hello,okk,testa
It's known beforehand that there won't be any conflicts on any fields.
Thanks!
【回答】
复述问题:有N个文件相当于N条记录,逻辑上按ID分为M个组,将每组整理为一条记录,第2-4字段的值为将本组记录中该字段的第一个非空取值,如果都空,则本字段也为空。
JAVA(Spark包)写些代码较为复杂,可考虑用SPL实现,代码简单易懂,也能直接访问HDFS:
| A | |
| 1 | =["file1.csv","file2.csv","file3.csv"].("hdfs://192.168.1.210:9000/user/hfiles/"+~) |
| 2 | =hdfs_client(;"hdfs:// 192.168.1.210:9000") |
| 3 | =A1.conj(hdfs_file(A2,~).import@ct()) |
| 4 | =A3.group(#1) |
| 5 | =A4.new(#1,~.(#2).select@1(~),~.(#3).select@1(~),~.(#4).select@1(~)) |
| 6 | =hdfs_file(A2,"/user/hfiles/result.csv").export@tc(A5) |
A1:拼成字符串序列
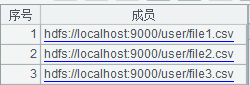
A2:连接hdfs文件系统
A3:读取每个文件中的内容,并将数据合并到一起。

A4:按照第一列分组
A5:将每组整理为一条记录,第2-4字段的值为将本组记录中该字段的第一个非空取值。
A5还可简化为:=A4.new(#1,${to(2,4).("~.(#"/~/").select@1(~)").concat@c()})
A6:写入结果文件
上述代码很容易和JAVA集成(可参考Java 如何调用 SPL 脚本)。












![[附源码]JAVA毕业设计疫情防控期间人员档案追演示录像上(系统+LW)](https://img-blog.csdnimg.cn/f2d6fcefe57d4b3ca9bdebe74f2f62ae.png)