随着最近半年 ChatGPT 火爆全球,基于 Transformer 架构的大语言模型(LLM)逐渐走入大众视野,可以说,Transformer 在AI 领域的影响力绝不亚于变形金刚在科幻领域的影响力。
Transformer 的核心思想是使用自注意力机制(Self-Attention Mechanism)来建立序列之间的依赖关系。就在2年前,很多模型主要还是基于长短期记忆(LSTM)和递归神经网络(RNN)的其他变体,而如今大语言模型都是基于 Transformer 的注意力机制。AI领域从传统机器学习,到神经网络,再到如今的 Transformer,正以井喷的势头快速发展。
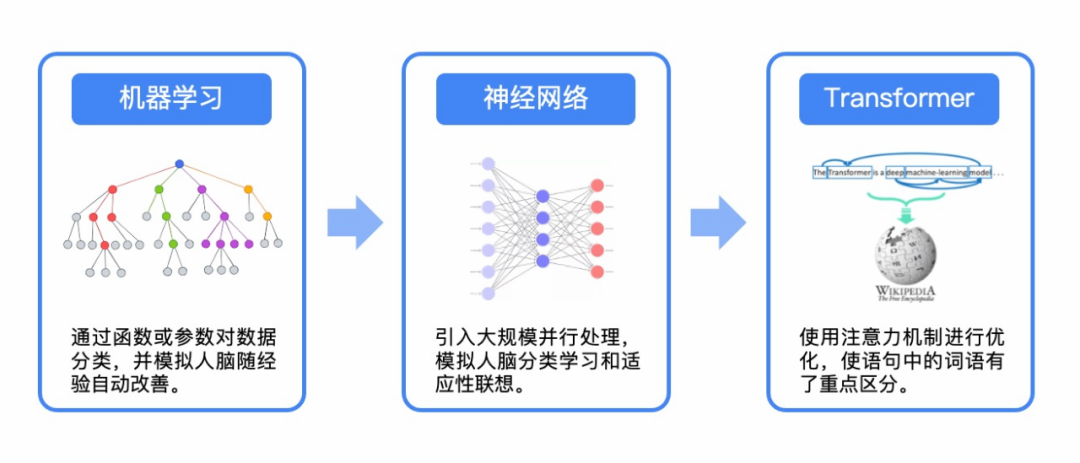
人工智能发展方向
当下大语言模型市场百(xuè)花(yǔ)齐(xīng)放(fēng),因此我们整理了一份可能是全网最全的大语言模型盘点,以期大家抓住 AIGC 的时代脉搏。
阅读和收藏本文,你将了解:
-
全球大语言模型发展脉络和族谱矩阵
-
谷歌、微软两大阵营大语言模型迭代历程
-
全球和国内主要大语言模型盘点
全球大语言模型发展脉络
下图展示了 2019 年以来百亿参数规模的大语言模型发布的时间线,其中标黄的大模型已开源。可以看到,2022 年至今新模型层出不穷,同时 OpenAI 和 Google 大模型迭代速度明显高于其他厂商。
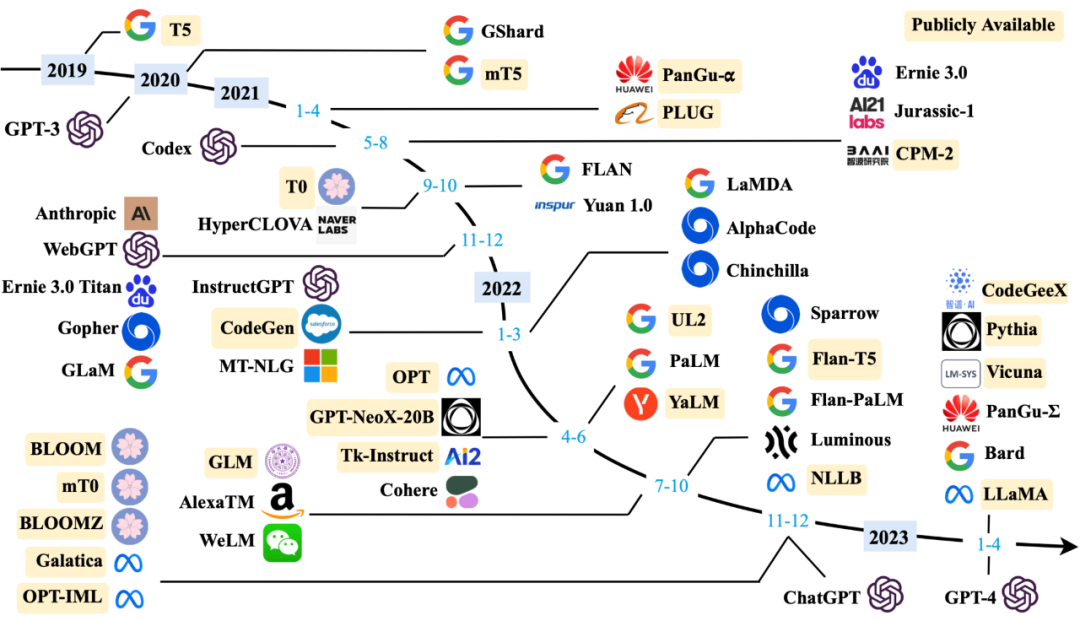
大语言模型发展趋势
全球大语言模型族谱矩阵
下表展示了主要大语言模型的家族谱系,不同颜色代表不同的技术起源。横轴为时间线,纵轴为模型训练的参数规模。自 2018 年以来大语言模型训练规模不断膨胀,从参数规模来看 2022 年也是暴发的一年。
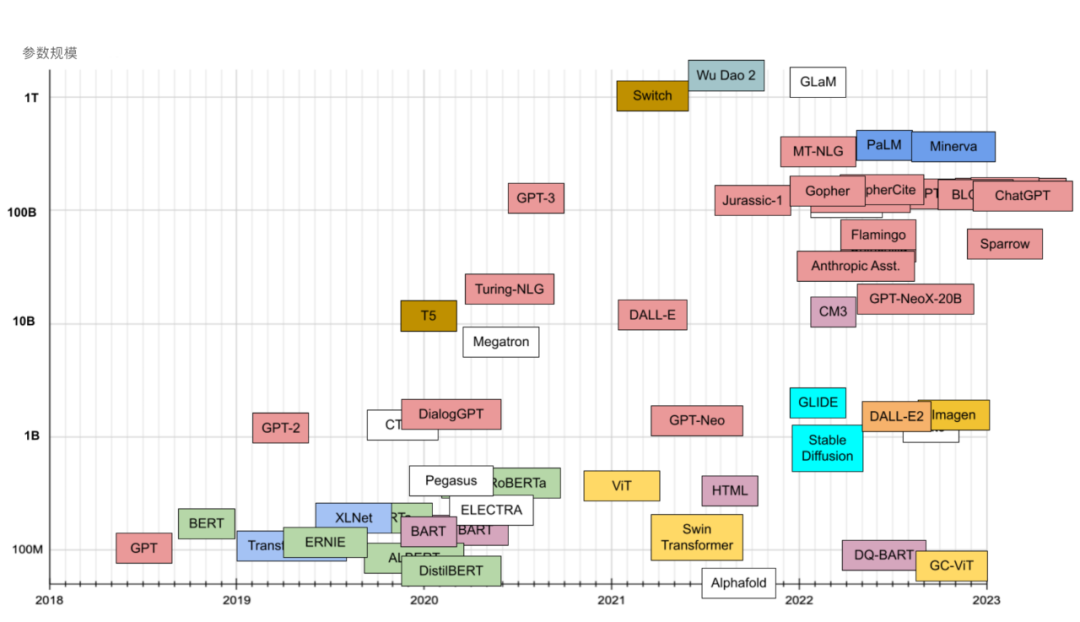
大语言模型参数规模象限
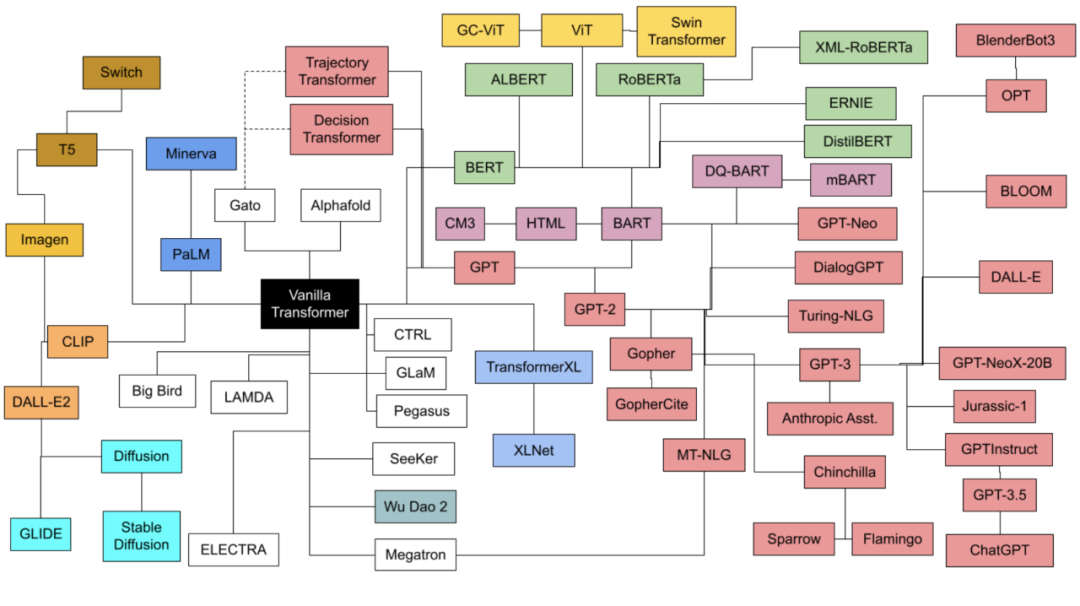
大语言模型技术路线族谱关系
巨头对垒:谷歌与微软竞速持续升级
22 年 11 月 OpenAI 发布基于 GPT-3.5 系列全新对话式 AI 模型 ChatGPT,此次迭代升级具备跨时代意义;今年 2 月微软将 ChatGPT 接入 Bing,重新定义搜索引擎;3 月多模态大型语言模型 GPT-4 发布,在“理解+创造”上展现出更强的能力。
面对 OpenAI 陆续推出的 GPT 系列,谷歌步步紧追,今年 2 月和 3 月分别推出对标 ChatGPT 的 Bard 和史上最大多模态具身视觉语言模型 PaLM-E;5 月 11 日谷歌正式打响“反击战”,发布大语言模型 PaLM2 直指 GPT-4 痛点,同时在 25 余款应用上接入 AI。
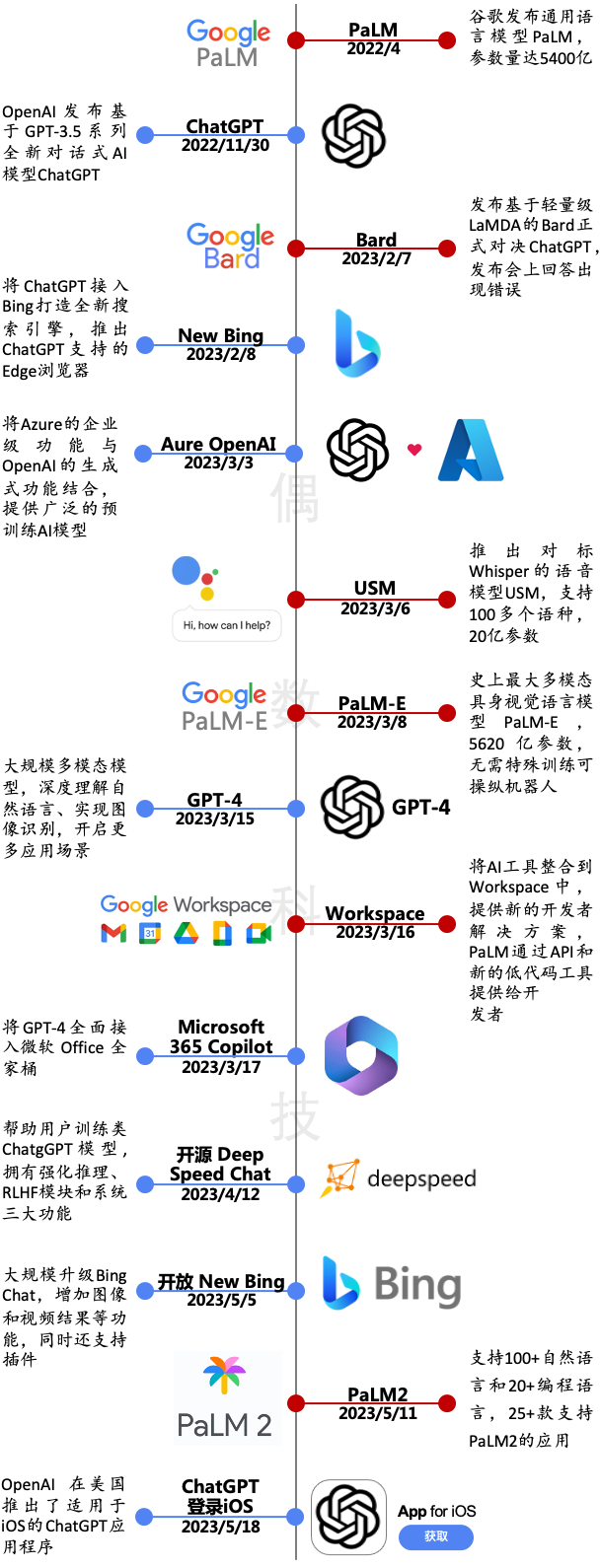
微软vs.谷歌两大阵营发布升级
大语言模型训练数据源
通过大语言模型的训练数据源,我们可以发现这些模型主要还是通过抓取网页数据进行训练,GPT-3 在网页的基础上还加入了部分图书信息。有趣的是 DeepMind 开发的 AlphaCode 训练数据源全部是代码,可推测其在编程方面具备强大的能力。据了解,AlphaCode 在 2022 年参加了 Codeforces 举行的 10 场编程比赛,排名前 54.3%,击败了 46% 的参赛者,Elo 评分 1238。
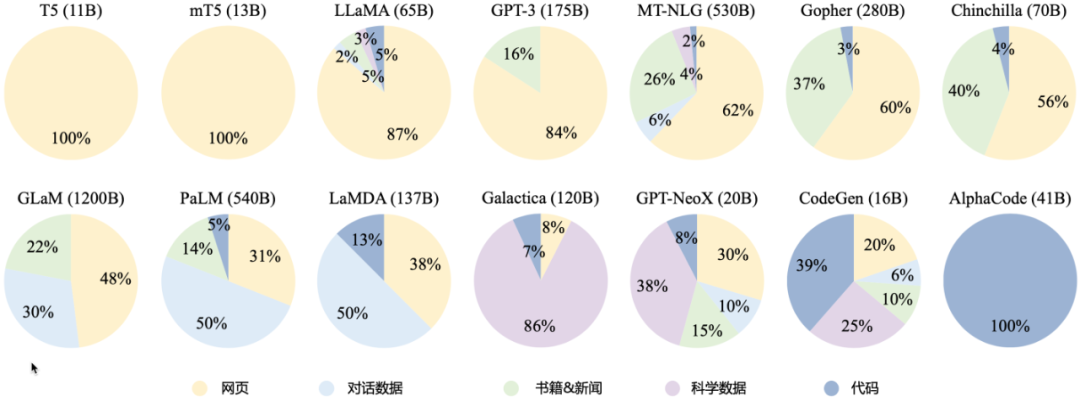
不同大语言模型训练数据源
大语言模型训练硬件资源
大规模语言训练对硬件资源消耗是十分巨大的,除了最早使用 GPU 作为训练芯片,现在不少大语言模型已经开始使用 TPU 作为主要训练芯片。一方面,硬件的高速发展无疑提高了大语言模型的迭代效率;另一方面,大语言模型的激烈竞争也导致了以芯片和服务器为主的硬件价格大涨。根据界面新闻,英伟达 AI 旗舰芯片 H100 售价在多个渠道炒至 4 万美元, 相比此前零售商报价 3.6 万美元明显提价,而 1 万枚英伟达 A100 芯片是开发大语言模型的算力门槛。
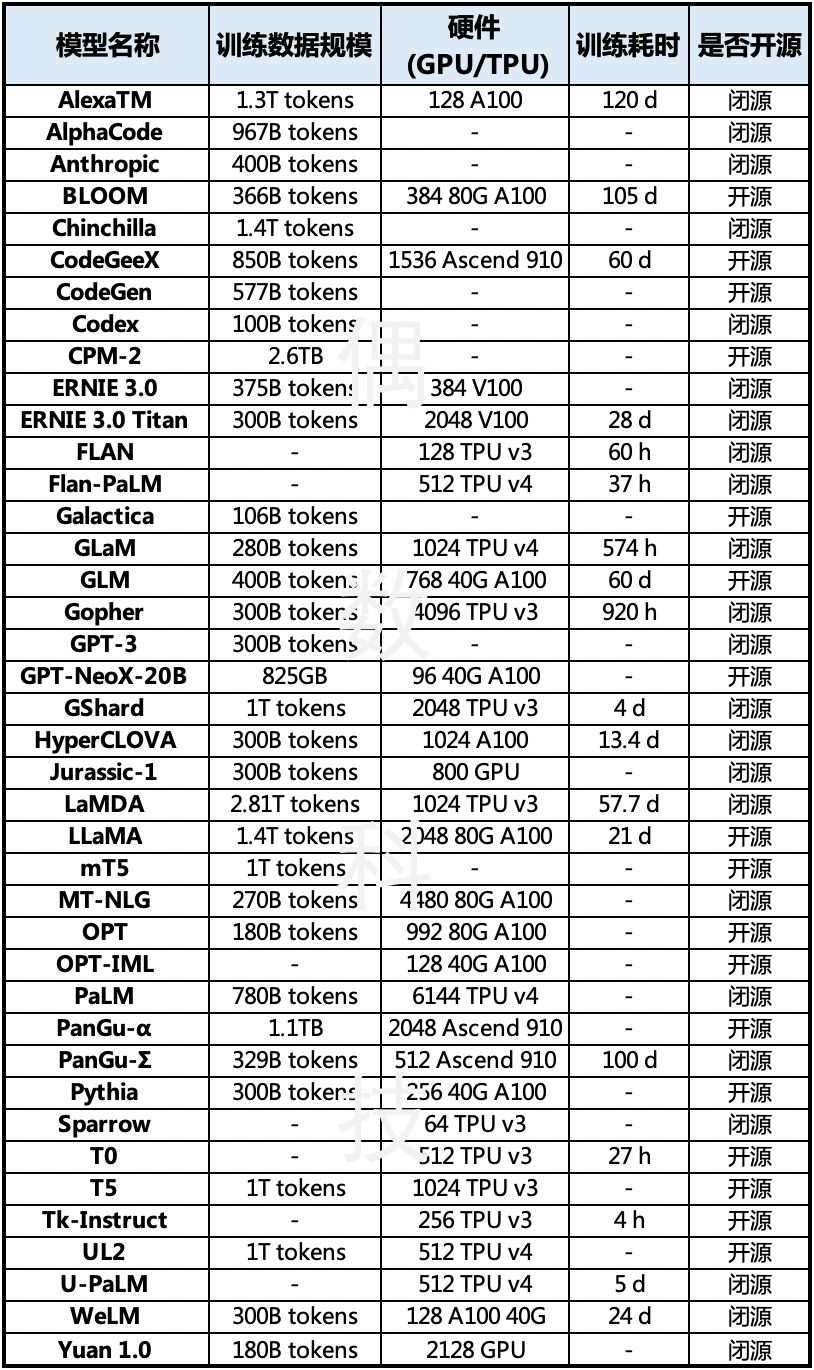
大语言模型训练硬件资源比较
全球主要大语言模型盘点
从全球范围来看,大语言模型的主要发布机构有 Google、OpenAI、Facebook、Microsoft,以及 Deepmind 和 EleutherAI。模型参数规模以百亿级和千亿级为主,技术架构主要为 Encoder-Decoder。下表所列出的模型数量接近 100,实际上应该会更多一些。
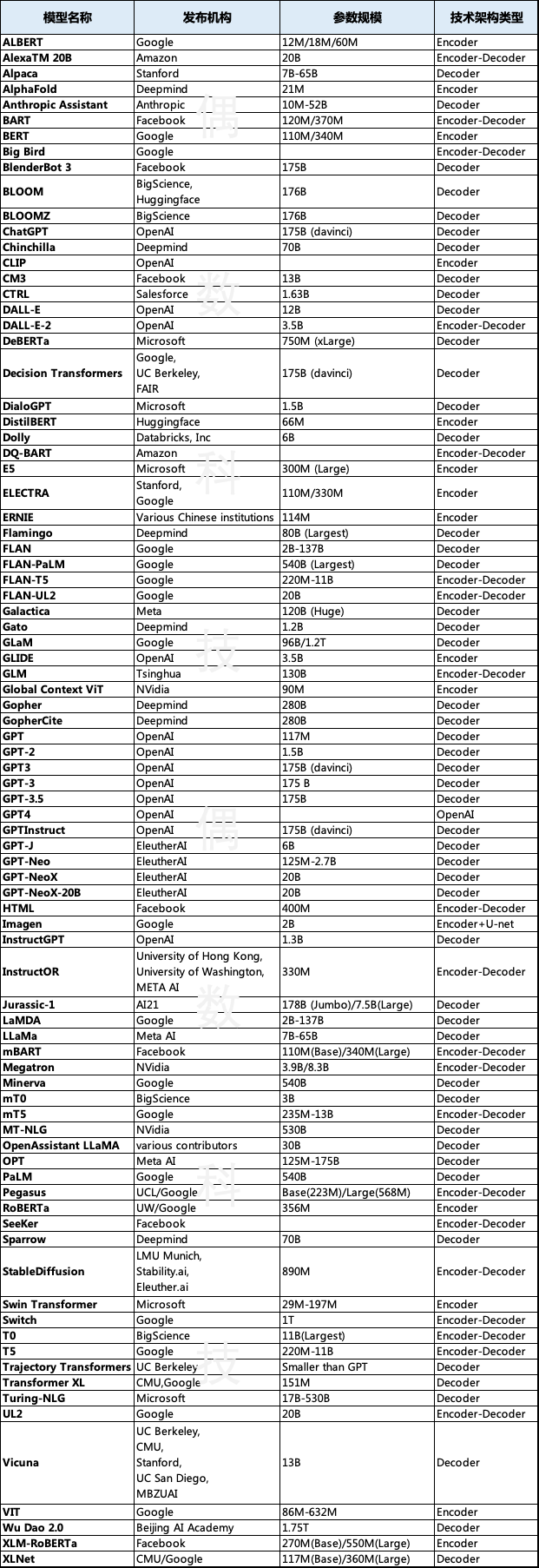
全球主要大语言模型比较
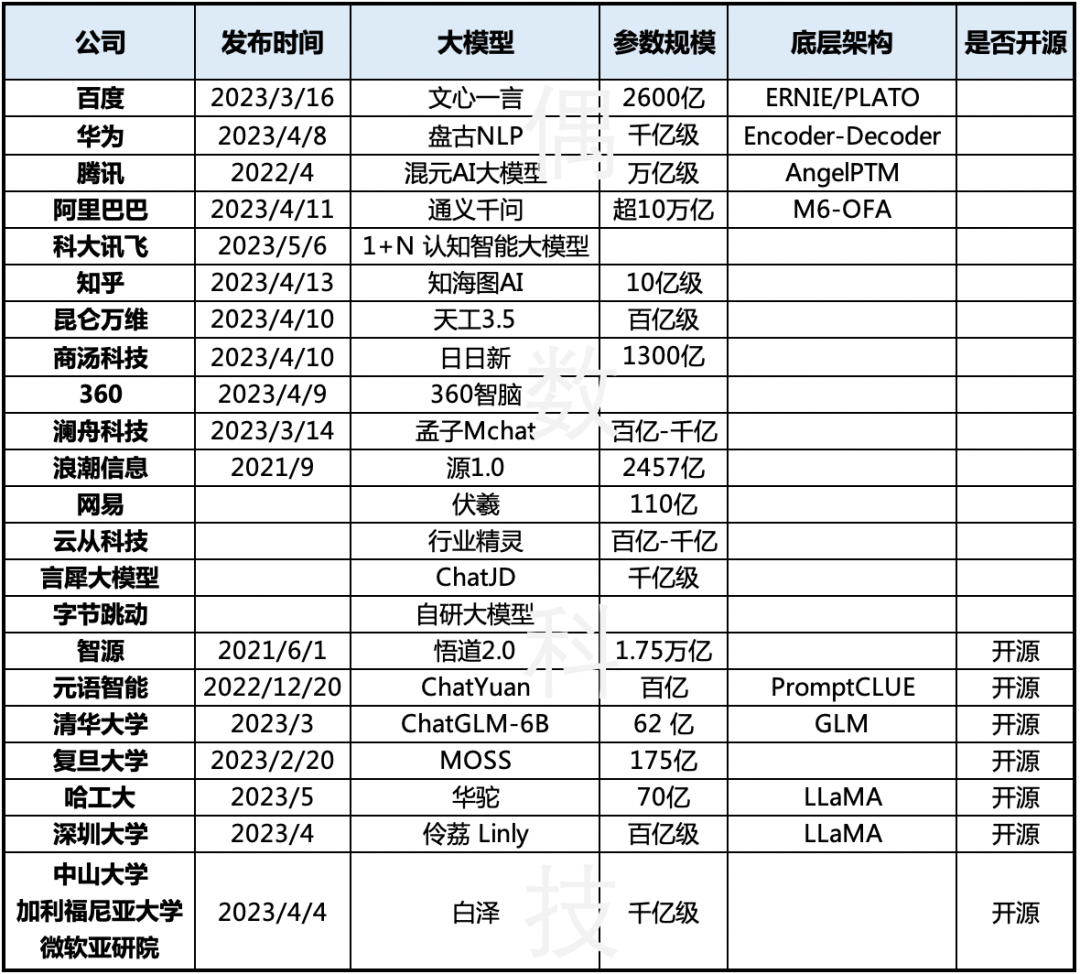
国内大语言模型盘点
当然,大语言模型这把火也点燃了国内科技公司对大语言模型的热情,凭借前期自研或者开源模型的基础,目前国内很多机构都推出了大语言模型,不完全统计已超20家。