一、集合
Collection派生
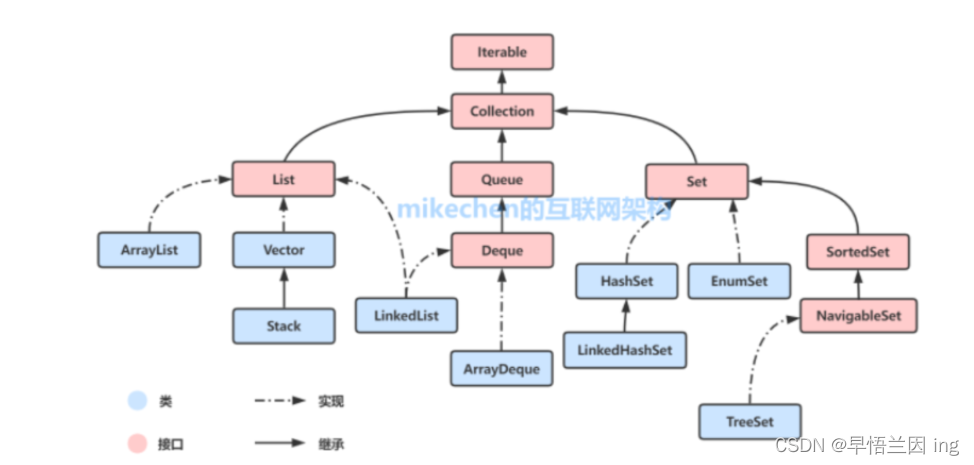
我们在使用集合的时候其实更多的是使用List、Set、Map集合进行操作,List、Set又继承自Collection
Collection下的集合为单列集合,可以理解为一个集合当中的数据只代表一个“对象”。
Map派生
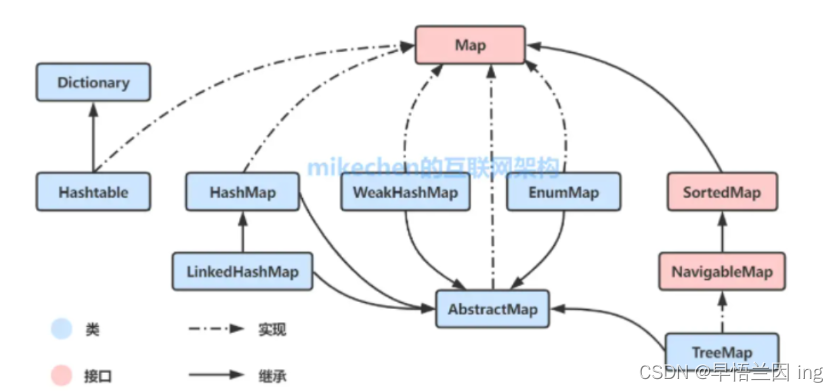
Map代表的是存储key-value对的集合,也就是双列的数据格式;可根据元素的key来访问value。
1.1 List集合
-
有序性:List中的元素按照它们添加的顺序进行排序,并且可以根据索引来访问元素。也就是说,元素在List中有固定的位置。
-
允许重复元素:与Set不同,List允许包含重复的元素。相同的元素可以在List中存在多个副本。
-
可动态修改:List允许添加、删除和修改元素。可以通过调用add()方法在列表末尾添加元素,通过调用remove()方法删除特定元素,还可以使用set()方法修改指定位置的元素。
-
可以包含null元素:List可以包含null元素,并且可以根据null来查找或删除元素。
-
有多个实现类:Java提供了多个List的实现类,最常用的是ArrayList和LinkedList。ArrayList基于动态数组实现,适用于随机访问和快速遍历。LinkedList基于双向链表实现,适用于频繁的插入和删除操作。
-
支持迭代遍历:List可以使用迭代器(Iterator)或增强型for循环进行遍历。迭代器提供了顺序访问集合元素的能力,并允许修改元素。
-
提供一些常用操作方法:List接口提供了一些常用的操作方法,如获取列表大小(size())、判断列表是否为空(isEmpty())、获取元素索引(indexOf()、lastIndexOf())等。
总结来说,List是一种有序、可重复且可动态修改的集合。可以根据索引访问元素,在列表中添加、删除和修改元素。List的不同实现类具有不同的特点和适用场景,开发人员可以根据具体需求选择合适的实现类。
1.1.1 ArrayList
ArrayList实现了List接口,但他的底层数据结构为数组(在内存当中的地址连续,采用随机访问),由于这个原因导致它在查询速度上有很大的优势。
Arraylist的初始长度为10,扩容机制为1.5倍的扩容。
1.1.2 LinkedList
LinkedList底层为链表,在jdk1.7之前为双向循环链表,jdk1.8后为双向链表,由于链表的原因导致其在查找速度上不是很突出,但是却在修改数据上有很好的表现。
总结一下:
1)ArrayList 优点: 底层数据结构是数组,查询快,增删慢。 缺点: 线程不安全,效率高
2)LinkedList 优点: 底层数据结构是链表,查询慢,增删快。 缺点: 线程不安全,效率高
1.2 Set集合
Set集合是Java集合框架中的一种接口,具有以下特点:
-
无序性:Set集合中的元素没有固定的顺序,不保证元素的存储顺序和插入顺序一致。
-
不允许重复元素:Set集合不允许包含重复的元素。如果试图向Set集合中添加重复的元素,操作将会被忽略,即不会添加重复的元素。
-
唯一性:Set集合中的元素是唯一的,每个元素只会出现一次。Set集合通过元素的equals()方法和hashCode()方法来判断元素的唯一性。
-
可以包含null元素:Set集合可以包含一个null元素,但不能包含多个null元素。
-
高效查询:Set集合的实现类(如HashSet和TreeSet)通过使用哈希表或树结构来实现,保证了高效的元素查找操作。
-
不保证迭代顺序:由于Set集合的无序性,迭代Set集合时,元素的顺序是不确定的。如果需要按照一定顺序遍历集合,可以使用SortedSet接口的子接口TreeSet。
-
不支持索引访问:Set集合没有提供类似List的索引访问功能,不能通过索引来访问集合中的元素。
总结来说,Set是一种无序、不可重复的集合。它适用于需要存储一组唯一性的元素,并且不关心元素之间的顺序。在实际应用中,可以根据具体需求选择HashSet、TreeSet或LinkedHashSet等Set的实现类。
set集合在代码上是对map集合的扩展开,因为其底层数据结构是一样的,功能上也有相识的地方,所以set集合在map集合的代码上做了扩展,增加了属于自己的功能。
Hashset--------Hashmap--------哈希表(数组+链表)
LinkedHashset--------LinkedHashmap--------链表+哈希表
Treeset--------Treemap--------二叉树
1.3 Map集合
Map集合是Java集合框架中的一种接口,用于存储键值对(key-value pair)的关联数据。它具有以下特点:
-
键值对存储:Map集合中的数据以键值对的形式存储,每个键都唯一,与之对应的值可以重复。每个键与一个值相关联,通过键可以快速地获取对应的值。
-
键的唯一性:Map集合的键是唯一的,不允许重复的键存在。如果试图使用相同的键添加元素,会覆盖前一个键对应的值。
-
元素的无序性:Map集合中的键值对是无序存储的,不保证添加的顺序和访问的顺序一致。
-
可以包含null键和null值:Map集合允许一个null键和多个null值存在,但是仅能有一个null键。
-
高效查找:Map集合通过键来查找对应的值,具有高效的查找速度。根据具体的实现类,查找的时间复杂度可以是常数时间(如HashMap)或者对数时间(如TreeMap)。
常用的Map的实现类包括HashMap、TreeMap和LinkedHashMap:
- HashMap:基于哈希表实现,提供了较好的性能,在大部分场景下是最常用的Map实现类。
- TreeMap:基于红黑树实现,根据键的自然顺序或者自定义比较器来维护元素的顺序,适用于需要按照键进行排序的场景。
- LinkedHashMap:基于哈希表和双向链表实现,保持元素的插入顺序,可以通过迭代器按照元素插入的顺序遍历集合。
总结来说,Map是一种键值对存储的数据结构,用于存储和操作关联数据。Map集合通过键来查找值,具有高效的查找速度。通过选择合适的实现类和使用Map集合提供的方法,可以方便地进行键值对的添加、删除和查找等操作。
1.3.1 HashMap的扩容机制
数组的总的添加元素数大于了 数组长度 * 0.75(默认,也可自己设定),数组长度扩容为两倍。(如开始创建HashMap集合后,数组长度为16,临界值为16 * 0.75 = 12,当加入元素后元素个数超过12,数组长度扩容为32,临界值变为24)
当其数组长度达到64,链表长度为8的时候;HashMap的数据结果就会从hash表的格式转化为红黑树。
1.3.2 HashMap和HashTable的区别
- HashMap是非线程安全的,Hashtable是线程安全的。
- 扩容机制不同:当已用容量>总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 +1。
- HashMap允许null作为键或值,Hashtable不允许,运行时会报NullPointerException。
- HsahMap在数组+链表的结构中引入了红黑树,Hashtable没有。
我们如何在保证线程安全的前提下使用HashMap呢?两种方法
-
使用集合工具类Collections,调用里面的synchronized相关方法如: Collections.synchronizedList(list)
Collections.synchronizedMap(m)
Collections.synchronizedSet(s)
这个方法可以为所有集合加锁,当然里面不知这个API,它包含了很多集合相关的API可以解决很多与集合相关的问题比如集合的排序等,感兴趣的小伙伴可以去研究下。 -
ConcurrentHashMap 是线程安全的 HashMap 的实现,默认构造同样有 initialCapacity 和 loadFactor 属性,不过还多了一个 concurrencyLevel 属性,三属性默认值分别为 16、0.75 及 16。其内部使用锁分段技术,维持这锁Segment 的数组,在 Segment 数组中又存放着 Entity[]数组,内部 hash 算法将数据较均匀分布在不同锁中。
put 操作:并没有在此方法上加上 synchronized,首先对 key.hashcode 进行 hash 操作,得到 key 的 hash 值。hash操作的算法和 map也不同,根据此 hash 值计算并获取其对应的数组中的 Segment对象(继承自ReentrantLock),接着调用此 Segment 对象的 put 方法来完成当前操作。
ConcurrentHashMap 基于 concurrencyLevel 划分出了多个 Segment 来对 key-value 进行存储,从而避免每次 put 操作都得锁住整个数组。在默认的情况下,最佳情况下可允许 16 个线程并发无阻塞的操作集合对象,尽可能地减少并发时的阻塞现象。
二、多线程
2.1多线程的四种实现方式
一个继承,两个实现,还有一个线程池。
第一种方式:
编写一个类,直接 继承 java.lang.Thread,重写 run方法。
伪代码:
// 定义线程类
public class MyThread extends Thread{
public void run(){
}
}
// 创建线程对象
MyThread t = new MyThread();
// 启动线程。
t.start();
第二种方式:
编写一个类,实现 java.lang.Runnable 接口,实现run方法。
伪代码:
// 定义一个可运行的类
public class MyRunnable implements Runnable {
public void run(){
}
}
// 创建线程对象
Thread t = new Thread(new MyRunnable());
// 启动线程
t.start();
第三种方式:
实现Callable接口,实现run方法,与第二种方法类似。
第四种方式:
线程池,也是我们用的最多,做好用的方式。
线程池创建线程大致可以分为下面三种:
//创建固定大小的线程池
ExecutorService fPool = Executors.newFixedThreadPool(3);
//创建缓存大小的线程池
ExecutorService cPool = Executors.newCachedThreadPool();
//创建单一的线程池
ExecutorService sPool = Executors.newSingleThreadExecutor();
要注意我们不能通过Executors直接创建线程池,那会出现错误。
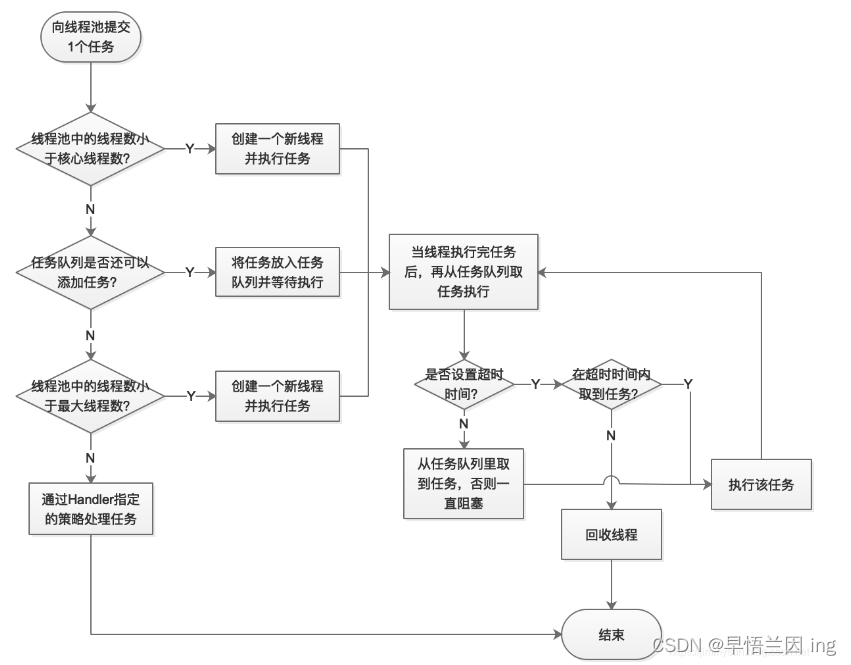
2.1.1 线程池的参数
- corePoolSize(必需):核心线程数。默认情况下,核心线程会一直存活,但是当将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。
- maximumPoolSize(必需):线程池所能容纳的最大线程数。当活跃线程数达到该数值后,后续的新任务将会阻塞。
- keepAliveTime(必需):线程闲置超时时长。如果超过该时长,非核心线程就会被回收。如果将 allowCoreThreadTimeout 设置为 true 时,核心线程也会超时回收。
- unit(必需):指定 keepAliveTime 参数的时间单位。常用的有:TimeUnit.MILLISECONDS(毫秒)、TimeUnit.SECONDS(秒)、TimeUnit.MINUTES(分)。
- workQueue(必需):任务队列。通过线程池的 execute() 方法提交的 Runnable 对象将存储在该参数中。其采用阻塞队列实现。
- threadFactory(可选):线程工厂。用于指定为线程池创建新线程的方式。
- handler(可选):拒绝策略。当达到最大线程数时需要执行的饱和策略。
其工作原理如下:
2.2 线程的状态(生命周期)
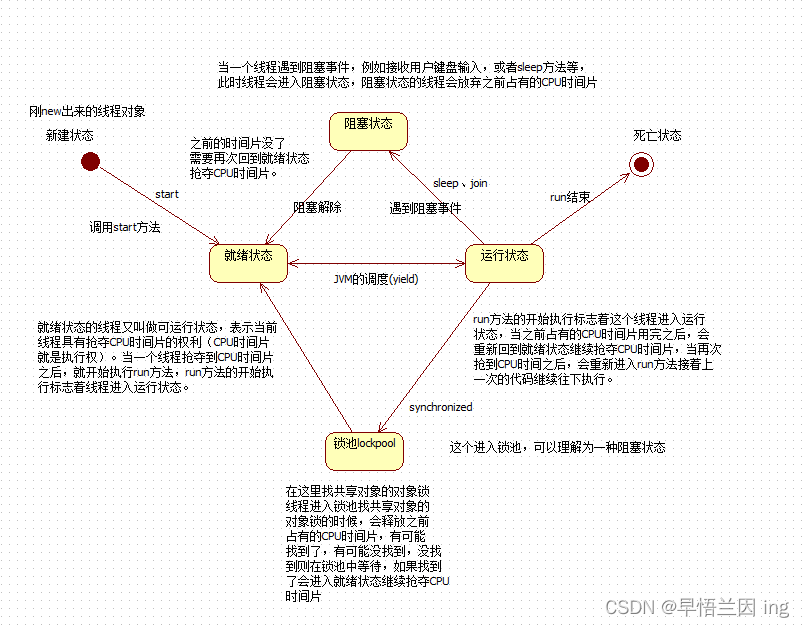
这里会有一些歧义,有人说线程的状态有5种也有人说6种,5种分别为:新建、就绪、运行、阻塞、死亡;而6种分别为:就绪、运行、阻塞、等待、超时等待、死亡;其实际上划分的原理是一样的,所有大家不用过多纠结。
要注意的是wait()阻塞状态和sleep()阻塞状态的区别,sleep在睡眠时间内不释放锁资源,时间到后继续执行,wait()需要Object类中的notify方法唤醒,唤醒之后还需重新抢占锁资源。