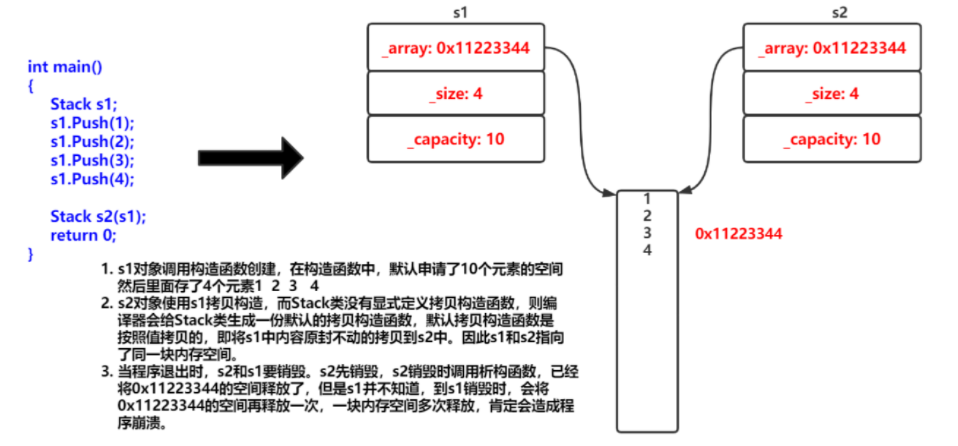
导言
异步是一种设计思想,不是设计目的,因此不要为了异步而异步,要有所为,有所不为。 异步不是『银弹』, 避免试图套用一个『异步框架』解决所有问题, 需要根据不同的业务特点或要求,选择合适的设计实现方式
同步和异步问题是大型分布式系统中需要慎重等待的问题,然而笔者发现公司和部门内相关问题系统性讨论较少, 因此笔者试图通过本文展开交流讨论。
异步定义
在软件设计领域, 异步和同步是一对孪生的设计思想
同步是一种阻塞式且有严格执行时序的设计思想, 必须一件一件事做, 等前一件做完了才能做下一件事。
异步则是一种非阻塞的设计思想, 可以同时做多件事,没有严格的执行顺序。
同步调用方(客户端)在请求发起后会一直阻塞并等待被调用方(服务端)返回响应结果,且仅当调用方获取响应结果后才会继续或终止执行。 例如近期较为常见的『核酸采样亭』虽然采样亭内有多人协作,但是为了保证采样人管一致, 核酸采样队伍就是顺序行进的, 前一个没有录入完,也不会继续下一位。
异步调用方(发布方)无需等待被调用方(订阅方)执行完所有逻辑,就可继续执行后续事情。例如一些餐馆的『排队』场景,往往点餐区仅需要完成『点餐收银』动作, 之后订单会转到后厨进行制作, 此时点餐人无需继续在点餐去等待, 可以去找位置坐下等取餐提醒, 或者心急的话在取餐区排队等待。
| 同步 | 异步 | |
| 特征 | 1)阻塞:调用发起方在请求提交后不会向系统交出控制权,而是持续等待被调用方返回响应结果。 | 1)非阻塞:任务提交后将控制权交予系统,系统可以进行其他任务的执行 |
| 优点 | 1. 严格保证时序: 同步流程是最天然的控制过程顺序执行的方式, 因此对结果的处理始终和前文保持在一个上下文内。 | 1. 逻辑解耦:可在模块、服务、接口等不同粒度上实现解耦, 便于进行功能降级,提升系统稳定性 |
| 缺点 | 1. 耦合度高: 调用方强依赖被调用方的状态 | 1. 数据一致性影响:由于调用发起方和被调用方通过异步进行了解耦, 数据一致性难以保证, 需要提供额外机制进行补偿。 |
设计要点
在异步设计过程中需要重点关注的指标: 数据一致性
- 数据防丢失
- 幂等
数据一致性需求
什么是数据一致性
- 强一致性:也称为原子一致性,线性一致性。即任意时刻,所有节点中的数据应该是一样的。任何节点的读操作都能读取到某个数据的最近一次写的数据。关系数据库 的本地事务( ACID )来保证数据的强一致性。
- 弱一致性:有很多种不同的实现方式。目前分布式系统中广泛实现的是最终一致性。最终一致性是弱一致性的一种特例,保证用户最终能够读取到某个数据的更新。BASE 来做数据的最终一致。 BASE: basically-available, soft-state, eventual consistency.
为什么会有一致性的需求
- 不同的业务场景涉及到操作同一条数据,处理不当时,可能导致多次操作后数据丢失,不一致
- 为了提高系统的吞吐量,对于数据实时性要求不高的场景,一般会考虑读写分离,从而衍生主从数据库一致性问题;
- 为了提高系统的处理速度,当前都会使用各种缓存机制(localCache、redis 等等),从而衍生出数据库与各种缓存一致性问题;
- 为了应用解耦、流量削峰,实现系统的高可用、可扩展等,当前都会使用各种消息队列,异步消息的处理也会衍生出数据一致性问题;
如何解决一致性问题
- 强一致场景:
- 数据库事务
- 锁(悲观锁、乐观锁)
- 分布式事务(正向 SAGA 保证最终一致、反向 SAGA 进行事务补偿)
- 最终一致场景:
- 幂等设计
- 分布式对账
数据防丢失
为什么会出现数据丢失?
- 分布式消息队列生产和消费:
- Case 1: 消息发送环节,在消息生产方 Publisher 在业务逻辑处理完成后, 在步骤 1 没能正确发送到 MQ 导致消息丢失
- Case 2: 消息接受处理环节, Subscriber 在消费逻辑没有正确处理前就像 MQ Server 发送 ACK, 导致消息丢失
- 服务异常退出:
- 主进程发送异步消息时没有记录当时的任务场景, 如主进程异常退出,会导致任务状态无法及时感知。
如何防止数据丢失?
- 针对分布式消息队列生产和消费:
- Case 1: 消息发送环节, 为了避免消息丢失
- 延迟发送:将消息现在内存中缓存起来, 然后通过延迟队列进行发送(并增加重试机制)
- Case 2: 消息消费环节
- 在消息被正确响应后才对消息 ACK
- 增加死信队列, 对处理异常的消息推送至死信队列, 然后对该队列消息进行单独处理。
- Case 1: 消息发送环节, 为了避免消息丢失
- 针对服务异常退出:
- 在异步处理前,将现场必要的信息(例如异步任务对应的租户、任务 ID 等信息)进行持久化(通过 redis 或 mysql)进行存储。 并通过事务在发送迁进行持久化, 如果消息发送失败, 可通过持久化状态进行重试。
幂等
什么是幂等 ( idempotent )?
幂等性: 在计算机领域, 对于一个操作, 在输入相同时,如果它确保对我们关注的影响,在多次执行时和一次执行时相同, 那么这个操作对于我们来说就是幂等的。
在分布式环境下之所有强调幂等性是由于对通信链路的不信任,我们的请求可能由于网络问题或依赖服务的稳定性而出错进而需要做重试,而如果我们对应的接口没有做请求去重或进行幂等设计就可以导致重复处理引发数据错误。
什么场景需要考虑幂等问题
- 网络波动: 因网络波动,由于网关没有及时获得响应,可能出现重复请求的问题
- 分布式消息消费:
- Case 1: 消息发送环节,如果 Publisher 没有收到来自 MQ Server 的 ACK 消息, 会根据重试设置进行重复生产消息
- Case 2: 消息接受处理环节,如果 MQ Server 没有收到来自 Subscriber 的消息消费的 ACK 消息, 可能会重复投递消息
- 用户重复操作: 用户在使用产品时,可能会误操作而触发多笔交易,或者因为长时间没有响应,而有意触发多笔交易。
- 未关闭的重试机制: 技术人员人为的错误,因开发人员、测试人员或运维人员没有检查出来,而开启的重试机制(如 Nginx 重试、RPC 通信重试或业务层重试等)
如何解决幂等问题
- 识别产生幂等的场景唯一 key
- 通过接入侧去重或数据库兜底拦截的方式根据业务唯一 key 进行判断
| 适用场景 | 实现要点 | 实现方式 | |
| token 机制 (业务唯一标志)分布式锁 | 接口重放(攻击)用户主动的重复创建 | Token 用于控制过滤重复动作,是指在动作流转过程中控制有效请求数量。 为每个请求分配一个具有业务含义的唯一 ID,例如组织架构调整过程中的 draftID 或是商品订单提交场景的 订单 ID |
|
| 唯一索引,防止新增脏数据 | 适用于创建场景,利用数据库唯一键约束 | 该方式主要利用数据库本身的唯一键约束 | 根据业务场景设计唯一键
|
| 悲观锁 | 适用于更新场景 |
| 当数据库执行 select for update 时会获取被 select 中的数据行的行锁,因此其他并发执行的 select for update 如果试图选中同一行则会发生排斥(需要等待行锁被释放),因此达到锁的效果。 |
| 乐观锁 | 适用于更新场景 | 简单理解就是在数据更新时需要去比较持有数据的版本号,版本号不满足条件的操作无法成功 |
|
| 状态机 | 本质也是乐观锁的一种,适用于业务有多种状态,且状态间流转是有向图的场景 | 主要思路就是通过状态标识的变更,保证业务中每个流程只会在对应的状态下执行,如果标识已经进入下一个状态,这时候来了上一个状态的操作就不允许变更状态,保证了业务的幂等性 | 状态机是一种强业务相关的设计, 需要根据具体场景处理 |
从 ROI 方面考虑, 乐观锁 > 唯一键约束 > 悲观锁
异步方案
Notification 方式
Notifications - a sender sends a message a recipient but does not expect a reply. Nor is one sent.
设计要点:
- 在代码中开启协程进行异步通知, 无需关心协程的执行成功与否
- 此类方法适仅适用于可以随时降级的非核心功能, 功能的执行成功与否不影响主进程的逻辑
流程:
- 在函数进程中开启 子协程 Notification
- 主进程继续执行, 不关心协程 Notification 的执行状态以及结果
优点:
- 提升主进程执行性能
- 可以实现故障隔离, 将非核心功能与核心功能剥离, 可做到服务降级
缺点:
- Notification 协程的状态不可知
应用场景:
- Metrics 打点
- 日志打印
// example: metrics 埋点
func CallExampleRpc(ctx context.Context, req *example.ExampleRequest) (*example.ExampleResponse, error) {
const method = "CallExampleRpc"
callRes := RPCCallResultSuccess
defer func() {
// 将 RPC Call 的执行结果上报 metrics
go MetricsEmitRPCCallerResult(cli.psm, cli.psm, callRes, method )
}()
// some logic here
... ...
}接口响应式设计
获取被调用方响应常见有两种方式:
- 轮询(pull):任务的发起方通过轮询的方式调用事件接收方执行状态或请求任务状态的共享存储(redis 或 mysql)
- 回调 (push):发起方提供 callback 接口方法, 由异步事件接收方在消费后调用
轮询模式
设计要点:
- 相比于 4.1 Notification 的方式, 在接口相应式设计中,异步发起方需要获取被调用方的响应
- 相比与同步, 主要的提升是将部分逻辑拆分到另一个异步流程中进行
- 该模式适用于异步流程中的逻辑可以拆分成多个可并行独立执行的子流程, 从而提升执行效率
流程:
- 事件发起方触发异步任务,然后进入轮询等待状态
- 事件接受方在 Goroutine 中执行任务逻辑,并更新任务状态到 redis 中
- 事件发起方轮询 check redis 中的任务状态,查看任务执行成功或失败
优点:
- 实现简单,任务比较轻量级
- 通过 redis 可以监控任务状态,判断任务状态和运行异常
缺点:
- 如果程序退出,任务会存在丢失的情况,并且无法重试恢复
- 对于任务本身并没有持久化的记录,例如入参出参,出现数据不一致的情况无法对账对数据进行修复
场景分析: 适用于本身异步任务并不产生数据,对任务是否失败不是很敏感的场景,例如 用户进入画布时的冲突校验。这个场景下,冲突校验本身并不生产新的数据,不会由于任务丢失或失败产生脏数据影响用户的使用。另外这个校验场景本身对任务的成功或失败并不敏感,如果任务失败了,不需要自动重试校验,用户点击刷新页面,重新访问接口即可重新触发另一次的校验
// 通过基于 promise 模式实现的 goroutine 协程
f := future.WhenAll(
func() (interface{}, error) {
return CheckDepartmentModifyProcess(realCtx, modifyDepChangeList, params)
},
// 用于示例, 截取部分片段
...
func() (interface{}, error) {
return CheckDepartmentDeactiveProcess(realCtx, deactiveDepChangeList, modifyParentOrCreateChangeList, params)
},
)
// 等待异步流程执行完成,然后处理执行结果
if maxExecuteTime != nil {
res, err, timeout = f.GetOrTimeout( * maxExecuteTime)
} else {
res, err = f.Get()
}回调模式
设计要点:
- 相比于 4.1 Notification 的方式, 在接口相应式设计中,异步发起方需要获取被调用方的响应
- 相比与同步, 主要的提升是将部分逻辑拆分到另一个异步流程中进行
- 该模式适用于异步流程中的逻辑可以拆分成多个可并行执行的子流程, 从而提升执行效
流程:
- 事件发起方触发异步任务,然后继续执行后续其他逻辑
- 事件接受方在 Goroutine 中执行任务逻辑,当执行结束后,会通过事件发起方提供的 callback 方法传递执行结果
- 事件发起方在 callback 方法中接收事件接收方的结果, 并执行后续的回调逻辑
优点:
- 事件发起方在触发事件后无需等待,资源利用率会得到提升
缺点:
- 如果程序退出,任务会存在丢失的情况,并且无法重试恢复
- 对于任务本身并没有持久化的记录,例如入参出参,出现数据不一致的情况无法对账对数据进行修复
- 回调嵌套的难度。通常被用作回调的函数,经常最终需要自己的回调。这导致了一系列回调嵌套并导致出现难以理解的代码。该模式通常被称为标题圣诞树(大括号代表树的分支)。
- 错误处理很复杂。嵌套模型使错误处理和传播变得更加复杂。
// 回调示例
func asyncHandler(ctx context.Context, param *AsyncParam) (error) {
// do something
defer handleAsyncErrorCallback(error)
}
func handleAsyncErrorCallback(error) {
// do something
}
func doSomething(ctx context.Context, param *Param)() {
// do something
go asyncHandler(param)
// do something else
}发布订阅式设计
设计要点:
通过 Rocketmq 发送 task 到队列,开启 consumer 消费任务,并使用 redis / DB 对任务进行状态的监控
流程:
1. 用户触发流程操作,提交 task 任务到 rocketmq 的 producer 中
2. Rocketmq 的 consumer 接收到 msg,并在 handler 中执行回调逻辑,并更新 redis/DB 状态
3. 用户 check redis/DB 中的状态,确定任务执行成功还是失败。同时也可以通过 check rocketmq 的消费 ack 情况判断任务是否真的执行完成
优点:
- 实现相对简单,任务执行比较轻量
- 任务执行和任务发起的机器可以不是同一台,对于复杂逻辑可以在一定程度上进行负载均衡
- Rocketmq 本身自带消息的 ack 功能,如果 task 消费失败,可以自动重试 (也可以通过参数设置不重试)
- Rocketmq 对消息会进行存储,可以通过 msg 存储的 task 进行对账,在必要时候修复不一致的数据
缺点:
- Rocketmq ACK 本身有时长限制 (Rocketmq 默认是 600s, 不过可以调),如果任务本身比较复杂,执行时间超长后,rocketmq 自动任务任务失败
- Rocketmq 消息在特殊情况下也有可能存在重复投递的情况,在一些情况下同一个 task 可能会被多次执行,如果任务本身不支持幂等则可能导致数据不一致的出现
场景分析:
由于 rocketmq 自动重试的特性,这种类型更适合,task 逻辑相对简单,且本身并不生产新的数据,但是任务本身是否成功比较敏感,在任务执行失败后,可以进行自动重试,确保服务的稳定
基于任务管理(托管)
设计要点:
本方案会引入三方分布式任务管理框架 通过 Scheduler Job 去触发任务,使用 Scheduler 本身的能力记录 task,通过 redis 记录 task 运行中间过程
流程:
- 用户提交 task,首先在 redis/DB 中创建一条 task record 用于记录任务执行状态
- 调用 Scheduler Job,通过 Processor 执行任务逻辑
- 在 Process 执行任务同时,在 redis / DB 中更新任务状态,如果出现 error 信息,也更新到 redis 中
- 通过 Check redis/DB 中的任务状态判断执行是否成功,通过 Scheduler 平台的任务记录完成任务的对账
优点:
- 借助 Scheduler 平台能力,可以对 task 记录进行持久化记录,方便后续 check 任务状态以及数据对账
- Scheduler 支持分片能力,相比 rocketmq 在投递时候通过 queue 进行 balance,scheduler 在更高并发的场景下,可以让任务分拆到不同的机器上执行,提高并发能力
- Scheduler 支持分布式调度,可以将多个并发 task 的执行结果聚合,并统一处理返回
缺点:
- 接入整体比较重型,接入成本较高,本身 Scheduler 只是一个分布式任务调度平台,业务需要自己设计实现来适配自己的业务场景
- 任务的失败重试需要业务自己进行监控,判断是否重试,scheduler task 本身也不配有断点重试功能,重试情况下仍需要业务自己保证代码逻辑幂等
场景分析:
由于 Scheduler 本身很重,因此本身更适合去执行逻辑复杂的 task,Scheduler 通过长链接监控任务执行状态,确保不会因为超时导致任务状态异常
另外由于 Scheduler 的 task 信息持久化的能力,如果任务本身会生产处理新的数据,这样的任务也更适合使用 Scheduler 进行任务管理,方便后续确保数据一致性问题时,进行对账
分享小结
本文从异步定义开始,通过对异步设计要点(数据一致性)的分析,推出异步设计的几种常见方案。
在异步设计过程中需要重点关注的指标: 数据一致性
- 数据防丢失
- 幂等
异步设计常见解决方案:(根据数据一致性要求从低到高排序)
- Notification 消息通知模式
- 接口响应式设计
- 发布订阅式设计
- 基于任务管理(托管)