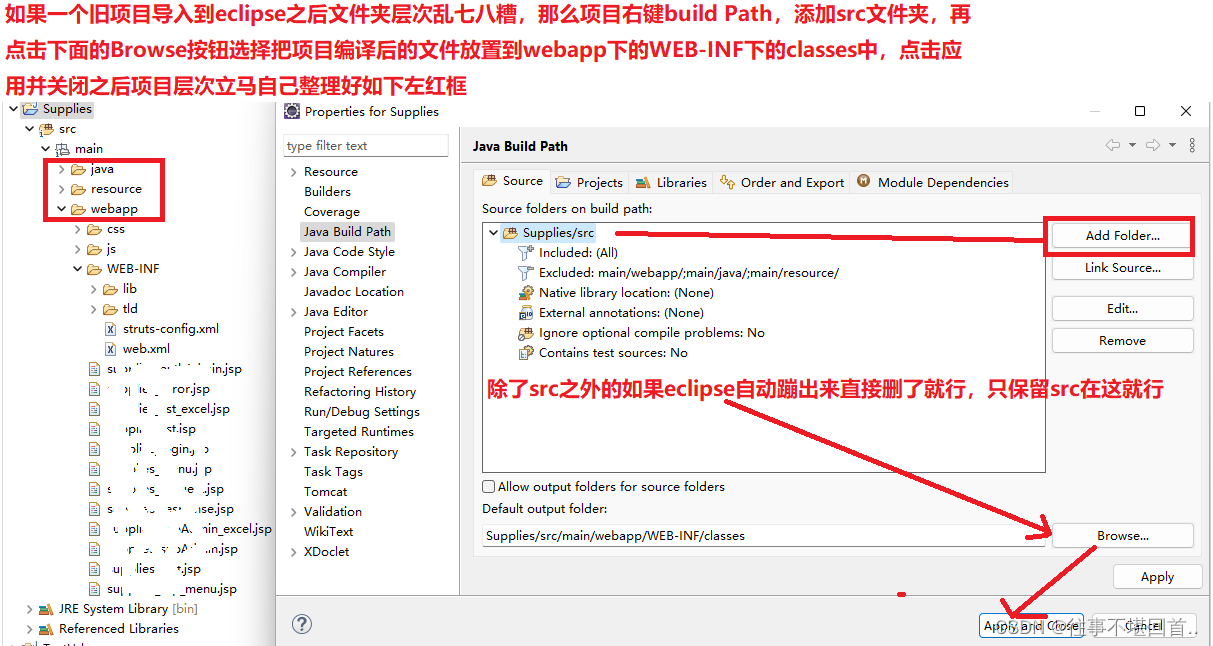
YOLOv8半自动标注
目标检测半自动标注的优点包括:
1.提高标注效率:算法能够自动标注部分数据,减少了人工标注的工作量,节省时间和资源。
2.降低成本:自动标注可以减少人工标注的成本,特别是对于大规模数据集来说,人工标注成本非常昂贵。
3.提高标注的一致性和准确性:计算机算法可以提供相对准确的初始标注,人工验证和修正后,可以确保标注的一致性和准确性。
4.改善数据集的质量:通过自动标注和人工验证,可以更全面地标注数据集,提高数据集的质量和丰富性。
具体而言:
1.根据现有数据集,训练一个YOLOv8 模型;
2.使用 YOLOv8 模型对图片进行目标检测,得到目标检测的结果;
3.将目标检测的结果转换为 XML 文件格式,保存预测好的 XML 文件。
新建一个名为generateXml.py文件
import os
import cv2
import datetime
class GenerateJpgAndXml:
"""
参数名含义:
parentName:存放jpg和xml上一级文件夹名字,如person
"""
def __init__(self, parentName, labelDict):
self.parentName = parentName
# 存放所有文件的主文件夹路径
self.parentPath = "./JpgAndXml"
self.midPath = os.path.join(self.parentPath, self.parentName)
# 存放jpg文件夹名字
self.jpgName = "images"
# 存放xml文件夹名字
self.xmlName = "Annotations"
# 存放标签的字典
self.labelDict = labelDict
# 第一次进来,需要判断下文件夹是否存在
self.isExist()
def isExist(self):
# 存放jpg文件的文件夹
self.jpgPath = os.path.join(self.midPath, self.jpgName)
# 存放xml文件的文件夹
self.xmlPath = os.path.join(self.midPath, self.xmlName)
# 判断jpg和xml文件夹是否存在,不存在则创建
for perPath in [self.jpgPath, self.xmlPath]:
# 判断所在目录下是否有该文件名的文件夹
if not os.path.exists(perPath):
# 创建多级目录用mkdirs
# print(f"创建成功,已创建文件夹{perPath}")
os.makedirs(perPath)
# else:
# print(f"创建失败,已存在文件夹{perPath}"
def generatr_xml(self, frame, result):
# print('开始写xml')
# 获取当前时间戳
xmlPrefix = datetime.datetime.now().strftime("%Y%m%d%H%M%S%f")
# print(xmlPrefix)
hwc = frame.shape
# jpg名字
jpgName = xmlPrefix + ".jpg"
# jpg路径
jpgPath = os.path.join(self.jpgPath, jpgName)
# 写图片
cv2.imwrite(jpgPath, frame)
# xml路径
xmlPath = os.path.join(self.xmlPath, xmlPrefix + ".xml")
with open(xmlPath, 'w') as xml_file:
xml_file.write('<annotation>\n')
xml_file.write('\t<folder>' + self.parentName +'</folder>\n')
xml_file.write('\t<filename>' + jpgName + '</filename>\n')
xml_file.write('\t<path>' + jpgPath + '</path>\n')
xml_file.write('\t<source>\n')
xml_file.write('\t\t<database>' + 'Unknown' + '</database>\n')
xml_file.write('\t</source>\n')
xml_file.write('\t<size>\n')
xml_file.write('\t\t<width>' + str(hwc[1]) + '</width>\n')
xml_file.write('\t\t<height>' + str(hwc[0]) + '</height>\n')
xml_file.write('\t\t<depth>'+str(hwc[2])+'</depth>\n')
xml_file.write('\t</size>\n')
xml_file.write('\t<segmented>0</segmented>\n')
for re in result:
ObjName = self.labelDict[re[0]]
# [[0, 0.8, 110, 25, 150, 60], [1, 0.5, 40, 10, 50, 90]]
xmin = int(re[2])
ymin = int(re[3])
xmax = int(re[4])
ymax = int(re[5])
xml_file.write('\t<object>\n')
xml_file.write('\t\t<name>' + ObjName + '</name>\n')
xml_file.write('\t\t<pose>Unspecified</pose>\n')
xml_file.write('\t\t<truncated>0</truncated>\n')
xml_file.write('\t\t<difficult>0</difficult>\n')
xml_file.write('\t\t<bndbox>\n')
xml_file.write('\t\t\t<xmin>' + str(xmin) + '</xmin>\n')
xml_file.write('\t\t\t<ymin>' + str(ymin) + '</ymin>\n')
xml_file.write('\t\t\t<xmax>' + str(xmax) + '</xmax>\n')
xml_file.write('\t\t\t<ymax>' + str(ymax) + '</ymax>\n')
# xml_file.write('\t\t\t<angle>' + str(4) + '</angle>\n')
xml_file.write('\t\t</bndbox>\n')
# xml_file.write('\t\t<extra/>\n')
xml_file.write('\t</object>\n')
xml_file.write('</annotation>')
# customPrint(f"{jpgPath}的jpg和xml已写入")
新建名为yolov8_infer.py的文件,修改模型、标签名以及图片文件夹即可
from ultralytics import YOLO
from generateXml import GenerateJpgAndXml
import numpy as np
import os
import cv2
# 加载yolov8模型
model = YOLO('runs/detect/train23/weights/best.pt',)
# 修改为自己的标签名
label_dict = {0: 'gray', 1: 'line', 2: 'black', 3: 'big_black'}
parent_name = label_dict[0]
yolov8_xml = GenerateJpgAndXml(parent_name, label_dict)
# 指定图片所在文件夹的路径
image_folder_path = 'data/images'
# 获取文件夹中所有的文件名
file_names = os.listdir(image_folder_path)
# 遍历每个文件
for file_name in file_names:
# 判断是否是图片文件
if file_name.endswith(('.jpg', '.jpeg', '.png', '.bmp', '.gif')):
# 图片的完整路径
image_path = os.path.join(image_folder_path, file_name)
# 使用OpenCV读取图片
img = cv2.imread(image_path)
# Perform object detection on an image using the model
results = model.predict(source=img,
conf=0.1,
max_det=300,
iou=0.4,
half=True,
imgsz=640
)
# print(results)
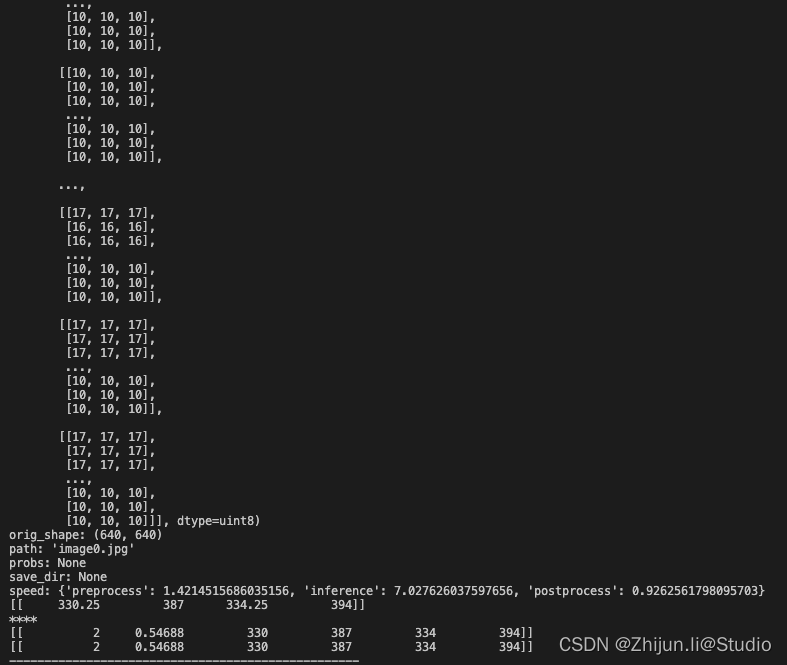
for result in results:
xyxy = result.to("cpu").numpy().boxes.xyxy
print(result)
# 假设 xyxy, conf 和 cls 分别是三个 NumPy 数组
conf = result.to("cpu").numpy().boxes.conf
cls = result.to("cpu").numpy().boxes.cls
conf_expanded = np.expand_dims(conf, axis=1) # 在轴 1 上扩充
cls_expanded = np.expand_dims(cls, axis=1) # 在轴 1 上扩充
xyxy = xyxy.astype(np.int32)
# 使用 numpy.concatenate() 在轴 1 上拼接数组
concatenated_array = np.concatenate((cls_expanded, conf_expanded, xyxy), axis=1)
print(concatenated_array)
yolov8_xml.generatr_xml(img, concatenated_array)
print(concatenated_array)
print('-'*50)
运行过程截图




![el-table点击表格某一行添加到URL参数,访问带参URL加载表格内容并滚动到选中行位置 [Vue3] [Element-plus 2.3]](https://img-blog.csdnimg.cn/98e5ad2a0182413294979e6591abeb03.png)