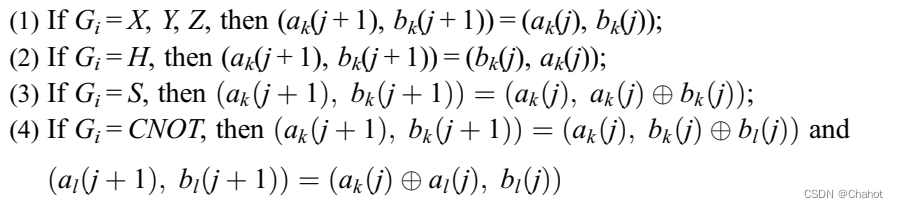前言
ChatGPT是一种基于语言模型的聊天机器人,它使用了GPT(Generative Pre-trained Transformer)的深度学习架构来生成与用户的对话。GPT是一种使用Transformer编码器和解码器的预训练模型,它已被广泛用于生成自然语言文本的各种应用程序,例如文本生成,机器翻译和语言理解。

在本文中,我们将探讨如何使用Python和PyTorch来训练ChatGPT,以及如何使用已经训练的模型来生成对话。
1.准备数据
在训练ChatGPT之前,我们需要准备一个大型的对话数据集。这个数据集应该包含足够的对话,覆盖各种主题和领域,以及各种不同的对话风格。这个数据集可以是从多个来源收集的,例如电影脚本,电视节目,社交媒体上的聊天记录等。
在本文中,我们将使用Cornell Movie Dialogs Corpus,一个包含电影对话的大型数据集。这个数据集包含超过22,000个对话,涵盖了多个主题和风格。
我们可以使用以下代码下载和解压缩Cornell Movie Dialogs Corpus,这个数据集也可以从[这里](https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html)手动下载。
import os
import urllib.request
import zipfile
DATA_URL = 'http://www.cs.cornell.edu/~cristian/data/cornell_movie_dialogs_corpus.zip'
DATA_DIR = './cornell_movie_dialogs_corpus'
DATA_FILE = os.path.join(DATA_DIR, 'cornell_movie_dialogs_corpus.zip')
if not os.path.exists(DATA_DIR):
os.makedirs(DATA_DIR)
if not os.path.exists(DATA_FILE):
print('Downloading data...')
urllib.request.urlretrieve(DATA_URL, DATA_FILE)
print('Extracting data...')
with zipfile.ZipFile(DATA_FILE, 'r') as zip_ref:
zip_ref.extractall(DATA_DIR)2.数据预处理
在准备好数据集之后,我们需要对数据进行预处理,以便将其转换为模型可以处理的格式。在本教程中,我们使用了一个简单的预处理步骤,该步骤包括下列几步:
- 将数据拆分成句子pairs(上下文,回答)
- 去除标点符号和特殊字符
- 将所有的单词转换成小写
- 将单词映射到一个整数ID
- 将句子填充到相同的长度
下面是用于预处理数据的代码:
import re
import random
import numpy as np
import torch
def load_conversations():
id2line = {}
with open(os.path.join(DATA_DIR, 'movie_lines.txt'), errors='ignore') as f:
for line in f:
parts = line.strip().split(' +++$+++ ')
id2line[parts[0]] = parts[4]
inputs = []
outputs = []
with open(os.path.join(DATA_DIR, 'movie_conversations.txt'), 'r') as f:
for line in f:
parts = line.strip().split(' +++$+++ ')
conversation = [id2line[id] for id in parts[3][1:-1].split(',')]
for i in range(len(conversation) - 1):
inputs.append(conversation[i])
outputs.append(conversation[i+1])
return inputs, outputs
def preprocess_sentence(sentence):
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = re.sub(r"[^a-zA-Z?.!,]+", r" ", sentence)
sentence = sentence.lower()
return sentence
def tokenize_sentence(sentence, word2index):
tokenized = []
for word in sentence.split(' '):
if word not in word2index:
continue
tokenized.append(word2index[word])
return tokenized
def preprocess_data(inputs, outputs, max_length=20):
pairs = []
for i in range(len(inputs)):
input_sentence = preprocess_sentence(inputs[i])
output_sentence = preprocess_sentence(outputs[i])
pairs.append((input_sentence, output_sentence))
word_counts = {}
for pair in pairs:
for sentence in pair:
for word in sentence.split(' '):
if word not in word_counts:
word_counts[word] = 0
word_counts[word] += 1
word2index = {}
index2word = {0: '<pad>', 1: '<start>', 2: '<end>', 3: '<unk>'}
index = 4
for word, count in word_counts.items():
if count >= 10:
word2index[word] = index
index2word[index] = word
index += 1
inputs_tokenized = []
outputs_tokenized = []
for pair in pairs:
input_sentence, output_sentence = pair
input_tokenized = [1] + tokenize_sentence(input_sentence, word2index) + [2]
output_tokenized = [1] + tokenize_sentence(output_sentence, word2index) + [2]
if len(input_tokenized) <= max_length and len(output_tokenized) <= max_length:
inputs_tokenized.append(input_tokenized)
outputs_tokenized.append(output_tokenized)
inputs_padded = torch.nn.utils.rnn.pad_sequence(inputs_tokenized, batch_first=True, padding_value=0)
outputs_padded = torch.nn.utils.rnn.pad_sequence(outputs_tokenized, batch_first=True, padding_value=0)
return inputs_padded, outputs_padded, word2index, index2word
3.训练模型
在完成数据预处理之后,我们可以开始训练ChatGPT模型。对于本文中的示例,我们将使用PyTorch深度学习框架来实现ChatGPT模型。
首先,我们需要定义一个Encoder-Decoder模型结构。这个结构包括一个GPT解码器,它将输入的上下文句子转换为一个回答句子。GPT解码器由多个Transformer解码器堆叠而成,每个解码器都包括多头注意力和前馈神经网络层。
import torch.nn as nn
from transformers import GPT2LMHeadModel
class EncoderDecoder(nn.Module):
def __init__(self, num_tokens, embedding_dim=256, hidden_dim=512, num_layers=2, max_length=20):
super().__init__()
self.embedding = nn.Embedding(num_tokens, embedding_dim)
self.decoder = nn.ModuleList([GPT2LMHeadModel.from_pretrained('gpt2') for _ in range(num_layers)])
self.max_length = max_length
def forward(self, inputs, targets=None):
inputs_embedded = self.embedding(inputs)
outputs = inputs_embedded
for decoder in self.decoder:
outputs = decoder(inputs_embedded=outputs)[0]
return outputs
def generate(self, inputs, temperature=1.0):
inputs_embedded = self.embedding(inputs)
input_length = inputs.shape[1]
output = inputs_embedded
for decoder in self.decoder:
output = decoder(inputs_embedded=output)[0][:, input_length-1, :]
output_logits = output / temperature
output_probs = nn.functional.softmax(output_logits, dim=-1)
output_token = torch.multinomial(output_probs, num_samples=1)
output_token_embedded = self.embedding(output_token)
output = torch.cat([output, output_token_embedded], dim=1)
return output[:, input_length:, :]然后,我们需要定义一个训练函数,该函数将使用梯度下降方法优化模型参数,并将每个epoch的损失和正确率记录到一个日志文件中。
def train(model, inputs, targets, optimizer, criterion):
model.train()
optimizer.zero_grad()
outputs = model(inputs, targets[:, :-1])
loss = criterion(outputs.reshape(-1, outputs.shape[-1]), targets[:, 1:].reshape(-1))
loss.backward()
optimizer.step()
return loss.item()
def evaluate(model, inputs, targets, criterion):
model.eval()
with torch.no_grad():
outputs = model(inputs, targets[:, :-1])
loss = criterion(outputs.reshape(-1, outputs.shape[-1]), targets[:, 1:].reshape(-1))
return loss.item()
def train_model(model, inputs, targets, word2index, index2word, num_epochs=10, batch_size=64, lr=1e-3):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu