目录
摘要
引言
方法
数据集
BotPercent架构
实验结果
活跃用户中的Bot数量
Bot Population among Comment Sections
Bot Participation in Content Moderation Votes
Bot Population in Different Countries’ Politics
论文链接:https://arxiv.org/pdf/2302.00381.pdf
摘要
Twitter机器人检测在打击错误信息、识别恶意在线活动和保护社交媒体话语完整性方面变得越来越重要。虽然现有的机器人检测文献主要集中在识别单个机器人上,但如何估计特定社区和社交网络中机器人的比例仍未得到充分探讨,这对内容版主和日常用户都有很大的影响。
在这项工作中,我们提出了社区级机器人检测,这是一种通过估计机器人账户的百分比来估计在线社区恶意干扰数量的新方法。具体来说,我们引入了BotPercent,这是Twitter机器人检测数据集和基于特征、文本和图形的模型的融合,克服了现有个人级模型中的泛化问题,从而实现了更准确的社区级机器人估计。
实验表明,BotPercent在TwiBot-22基准测试上实现了最先进的社区级机器人检测性能,同时对特定用户特征的篡改表现出很强的鲁棒性。
借助BotPercent,我们以不同的方式分析在Twitter群组和社区的机器人率,例如所有活跃的Twitter用户,与党派新闻媒体互动的用户,参与Elon Musk内容审核投票的用户,以及不同国家和地区的政治社区。
我们的实验结果表明,Twitter机器人的存在并不是同质的,而是一种时空分布,其异质性应在内容审核、社交媒体政策制定等方面加以考虑。
引言
现有的Twitter机器人检测模型通常可以分为基于特征、基于文本和基于图形的方法;
尽管这些前沿的机器人检测方法取得了令人印象深刻的成果(Yang et al. 2020;Echeverrıa et al. 2018;Feng等2022a),他们只专注于个人层面的机器人检测,一次识别一个Twitter账户,而不考虑社区背景。
在这项工作中,我们提出了一个重要但尚未充分开发的社区级机器人检测设置,旨在估计社交网络社区内的机器人数量和百分比。
对于平台审核,社区级bot检测可以让决策者快速了解特定社区中bot的比例,并据此分配审核资源,同时告知社区成员不真实内容的风险。反过来,社交媒体用户可以对舆论操纵的企图更加警惕。
可以通过呈现集体统计数据而不是探查或跟踪单个用户来减轻隐私问题。这些以及其他商业和法律方面的考虑,使人们对了解总百分比的兴趣增加Twitter机器人(Varol 2022),这是我们工作的重点。
Botprecent:
训练数据和模型架构:对于训练数据,现有的个人级方法通常只利用一个数据集。由于公共可用数据集的领域和收集时间有限,单个方法只能捕获某些类型的Twitter机器人,并且难以泛化;因此,BotPercent合并了所有可用的Twitter机器人检测数据集,以增强泛化。
对于模型架构,个体级方法通常基于特征、文本或图形,并且只专注于检测传统机器人、社交机器人和高级机器人集群;由于不同类型的模型擅长处理不同的模态和检测不同类型的机器人,我们建议结合基于特征、文本和图形的方法来合并它们的归纳偏差,并增强BotPercent处理移动用户域的能力。BotPercent还对单个模型进行模型校准,并通过加权求和将它们的预测结合起来,从而得出从群组到人群的Twitter机器人数量的可靠估计。
实验:
我们首先在TwiBot-22机器人检测基准上评估BotPercent (Feng et al. 2022b)。大量的实验表明,BotPercent实现了社区级机器人检测的最先进性能,同时提高了对特定用户特征扰动的鲁棒性。
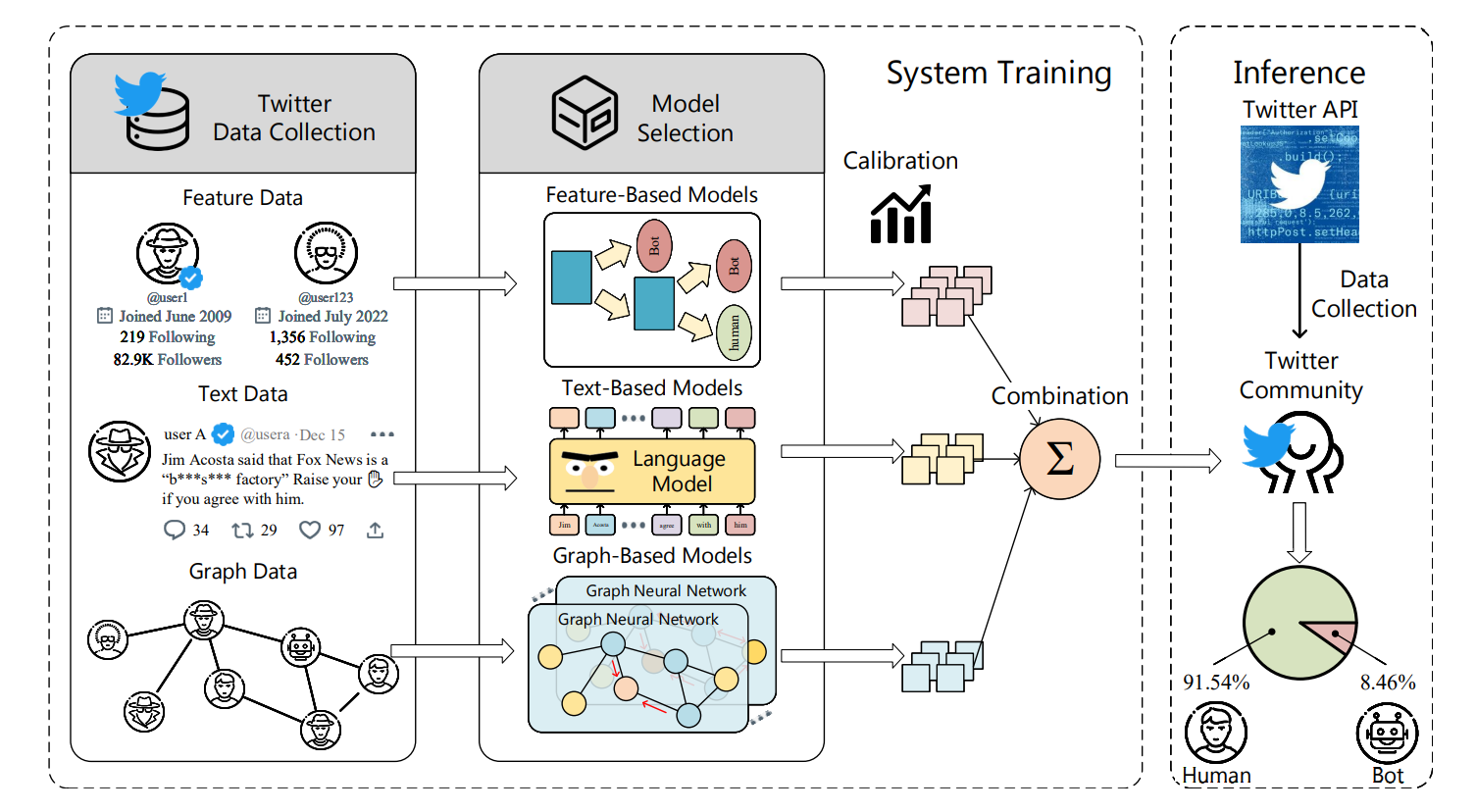
方法
BotPercent采用多数据集多模型机器人检测管道,同时利用置信度校准和可学习权重来准确估计Twitter社区中的机器人数量。
数据集
现有的个人级方法通常只利用一个数据集。这些数据集主要集中在一个特定的领域,并在一个特定的时间段内收集,这使得个人层面的模型泛化能力有限;相反,社区级机器人检测处理多样化的Twitter机器人社区,应该在任何给定的时间段内工作。
具体来说,我们收集了所有公开可用的Twitter机器人检测数据集。
Cresci -15 (Cresci et al. 2015)数据集主要由从志愿者基地和活跃的意大利Twitter用户收集的帐户组成;
GILANI-17中的用户(Gilani et al. 2017)数据集是用Twitter流API收集的,并根据关注者的数量分为四类。
CRESCI-17具有三种类型的机器人:传统垃圾机器人,社交垃圾机器人和假追随者。
midterm -18 (Yang et al. 2020)数据集是根据2018年美国中期选举期间收集的政治推文和活跃用户进行过滤的;
对于CRESCI-STOCK-18(Cresci et al. 2018, 2019)数据集,通过在2017年的五个月内找到包含选定标签的推文中具有相似时间轴的帐户来识别bot用户。
CRESCI-RTBUST-19 (Mazza et al. 2019)数据集是从2018年6月17日至30日之间的意大利转发中抓取的。
Botometer - feedback -19 (Yang et al. 2019)数据集是通过手工标记Botometer用户反馈注释的帐户来构建的。
TWIBOT-20 (Feng et al. 2021b)由来自四个兴趣域的用户组成2020年7月至9月。
TWIBOT-22 (Feng et al. 2022b)使用多样性感知的BFS通过扩展关注关系来收集用户;
共同利用所有现有资源Twitter机器人检测数据集,BotPercent提出了一个机器人检测系统,旨在更好地进行领域泛化。
BotPercent架构
考虑到不同类型的模型在面对多样化的机器人时各有优缺点(Sayyadiharikandeh等人,2020),我们提出了一个统一的框架来结合这些模型的归纳偏差,提高BotPercent的性能和泛化性。
具体来说,我们首先在三类中选择一些有代表性的模型,并在组合数据集上对它们进行训练。BotPercent然后将个人水平方法的输出结合成一个可靠的预测。
基于特征的模型提取用户特征并采用传统分类器(Varol et al. 2017)。为了构建一个全面的基于特征的模型作为BotPercent的一部分,我们总结了现有基于特征的模型中引入的特征,并获得了一个更全面的特征集。继前人研究(Yang et al. 2020;Knauth 2019), BotPercent利用随机森林(Ho 1995)和AdaBoost (Freund and Schapire 1997)作为一个有效的基于特征的模块,并获得二元预测逻辑。
基于文本的机器人检测模型利用用户的推文和描述来识别Twitter机器人和恶意内容(Feng et al. 2022b)。BotPercent利用预训练RoBERTa (Liu et al. 2019a)和T5 (rafael et al. 2020)在使用线性层进行分类的同时提取用户推文和描述的嵌入:
基于图的机器人检测模型利用Twitter网络结构和图神经网络来分析用户交互(Ali Alhosseini et al. 2019;Feng et al. 2022a)。对于基于图的模型,我们在BotPercent中选择了四种最先进的方法:SimpleHGN (Lv等人,2021)、HGT (Hu等人,2020)、BotRGCN (Feng等人,2021c)和RGT (Feng等人,2022a),因为这些模型考虑了社交网络中固有的异质性,并且在Twibot22基准上显示出了很好的机器人检测性能(Feng等人,2022b)。这些模型的消息传递范式可以概括为:
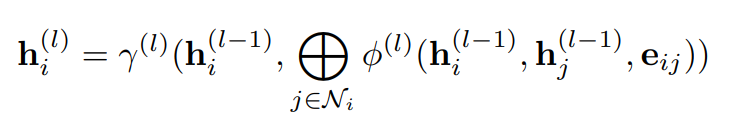
更具体地说,SimpleHGN采用了以边缘类型为读出函数γ的注意机制,HGT也采用了以边缘类型为不同投影矩阵的注意机制。BotRGCN以平均池化作为聚合函数,用不同的聚合矩阵对边缘类型进行处理,RGT利用关注机制在不同关系类型下传播消息,并通过不同关系类型的聚合表示进行传播。利用交叉熵损失对基于图的模型进行优化。
此外,由于数据依赖,BotPercent在分析大量Twitter社区时面临可扩展性问题:当BotPercent分析特定用户时,它会收集有关其多跳邻居的信息作为gnn的输入,这会导致指数级的数据收集成本。在Zhang等人(2021)的激励下,我们使用知识蒸馏(Hinton等人,2015)将基于图的检测器的知识转移到mlp。具体来说,蒸馏训练损失可表示为:
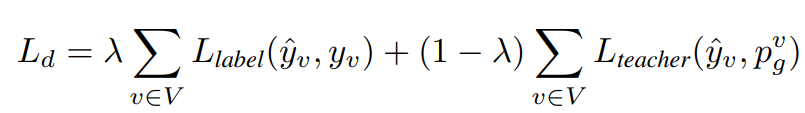
尽管二进制机器人探测器提供的分数表明每个帐户是机器人的可能性,但人们普遍认为,二进制分类器通常产生的置信度分数不能准确反映真实概率,模型经常被错误校准。由于社区级机器人检测依赖于对机器人概率的准确估计,原始模型得分需要进一步处理。BotPercent对所有子模型执行置信度校准,以确保估计概率和真实概率之间的一致性。具体来说,我们利用了温度缩放(Guo et al. 2017),这是一种后处理方法,通过在保留集上调整单个缩放参数来重新缩放置信度预测。
BotPercent在获得所有子模型的校准结果后,通过加权求和将预测结果进行组合:
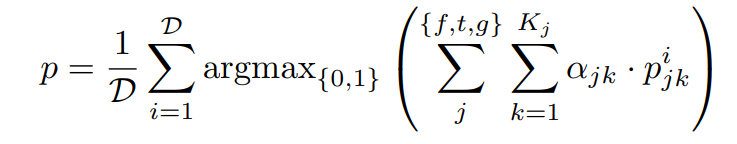
实验结果
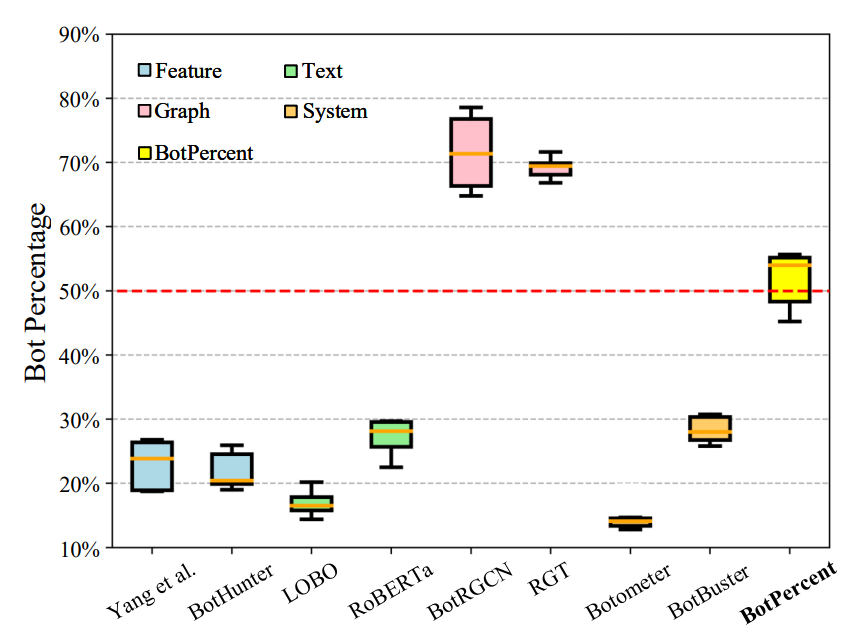
图3给出了BotPercent的估计和现有的方法。它表明BotPercent始终优于所有基线模型,包括最先进的个人机器人检测方法,如RGT。此外,基于特征和文本的方法通常低估了机器人的数量,而基于图形的方法通常高估了机器人的百分比。这些结果证明了BotPercent等多数据集多模型机器人检测框架对于提高泛化和估计精度的重要性。
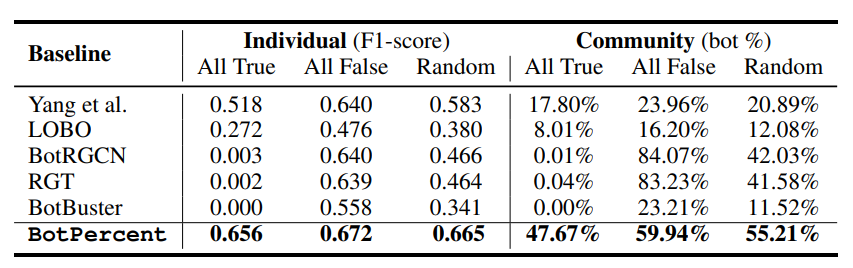
除了在社区级机器人检测上实现最先进的性能外,我们还评估个人层面的百分比。我们利用TwiBot-22基准测试中的1000个专家注释账户,并将其降采样到一个包含150人的平衡测试集
150机器人。如表2所示,BotPercent以最先进的精度实现了同等水平的性能,甚至在f1得分方面优于所有基线。

埃隆·马斯克于2022年接管推特后,推特的验证政策发生了重大变化:现有的验证用户可能会失去其验证状态,而之前未验证的用户可以通过订阅Twitter blue获得蓝色复选标记。
这对Twitter机器人检测有很大的影响,因为验证是多种类型的机器人探测器广泛采用的基本功能。因此,一个理想的机器人检测系统应该是鲁棒的,并且在这种特征扰动下保持稳定的预测
(Ng, Robertson, and Carley 2022),特别是对于已验证的二进制特征。
A)所有用户为已验证用户,b)所有用户为未验证用户,c)用户验证状态随机分配。这是为了模拟用户验证不再可靠的场景,以及机器人探测器在这种情况下的表现。我们将结果列于表中
3,这表明禁用验证功能将严重削弱几个现有的机器人检测系统的性能。
相反,由于其多模式和多模型管道,BotPercent在不同设置下保持稳定的性能,从而减少了对特定验证功能的过度依赖。
活跃用户中的Bot数量
我们首先用BotPercent来回答一个重要而又广受争议的问题:活跃Twitter用户中Twitter机器人的总体百分比。具体来说,我们使用Twitter API中的StreamClient函数对1%的实时tweet和相应的用户进行7天的采样1并采用对收集的105,614个用户进行分析。然后我们使用自举方法(Efron和Tibshirani)(1994)估计bot存在的抽样分布,并以95%的置信区间证明结果。
活跃用户中bot账户的百分比为8.46%,95%置信区间为(8.28%,8.64%)

值得注意的是,BotPercent的结论是8.46%大于Twitter(< 5%),显著小于Elon Musk (> 20%) (Porter 2022)。
Bot Population among Comment Sections
著名用户推文下的评论区是舆论的主战场(Weber 2014)。因此,我们调查了这些评论区的机器人百分比,并了解了以名人为中心和新闻分享组受到Twitter机器人攻击的程度。
我们收集了2022年12月23日至31日期间对这些用户发表评论的所有账号。
我们采用BotPercent对bot种群进行分析,结果如图所示4. 研究表明,加密货币名人评论区的bot百分比明显高于其他领域,技术领域的bot百分比也普遍高于平均水平,表明社交网络中bot的空间分布不均匀。

虽然之前的作品主要集中在政治领域的Twitter机器人(Woolley 2016;Forelle et al. 2015),我们的研究结果表明,Twitter机器人在多个领域都很活跃,尤其是加密货币和技术,而且机器人在政治之外的影响也值得研究,它对金融欺诈、市场操纵等方面的影响。
总的来说,Twitter和社交媒体已经成为政治话语的重要媒介,而Twitter机器人则被恶意行为者操纵,以干扰政治讨论(Caldarelli et al. 2020)。
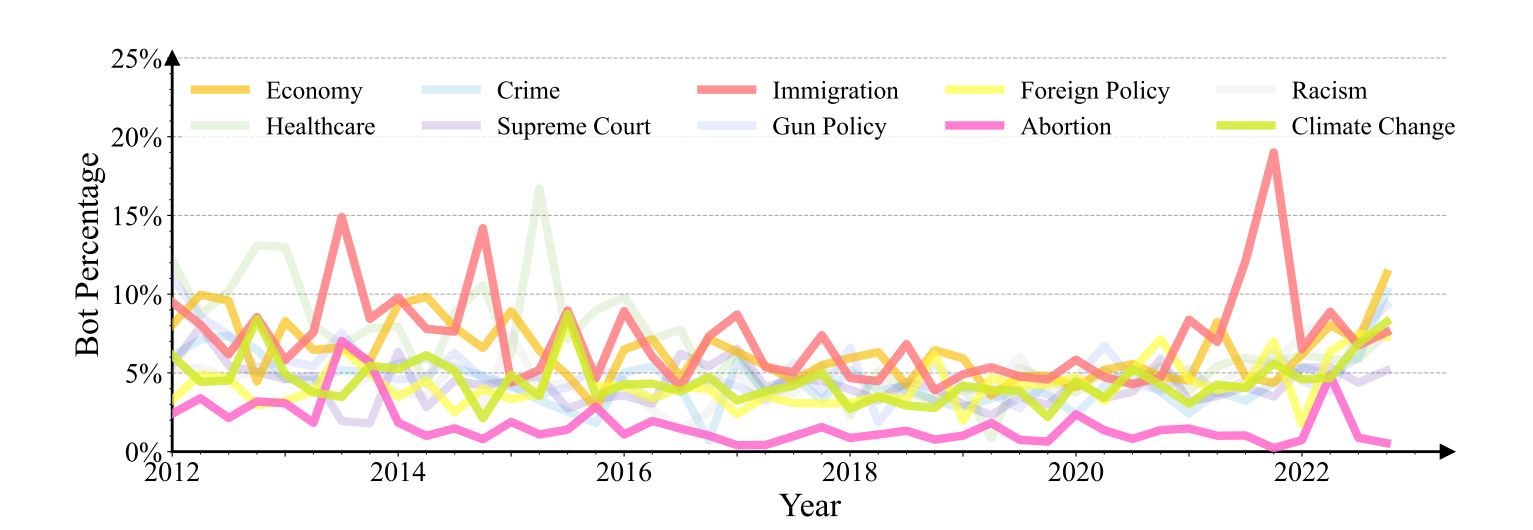
为了更好地理解Twitter机器人的政治干预模式,我们调查了11个政治话题,并使用Flores-Saviaga、Feng和Savage(2022)中提出的政治关键词来搜索不同时间段发布的推文,并分析相应的Twitter用户。对于每个政治话题,我们每季度收集1000个用户在过去十年中的推文2012年1月至2022年12月。如图6所示,bot账户的比例随着现实世界中的重大社会政治事件而变化。
Bot Participation in Content Moderation Votes
自2022年埃隆·马斯克(Elon Musk)收购Twitter以来,他对自己的个人账户进行了多次投票,其中两次投票产生了相应的内容审核结果:一次决定是否恢复唐纳德·特朗普在推特上的职位,另一次决定马斯克是否应该辞去推特首席执行官一职。
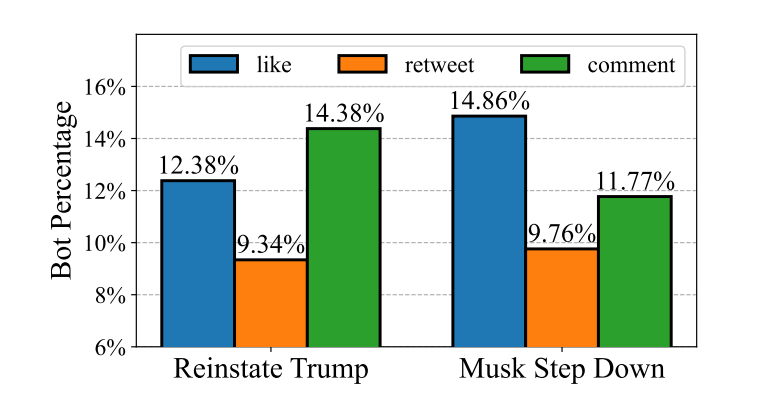
虽然内容审核的直接民主政策看起来直截了当,但它有许多问题,其中之一是恶意行为者通过Twitter机器人进行干预。为此,我们利用BotPercent用于调查转发、评论或喜欢这两次的用户中的bot数量,而具体的投票数据无法通过Twitter API获得
图9显示,在与两种内容审核投票进行交互的用户中,约有8%到14%是机器人。考虑到两党支持率接近(51.8%对48.2%),(57.5% vs . 42.5%),以至于机器人可能改变了结果,我们的分析对结果的有效性提出了质疑“大众之声,上帝之声”的社交媒体节制原则。
Bot Population in Different Countries’ Politics
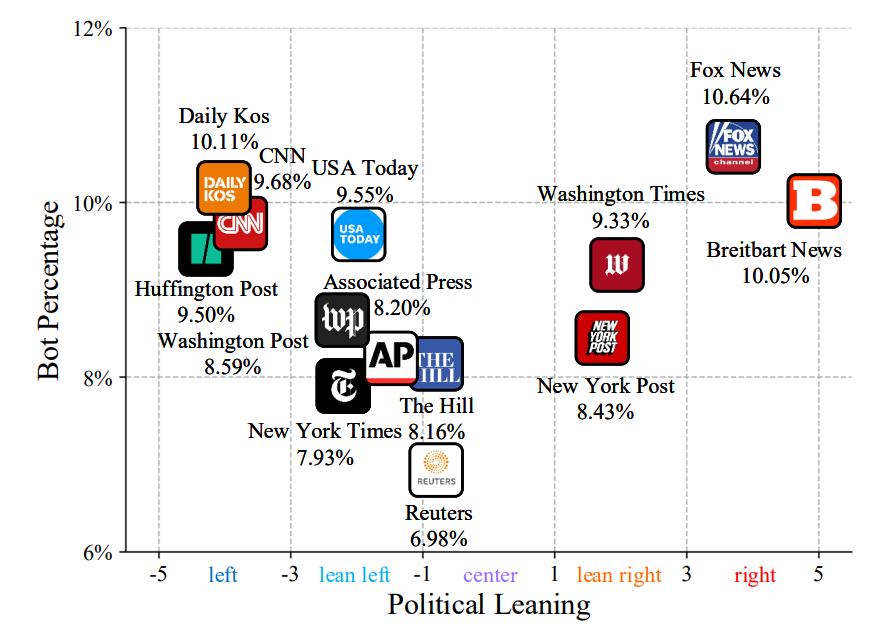
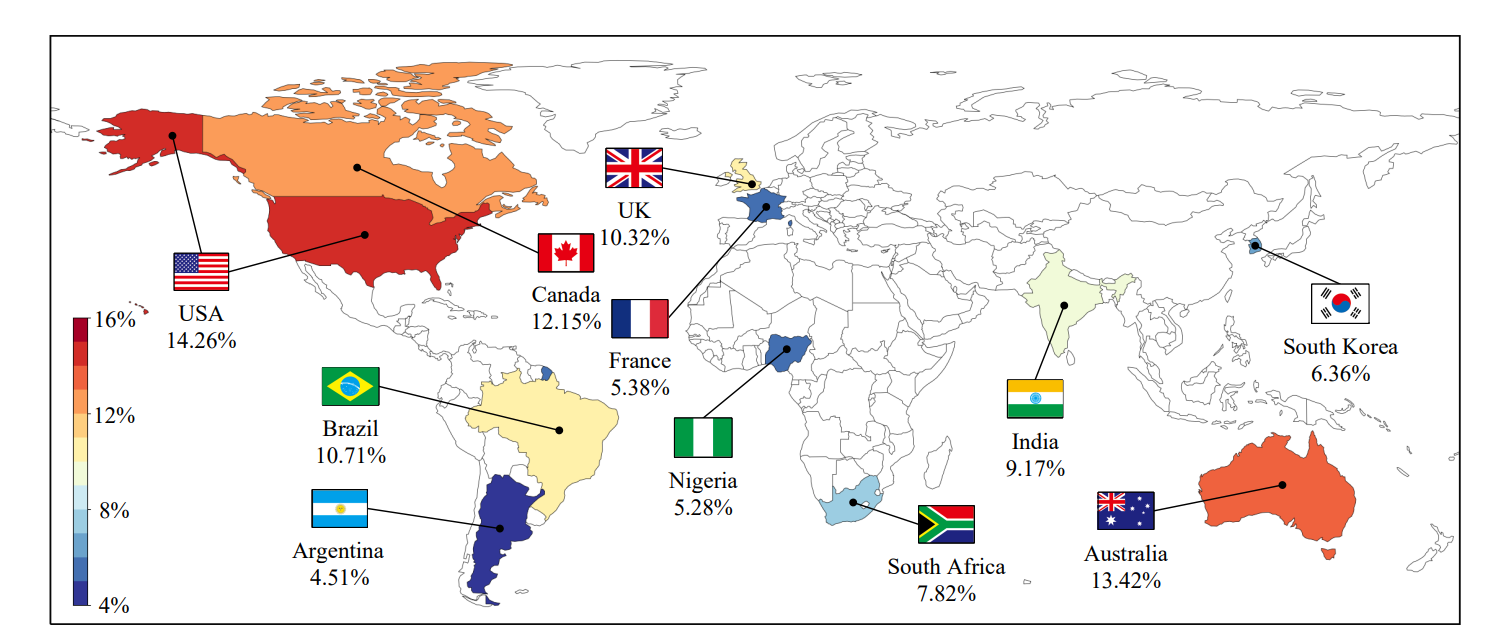
现有的关于推特机器人人口的研究主要集中在美国政治中的机器人(Bessi和Ferrara 2016;Yang et al. 2020),而忽视了可能存在类似问题的其他国家的政治格局。
我们通过调查不同国家政治社区的bot人口来补充稀缺的文献。具体来说,我们以总统或总理的Twitter账户为起点,抽样他们的追随者,作为不同国家政治参与社区的代理。图8显示,美国政治中机器人的比例最高,而其他英语国家也见证了更高水平的机器人干预。此外,阿根廷、法国和尼日利亚的政治社区中机器人的比例最低,这表明他们的政治话语更真实、更真实。这些结果再次证实,推特机器人在整个推特网络中具有空间模式,而恶意推特机器人在美国以外的国家的影响值得进一步研究。









![[操作系统] 进程的详细认识----从概念到调度](https://img-blog.csdnimg.cn/1b0d0e5f138945d79aa1e3adeb0362e5.png)