一、概念介绍
权重衰减(Weight Decay)是一种常用的正则化技术,它通过在损失函数中添加一个惩罚项来限制模型的复杂度,从而防止过拟合。
在训练参数化机器学习模型时, 权重衰减(weight decay)是最广泛使用的正则化的技术之一, 它通常也被称为L2正则化。
1.1理解:
权重衰减(weight_decay)本质上是一个L2正则化系数
那什么是参数的正则化?从我的理解上,就是让参数限定在一定范围,目的是为了不让模型对训练集过拟合。
注:应对过拟合最好的方法还是扩大有效样本(但成本过高)
1.2如何控制模型容量?
1.将模型变得比较小,减少里面参数的数量
2.缩小参数的取值范围
注:权重衰退就是通过限制参数的取值来实现
1.3硬性限制

即使得w的每个项的平方都小于θ这个值,最强情况下就是θ等于0,即所有w都等于0
1.4柔性限制

即损失函数后面加了一个非负项,为了使损失函数最小化,就得使得后面项足够小——起到限制w的作用,相比于硬性限制,柔性限制并没有将w的值限制在一个固定范围内。
1.5图解对最优解的影响


上式为不加限制条件的最优解,即图中的绿色中心点,但该点会使得||w||^2这一项较大,其和并不是最优解。
而加上限制的最优点即为图中两曲线的交叉点
1.6更新参数法则


1.7总结
~权重衰减是通过L2正则项使得模型参数不会过大,从而控制复杂度
~正则项权重是控制模型复杂度的超参数
二、示例演示
2.1模型构造
生成公式如下:

# 导入需要的库
import torch
from torch import nn
from d2l import torch as d2l
# 定义训练和测试数据集的大小,输入特征的维度和批次大小
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
# 定义真实的权重true_w和偏差true_b,并将其初始化为0.01和0.05
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
# 使用d2l.synthetic_data函数生成训练数据train_data和测试数据test_data
# 生成的数据是通过真实的权重和偏差加上一些噪声生成的
train_data = d2l.synthetic_data(true_w, true_b, n_train)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
# 使用d2l.load_array函数将训练数据train_data和测试数据test_data
# 转换为数据迭代器train_iter和test_iter
train_iter = d2l.load_array(train_data, batch_size)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)2.2初始化模型参数
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
# 初始化模型参数w和b
# w的形状为(num_inputs, 1),从正态分布中随机生成
# b初始化为0
# 参数需要计算梯度,requires_grad参数被设置为True
# 返回一个包含w和b的列表2.3定义L2范数
def l2_penalty(w):
return torch.sum(w.pow(2)) / 22.4定义训练代码实现
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估。
函数的具体实现如下:
-
首先通过init_params()函数初始化模型参数w和b。
-
定义net函数为线性回归模型,loss为平方损失函数。
-
设置训练的轮数num_epochs和学习率lr,同时创建一个可视化工具animator,用于可视化训练过程中的损失值。
-
在每个epoch中,遍历训练数据集train_iter,对每个小批量数据(X, y)进行如下操作:
-
计算模型的输出net(X),并计算损失函数loss(net(X), y)。
-
加上L2范数惩罚项lambd * l2_penalty(w),其中l2_penalty(w)为权重w的L2范数。
-
对损失函数进行反向传播,并使用SGD来更新模型参数w和b。
-
-
每5个epoch,计算训练集和测试集上的损失值,并使用animator将损失值可视化。
-
训练结束后,输出模型参数w的L2范数。
# 带有L2正则化的线性回归训练过程
# lambd表示L2正则化的强度
# 初始化模型参数w和b
w, b = init_params()
# 定义线性回归模型net和平方损失函数loss
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
# 设置训练的轮数num_epochs和学习率lr
# 创建一个可视化工具animator,用于可视化训练过程中的损失值
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
# 在每个epoch中,遍历训练数据集train_iter,对每个小批量数据(X, y)进行如下操作:
for epoch in range(num_epochs):
for X, y in train_iter:
# 计算模型的输出net(X),并计算损失函数loss(net(X), y)
# 加上L2范数惩罚项lambd * l2_penalty(w),其中l2_penalty(w)为权重w的L2范数
# 对损失函数进行反向传播,并使用SGD来更新模型参数w和b
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
# 每5个epoch,计算训练集和测试集上的损失值,并使用animator将损失值可视化
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
# 训练结束后,输出模型参数w的L2范数
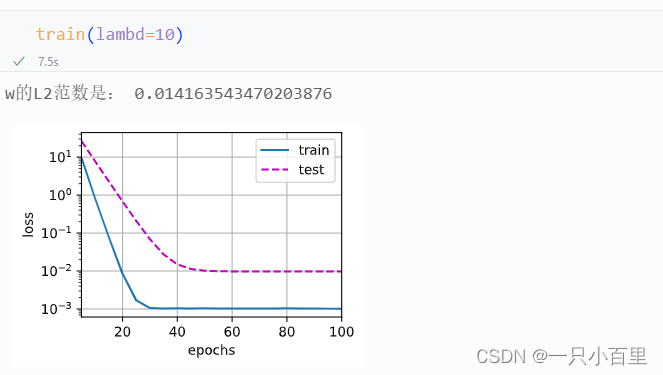
print('w的L2范数是:', torch.norm(w).item())2.5训练结果展示
在这段代码中,lambd是一个超参数,表示L2正则化的强度。在每个小批量数据的损失函数中,会加上L2范数惩罚项,以控制模型的复杂度和防止过拟合。L2正则化的强度由超参数lambd控制,lambd越大,模型的复杂度就越小,对训练数据的拟合程度就越差,但是可以更好地控制过拟合。反之,lambd越小,模型的复杂度就越大,对训练数据的拟合程度就越好,但是可能会过拟合。在模型训练过程中,我们通常会使用交叉验证等技术来选择最优的超参数lambd。
2.5.1忽略正则化直接训练
其中用lambd = 0禁用权重衰减后运行这个代码。 注意,虽然训练误差有了减少,但测试误差没有减少, 这意味着出现了严重的过拟合。

2.5.2使用权重衰减
下面,我们使用权重衰减来运行代码。 注意,在这里训练误差增大,但测试误差减小。 得到预期效果。
三.简洁实现代码
# 导入需要的库
import torch
from torch import nn
from d2l import torch as d2l
def train_concise(wd):
# 定义训练和测试数据集的大小,输入特征的维度和批次大小
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
# 使用nn.Sequential定义了一个单层全连接神经网络net
# 并将其参数使用param.data.normal_()方法初始化为随机值
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
# 使用nn.MSELoss定义平方损失函数loss
# 该损失函数的reduction参数设置为'none',表示不对损失值进行降维
loss = nn.MSELoss(reduction='none')
# 设置训练的轮数num_epochs和学习率lr
# 使用torch.optim.SGD定义一个优化器trainer,该优化器的参数包括网络的权重和偏差,以及权重衰减系数wd
num_epochs, lr = 100, 0.003
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
# 创建一个可视化工具animator,用于可视化训练过程中的损失值
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
# 在每个epoch中,遍历训练数据集train_iter,对每个小批量数据(X, y)进行如下操作:
for epoch in range(num_epochs):
for X, y in train_iter:
# 将优化器trainer的梯度清零
# 计算模型的输出net(X),并计算损失函数loss(net(X), y)
# 对损失函数进行反向传播,并使用优化器trainer来更新模型参数
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
# 每5个epoch,计算训练集和测试集上的损失值,并使用animator将损失值可视化。
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
train_concise(0) #lambd设置为0