前言
如果性能测试的目标服务器是linux系统,在如何使用linux自带的命令来实现性能测试过程的监控分析呢?
对于日常性能测试来讲,在linux下或是类Unix系统,我们必须掌握以下常用的指标查看命令。
-
ps
-
pstree
-
top
-
free
-
vmstat
-
iostat
-
iotop
-
sar
当然还有其他命令,这里就上述笔者常用的命令推荐大家掌握。
如果你想学习性能测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的性能测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
15天学会性能测试,通俗易懂详细教学,Jmeter性能测试实战(集群压测,全链路压测,性能调优,瓶颈分析)极速掌握,干就完事!_哔哩哔哩_bilibili15天学会性能测试,通俗易懂详细教学,Jmeter性能测试实战(集群压测,全链路压测,性能调优,瓶颈分析)极速掌握,干就完事!共计27条视频,包括:1.【性能测试】什么是性能测试以及性能测试的价值和目的、2.【性能测试】真实企业性能测试指标详解以及指标测算、3.【性能测试】真实企业中性能测试流程以及细节剖析等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV1B14y1D7X9/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1B14y1D7X9/?spm_id_from=333.337.search-card.all.click
ps
ps命令能给出当前系统中进程的快照。下面我们列举几个常用的选项,对于其他的请参考官方文档或是自行搜索相关文档。
-
使用 -a 参数。-a 代表 all。同时加上x参数会显示没有控制终端的进程。
ps -ax-
通过我们会查找某类或包含某些指定关键字的进程,这是会使用管道结合grep命令来进一步过滤结果。
例如查找java相关的进程ps -ax | grep java-
有时我们则需要根据CPU和内存的使用情况来过滤排序筛选结果,这样便于快速找到哪个进程最耗CPU、内存
ps -aux-
根据CPU的使用升序排序
ps -aux --sort -pcpu-
根据内存使用升序排序
ps -aux --sort -pmem-
上述两个命令合并一起,如下:
ps -aux --sort -pcpu,+pmem-
只显示前几个进程,例如显示前十个,需要使用管道结合head命令。
ps -aux | head -n 10还有很多用法,这里就不做过多的列举。
pstree
pstree命令以树状图显示进程间的关系。
下面我们看几个常用的示例。
-
以树状图显示进程,只显示进程的名字,且相同进程合并显示。
pstree-
以树状图显示进程,还显示进程PID。
pstree -p-
以树状图显示进程PID为<pid>的进程以及子孙进程,如果有-p参数则同时显示每个进程的PID。
pstree <pid>或
pstree -p <pid>-
以树状图显示进程,相同名称的进程不合并显示,并且会显示命令行参数,如果有-p参数则同时显示每个进程的PID。
pstree -a为什么要用pstree命令,通过该命令,能让你更清晰的了解你要监控的目标服务关联了哪些资源,能让你更加清楚其资源关联情况,增加在性能测试过程中分析的准确性。
不管是ps还是pstree命令,在性能测试过程中,最重要的一个应用技巧就是获取资源消耗最高的目标进程的线程id。例如:
ps -mp <pid> -o HTREAD
或
ps -Lfp <pid><pid> 为目标进程id在找到其线程id后就可以使用
printf "%x\n" 线程id转换成十六进制数
然后结合jstack命令,获取其堆栈信息以供分析。
top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
与ps不同的是,top显示系统当前的进程和其他状况,是一个动态显示过程,即可以通过用户按键来不断刷新当前状态。
直接使用即可
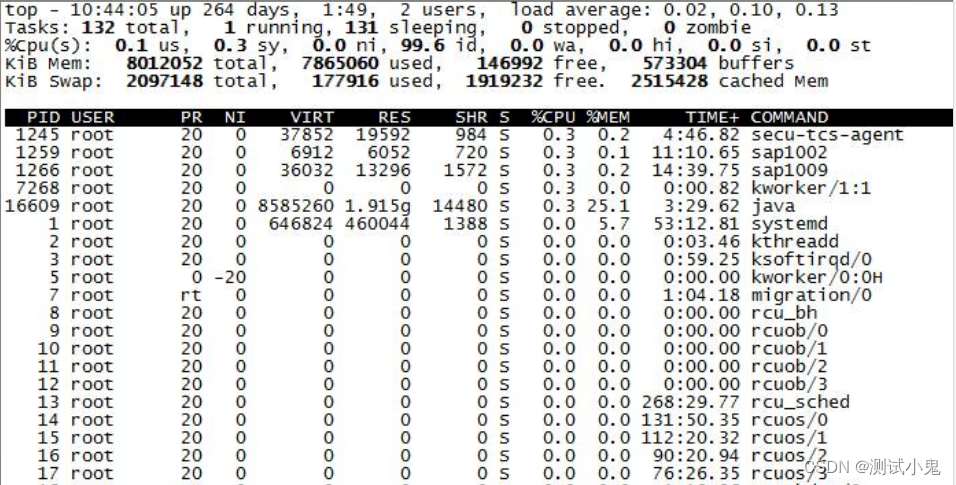
top常规情况下主要关注以下指标:
-
load average: 0.02, 0.10, 0.13 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
-
total 进程总数
-
running 正在运行的进程数
-
sleeping 睡眠的进程数
-
stopped 停止的进程数
-
zombie 僵尸进程数
Cpu(s):
-
us 用户空间占用CPU百分比
-
sy 内核空间占用CPU百分比
-
id 空闲CPU百分比
Mem:
-
total 物理内存总量
-
used 使用的物理内存总量
-
free 空闲内存总量
-
buffers 用作内核缓存的内存量
对于进程详细的表头重点关注: PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。
具体含义不做说明了。
另外常用的top命令选项如下: top 每隔5秒显式所有进程的资源占用情况
top -d 2 每隔2秒显式所有进程的资源占用情况
top -c 每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)
top -p <pid1> -p <pid2> 每隔5秒显示pid是pid1和pid是pid2的两个进程的资源占用情况
top -d 2 -c -p <pid> 每隔2秒显示pid是pid的进程的资源使用情况,并显式该进程启动的命令行参数
free
查看内存情况,将used的值减去buffer和cache的值就是你当前真实内存使用。

Mem:表示物理内存统计
-
total:表示物理内存总量(total = used + free)
-
used:表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。
-
free:未被分配的内存。
-
shared:共享内存,一般系统不会用到。
-
buffers:系统分配但未被使用的buffers 数量。
-
cached:系统分配但未被使用的cache 数量。
-/+ buffers/cache:表示物理内存的缓存统计
-
used:也就是第一行中的used – buffers-cached 也是实际使用的内存总量。
-
Swap:表示硬盘上交换分区的使用情况,这里我们不做关注。
但对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。 所以从应用程序的角度来说 可用内存=系统free memory+buffers+cached.
buffers是指用来给块设备做的缓冲大小,只记录文件系统的metadata以及 tracking in-flight pages.
cached是用来给文件做缓冲。
使用free命令,能让你清楚的了解当前系统内存消耗情况。
vmstat
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
相比于top、free等命令,vmstat可以看到整个机器的CPU,内存,IO的消耗情况。
一般情况下vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如下命令:
vmstat 2 12表示每个两秒采集一次服务器状态,1表示只采集一次。
这个命令是做性能测试进一步诊断分析必须掌握的的
下面我们对其进行更详细的说明:
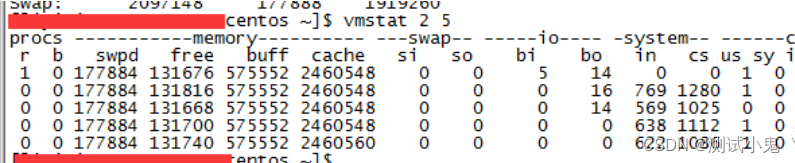
procs
-
r列 显示运行和等待CPU时间片的进程数,若其值长时间大于系统CPU个数,就说明CPU资源可能不足,可以考虑增加CPU;
-
b列 显示在等待资源的进程数,比如正在等待I/O或者内存交换等。
memory
-
swpd列 显示切换到内存交换区的内存数量(以KB为单位)。若swpd的值不为0或者比较大,同时si、so的值长时间为0,那这种情况一般不用担心,不会影响系统性能
-
free列 显示当前空闲的物理内存数量(以KB为单位)
-
buff列 显示buffers cache的内存数量,一般对块设备的读写才需要缓冲
-
cache列 显示page cached的内存数量,一般作文件系统的cached,频繁访问的文件都会被cached。如果cached值较大,就说明cached文件数较多。如果此时IO中的bi比较小,就说明文件系统效率比较好
swap
-
si列 显示由磁盘调入内存,也就是内存进入内存交换区的数量
-
so列 显示由内存调入磁盘,也就是内存交换区进入内存的数量
一般情况下,si、so的值都为0,如果si、so的值长时间不为0,则表示系统内存不足,需要考虑是否增加系统内存。
IO
-
bi列 显示从块设备读入的数据总量(即读磁盘,单位KB/秒)
-
bo列 显示写入到块设备的数据总量(即写磁盘,单位KB/秒)
这里设置的bi+bo参考值为1000,如果超过1000,而且wa值比较大,则表示系统磁盘IO性能瓶颈。
system
-
in列表示在某一时间间隔中观察到的每秒设备中断数
-
cs列表示每秒产生的上下文切换次数
上面这两个值越大,会看到内核消耗的CPU时间就越多,这个时候可能要考虑下为何内核的消耗会这么大,有可能有瓶颈存在。
CPU
-
us列 显示了用户进程消耗CPU的时间百分比。us的值比较高时,说明用户进程消耗的CPU时间多,如果长期大于50%,需要考虑优化程序啥的。
-
sy列显示了内核进程消耗CPU的时间百分比。sy的值比较高时,就说明内核消耗的CPU时间多;如果us+sy超过80%,就说明CPU的资源存在不足。
-
id列 显示了CPU处在空闲状态的时间百分比
-
wa列 显示IO等待所占的CPU时间百分比。wa值越高,说明IO等待越严重。如果wa值超过20%,说明IO等待严重
-
st列 虚拟机占用的时间百分比。
sar
sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。
如果你的系统没安装该命令,请用以下方式进行安装
apt-get install sysstat
yum install sysstat安装完成后在用以下命令启用:
vi /etc/default/sysstat
将ENABLED改为“true”
ENABLED="true"重启下sar服务,开始采集相关数据
/etc/init.d/sysstat start-
命令常用格式
sar [options] [-A] [-o file] t [n]
其中:
t为采样间隔,n为采样次数,默认值是1;
-o file表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项,sar命令常用选项如下:
-
sar参数说明
-A 查看汇总所有的报告-a 查看文件读写使用情况-B 查看附加的缓存的使用情况-b 查看缓存的使用情况-c 查看系统调用的使用情况-d 查看磁盘的使用情况-g 查看串口的使用情况-h 查看关于buffer使用的统计数据-m 查看IPC消息队列和信号量的使用情况-n 查看命名cache的使用情况-p 查看调页活动的使用情况-q 查看运行队列和交换队列的平均长度-R 查看进程的活动情况-r 查看没有使用的内存页面和硬盘块-u 查看CPU的利用率-v 查看进程、文件和锁表状态-w 查看系统交换活动状况-y 查看TTY设备活动状况-
查看CPU是否存在瓶颈:
sar -u sar -q-
查看内存是否存在瓶颈:
sar -Bsar -rsar -W-
查看IO是否存在瓶颈
sar -bsar -usar -d-
示例
例如,每10秒采样一次,连续采样3次,观察CPU 的使用情况,并将采样结果以二进制形式存入当前目录下的文件cpu_info中,需键入如下命令:
sar -u -o cpu_info 10 3
iostat
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
iotop
如果你想知道每个进程是如何使用IO的就比较麻烦。这个时候iotop可以上场了。
iotop 是一个用来监视磁盘 I/O 使用状况的 top 类工具。iotop 具有与 top 相似的 UI,其中包括 PID、用户、I/O、进程等相关信息。
其他命令
mpstat、netstat、pidstat也是常用的,大家看相关手册学习。这里不再进行说明
总结
linux的监控篇就分享这些,vmstat、sar必须掌握,至于top、free等简单命令,是基本的了,肯定是也要掌握的。不管怎么样,对于这些命令还是要多练习,多去把各个命令选项都用用,看看实际的输出,对分析下各个指标间的关系。









![uniapp小程序警告:[sitemap 索引情况提示]](https://img-blog.csdnimg.cn/7a9f542c59214cbf9317a0bc26229fa1.png)