Hive必问调优
Hive 调优拆解:Hive SQL 几乎是每一位互联网分析师的必备技能,相信很多小伙伴都有被面试官问到 Hive 优化问题的经历。所以掌握扎实的 HQL 基础尤为重要,hive优化也是小伙伴应该掌握的一项技能,本篇文章具体从hive建表优化、HQL语法优化、数据倾斜优化、hivejob优化四个大块讲解,带你系统的了解hive优化。
第1章 Hive建表优化
1.1 分区表
当我们的数据很大,我们就可以采取分区的方法减少参与数据的计算,分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。
Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多,所以我们需要把常常用在WHERE语句中的字段指定为表的分区字段。
1.1.1 分区表基本操作
先带大家了解下基础!

1)创建分区表语法
(default)> create table ods_game_dev.ods_user_login(deptno int, dname string, loc string)partitioned by (day string)row format delimited fields terminated by '\t';注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的为列。
2)查询分区表中数据
hive (default)> alter table ods_game_dev.ods_user_login add partition(day='20200404');3)增加分区
hive (default)> alter table ods_game_dev.ods_user_login add partition(day='20200404');4)删除分区
hive (default)> alter table ods_game_dev.ods_user_login drop partition (day='20200406');5)查看分区表有多少分区
hive> show ods_game_dev.ods_user_login dept_partition;思考:如果有一天日志数据量很大,如何再将数据拆分?
1.1.2 动态分区
关系型数据库中,对分区表Insert数据时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive中也提供了类似的机制,即动态分区(Dynamic Partition),只不过,使用Hive的动态分区,需要进行相应的配置。
1)开启动态分区参数设置
#1.开启动态分区功能(默认true,开启)set hive.exec.dynamic.partition=true;#2.设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。) set hive.exec.dynamic.partition.mode=nonstrict;#3.在所有执行MR的节点上,最大一共可以创建多少个动态分区。默认1000set hive.exec.max.dynamic.partitions=1000;#4.在每个执行MR的节点上,最大可以创建多少个动态分区。 /*该参数需要根据实际的数据来设定。比如:源数据中包含了一年的数据,即day字段有365个值,那么该参数就需要设置成大于365,如果使用默认值100,则会报错。*/set hive.exec.max.dynamic.partitions.pernode=100#5.整个MR Job中,最大可以创建多少个HDFS文件。默认100000set hive.exec.max.created.files=100000#6.当有空分区生成时,是否抛出异常。一般不需要设置。默认falseset hive.error.on.empty.partition=false
1.2 分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。分区针对的是数据的存储路径,分桶针对的是数据文件。分桶表的作用是方便抽样和提高join的效率。
1.2.1 分桶表的基本操作
(1)创建分桶表
create table test_buck(id int, name string)clustered by(id)into 4 bucketsrow format delimited fields terminated by '\t';
(2)查看表结构
hive (default)> desc formatted test_buck;Num Buckets: 4
(3)导入数据到分桶表中,load的方式
hive (default)> load data inpath '/student.txt' into table test_buck;(4)查询分桶的数据
hive(default)> select * from test_buck;(5)分桶规则
根据结果可知:Hive的分桶采用对分桶字段的值进行哈希,然后除以桶的个数求余的方 式决定该条记录存放在哪个桶当中。
2)分桶表操作需要注意的事项:
(1)reduce的个数设置为-1,让Job自行决定需要用多少个reduce或者将reduce的个数设置为大于等于分桶表的桶数;
(2)从hdfs中load数据到分桶表中,避免本地文件找不到问题;
(3)不要使用本地模式;3)insert方式将数据导入分桶表
hive(default)>insert into table test_buck select * from student_insert;1.2.2 抽样查询
对于非常大的数据集,有时用户需要使用的是一个具有代表性的查询结果而不是全部结果。Hive可以通过对表进行抽样来满足这个需求。
语法: TABLESAMPLE(BUCKET x OUT OF y)
#查询表test_buck中的数据。
hive (default)> select * from test_buck tablesample(bucket 1 out of 4 on id);注意:x的值必须小于等于y的值,否则报错如下:
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck
1.3 合适的文件格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
1.3.1 列式存储和行式存储
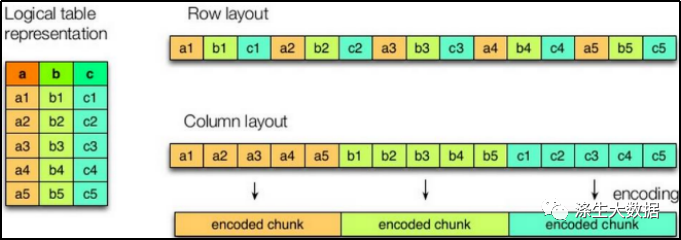
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
1)行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
2)列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
Tips
1.TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
2.ORC和PARQUET是基于列式存储的。1.3.2 TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
1.3.3 Orc格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
1.3.4 Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
1.4 合适的压缩格式
| 压缩格式 | hadoop自带? | 算法 | 文件扩展名 | 是否可切分 | 换成压缩格式后,原来的程序是否需要修改 |
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否,需要安装 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示。
| 压缩格式 | 对应的编码/解码器 |
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩性能的比较
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
On a single core of a Core i7 processor in 64-bit mode, Snappycompresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
http://google.github.io/snappy/第2章 HQL语法优化
2.1 列裁剪与分区裁剪
列裁剪就是在查询时只读取需要的列,分区裁剪就是只读取需要的分区。当列很多或者数据量很大时,如果 select * 或者不指定分区,全列扫描和全表扫描效率都很低。
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其他的列。这样做可以节省读取开销:中间表存储开销和数据整合开销。
2.2 Group By
默认情况下,Map阶段同一Key数据分发给一个Reduce,当一个key数据过大时就倾斜了。
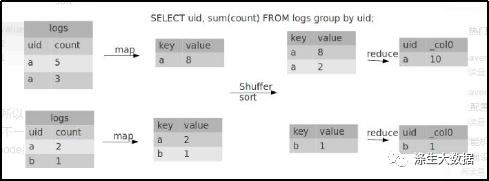
并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
开启Map端聚合参数设置
#1.是否在Map端进行聚合,默认为True
set hive.map.aggr = true;
#2.在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000;
#3.有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true;
//当选项设定为 true,生成的查询计划会有两个MR JobJob解析
第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作(虽然能解决数据倾斜,但是不能让运行速度的更快)。

2.3 Vectorization
vectorization : 矢量计算的技术,在计算类似scan, filter, aggregation的时候, vectorization技术以设置批处理的增量大小为 1024 行单次来达到比单条记录单次获得更高的效率。
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;2.4 多重模式
如果你碰到一堆SQL,并且这一堆SQL的模式还一样。都是从同一个表进行扫描,做不同的逻辑。有可优化的地方:如果有n条SQL,每个SQL执行都会扫描一次这张表。
insert .... select id,name,sex, age from student where age > 17;
insert .... select id,name,sex, age from student where age > 18;
insert .... select id,name,sex, age from student where age > 19;-- 隐藏了一个问题:这种类型的SQL有多少个,那么最终。这张表就被全表扫描了多少次
insert int t_ptn partition(city=A). select id,name,sex, age from student where city= A;
insert int t_ptn partition(city=B). select id,name,sex, age from student where city= B;
insert int t_ptn partition(city=c). select id,name,sex, age from student where city= c;
修改为:
from student
insert int t_ptn partition(city=A) select id,name,sex, age where city= A
insert int t_ptn partition(city=B) select id,name,sex, age where city= B如果一个 HQL 底层要执行 10 个 Job,那么能优化成 8 个一般来说,肯定能有所提高,多重插入就是一个非常实用的技能。一次读取,多次插入,有些场景是从一张表读取数据后,要多次利用。
2.5 in/exists语句
在Hive的早期版本中,in/exists语法是不被支持的,但是从 hive-0.8x 以后就开始支持这个语法。但是不推荐使用这个语法。虽然经过测验,Hive-2.3.6 也支持 in/exists 操作,但还是推荐使用 Hive 的一个高效替代方案:left semi join
比如说:-- in / exists 实现
select a.id, a.name from a where a.id in (select b.id from b);select a.id, a.name from a where exists (select id from b where a.id = b.id);
可以使用join来改写:
select a.id, a.name from a join b on a.id = b.id;应该转换成:left semi join 实现
select a.id, a.name from a left semi join b on a.id = b.id;2.6 CBO优化
join的时候表的顺序的关系:前面的表都会被加载到内存中。后面的表进行磁盘扫描。
select a.*, b.*, c.* from a join b on a.id = b.id join c on a.id = c.id;
Hive 自 0.14.0 开始,加入了一项 "Cost based Optimizer" 来对 HQL 执行计划进行优化,这个功能通过 "hive.cbo.enable" 来开启。在 Hive 1.1.0 之后,这个 feature 是默认开启的,它可以 自动优化 HQL中多个 Join 的顺序,并选择合适的 Join 算法。
CBO,成本优化器,代价最小的执行计划就是最好的执行计划。传统的数据库,成本优化器做出最优化的执行计划是依据统计信息来计算的。
Hive 的成本优化器也一样,Hive 在提供最终执行前,优化每个查询的执行逻辑和物理执行计划。这些优化工作是交给底层来完成的。根据查询成本执行进一步的优化,从而产生潜在的不同决策:如何排序连接,执行哪种类型的连接,并行度等等。
要使用基于成本的优化(也称为 CBO),请在查询开始设置以下参数:
set hive.cbo.enable=true;set hive.compute.query.using.stats=true;set hive.stats.fetch.column.stats=true;set hive.stats.fetch.partition.stats=true;
2.7 谓词下推
将 SQL 语句中的 where 谓词逻辑都尽可能提前执行,减少下游处理的数据量。对应逻辑优化器是 PredicatePushDown,配置项为hive.optimize.ppd,默认为true。
1)打开谓词下推优化属性
hive (default)> set hive.optimize.ppd = true;
#谓词下推,默认是true
Tips(规则总结,请悉知)
1.保留表的谓词写在join中不能下推,需要用where;
2.空表的谓词写在join之后不能下推,需要用on;
3.在 join关联情况下,过滤条件无论在join中还是where中谓词下推都生效;
4.在full join关联情况下,过滤条件无论在join中还是where中谓词下推都不生效。
2.8 MapJoin
MapJoin 是将 Join 双方比较小的表直接分发到各个 Map 进程的内存中,在 Map 进程中进行 Join 操 作,这样就不用进行 Reduce 步骤,从而提高了速度。如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,即:在Reduce阶段完成Join。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在Map端进行Join,避免Reducer处理。
1)开启MapJoin参数设置
#1.设置自动选择MapJoinset hive.auto.convert.join=true; #默认为true#2.大表小表的阈值设置(默认25M以下认为是小表):set hive.mapjoin.smalltable.filesize=25000000;
2)MapJoin工作机制
MapJoin 是将 Join 双方比较小的表直接分发到各个 Map 进程的内存中,在 Map 进程中进行 Join 操作,这样就不用进行 Reduce 步骤,从而提高了速度。
3)案例实操:
#1.开启MapJoin功能set hive.auto.convert.join = true; 默认为true#2.执行小表JOIN大表语句#注意:此时小表(左连接)作为主表,所有数据都要写出去,因此此时会走reduce,mapjoin失效
2.9 大表、大表SMB Join
SMB Join存在的目的主要是为了解决大表与大表间的 Join 问题,分桶其实就是把大表化成了“小表”,然后 Map-Side Join 解决之,这是典型的分而治之的思想。
#设置参数
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;关于数据倾斜、HiveJob的优化,我们下期为大家详细分析!!
当然hive企业进阶调优实战,PB级数据调优实战,请围观涤生老师企业调优实战课程哈:
hive企业真实调优实战(进阶课程),学完掌握简历上就敢写上深入掌握hive调优
https://www.bilibili.com/video/BV1jx4y1N787/?spm_id_from=333.999.0.0



![uniapp小程序警告:[sitemap 索引情况提示]](https://img-blog.csdnimg.cn/7a9f542c59214cbf9317a0bc26229fa1.png)