论文:https://arxiv.org/pdf/2112.10070.pdf
代码:https://github.com/ljynlp/W2NER
文章目录
- W2NER
- 介绍
- 模型架构
- 解码
- 源码介绍
- 数据输入格式
- 模型代码
- 参考资料
W2NER
介绍
W2NER模型,将NER任务转化预测word-word(备注,中文是字-字),它能够统一处理扁平实体、重叠实体和非连续实体三种NER任务。
假定摄入的句子 X 由 N 个tokne或word组成, X = { x 1 , x 2 , . . . , x N } X = \{x_1,x_2,...,x_N\} X={x1,x2,...,xN},模型对每个word pair( x i , x j x_i,x_j xi,xj)中的两个word关系类别R进行预测,其中 R ∈ { N o n e , N N W , T H W − ∗ } R\in\{None,NNW,THW-^*\} R∈{None,NNW,THW−∗}
- None:两个word之间没有关系,不属于同一实体
- NNW:即Next-Neighboring-Word,表示这两个word在同一个实体中相邻的位置
- THW-*:即Tail-Head-Word-*,表示这两个word在同一个实体中,且分别是实体的结尾和开始。用来判断实体的类别和边界,其中*是实体类型
举一个具体的例子(蓝色箭头为NNW、红色箭头为THW-*):
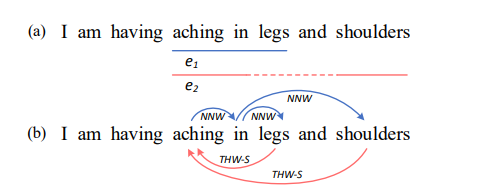
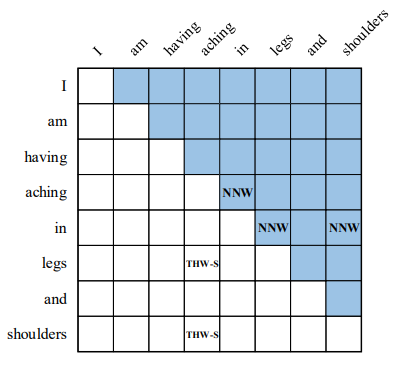
上面的句子中由两个症状(symptom)实体,“aching in legs” 和 “aching in shoulders”,分别记作 e 1 , e 2 e_1,e_2 e1,e2;针对这两个实体,可以得到(b)中的word-word之间的关系,将句子按word维度构建二维矩阵为:
模型架构
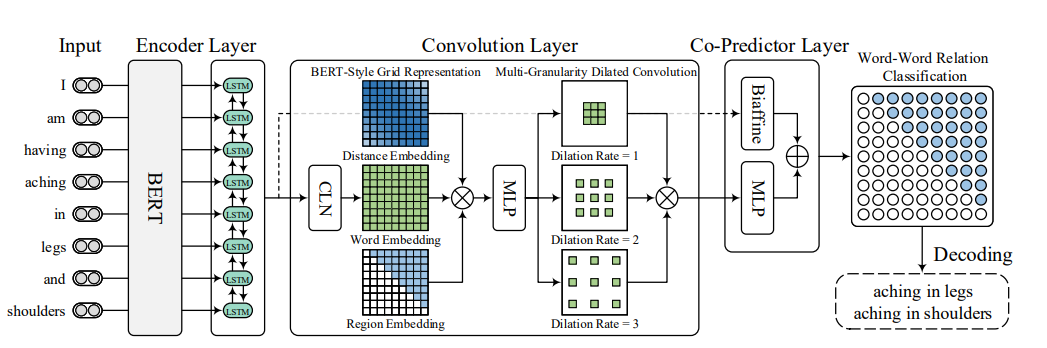
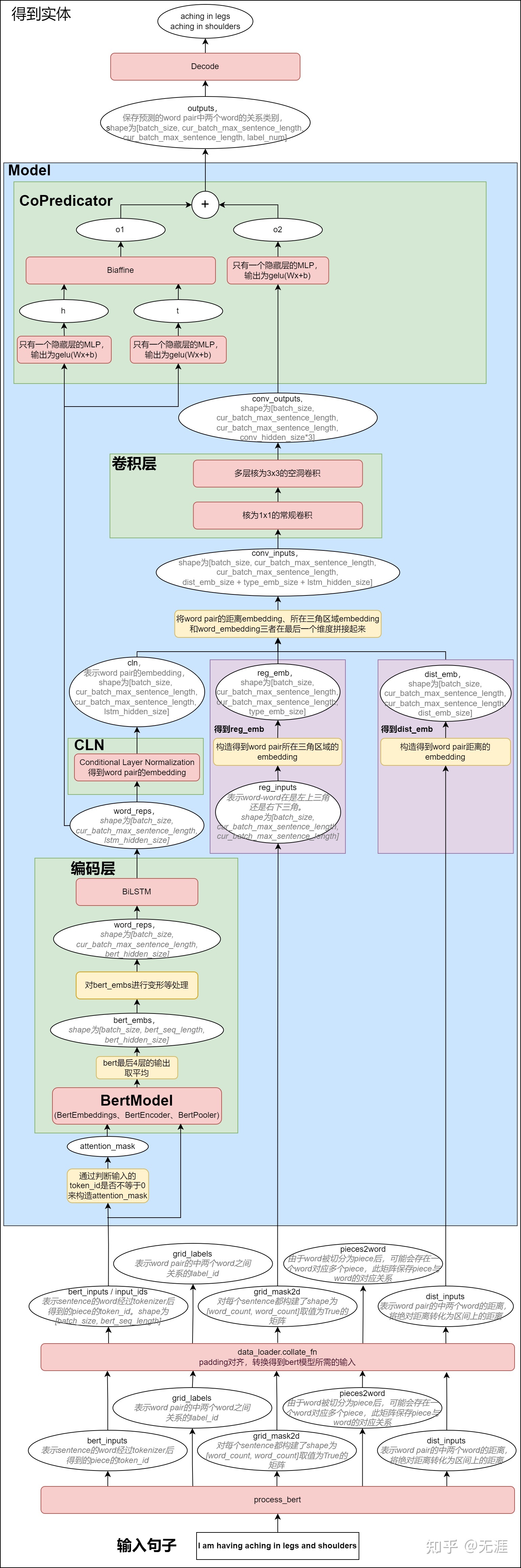
W2NER模型主要是用来预测word pair中两个word之间的关系,也就是最右边的这个图。
接下来,让我们来看下数据流转:
- 输入的sentence经过EncoderLayer(BERT + BiLSTM)得到word_reps
word_reps = {batch_size,cur_batch_max_sentence_length,lstm_hidden_size}
- 将word_reps经过CLN(Conditional Layer Normalization)层,得到cln
cln = {batch_size,cur_batch_max_sentence_length,cur_batch_max_sentence_length,lstm_hidden_size}
- 将word pair的distance_embedding和 三角区域的region_embedding 和 word_reps按最后一个维度拼接,得到conv_inputs
conv_inputs = {batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, dist_emb_size + type_emb_size + lstm_hidden_size}
- 将conv_inputs经过卷积层(核为1*1的常规二维卷积 + 核为3*3的多层空洞卷积),得到conv_outputs
conv_outputs = {batch_size, output_height = cur_batch_max_sentence_length, output_width = cur_batch_max_sentence_length, conv_hidden_size * 3}
- 将conv_outputs经过CoPredictor(由Biaffine + MLP组成),得到output
output = {batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, label_num}
此时对output对最后一个维度取softmax,可得到word-word pair,再进行关系解码
解码
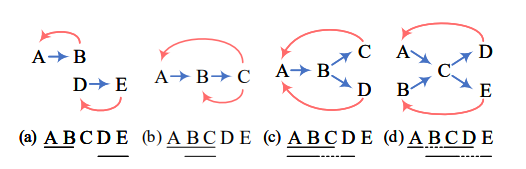
情况a(扁平实体)
(B,A)的关系为THW,则表示B是实体的结尾,A是实体的开始;又(A,B)的关系为NNW,表示A和B是在同一个实体中的相邻位置,所以得到扁平实体“AB”
同理可得扁平实体“DE”
情况b(重叠实体)
(C,A)的关系为THW,则C是实体的结尾,A是实体的开始;又(A,B)和(B,C)的关系均为NNW,表示A和B是在同一个实体中的相邻位置,B和C是在同一个实体中的相邻位置,所以得到扁平实体“ABC”
同理得到扁平实体“BC”
情况c(扁平实体 + 非连续实体)
得到扁平实体“ABC”、“ABD”
情况d(扁平实体 + 非连续实体)
得到非连续实体“ACD”、“BCE”
源码介绍
数据输入格式
B指batch_size,L指当前句子的长度
- bert_inputs:bert模型的输入token_ids,也就是input_ids包含[CLS]和[SEP] 维度[B,L + 2]
- grid_labels:标注数据实体构建的THW和NHW关系二维矩阵 维度[B,L,L]
- grid_mask2d:网格mask信息,有效信息True,padding为False,维度[B,L,L]
- dist_inputs:网格字符的相对位置信息,维度[B,L,L]
- pieces2word:维度[B,L,L+2]
- entity_text:用来标明实体信息,包括位置,类别。最后用来做评估使用
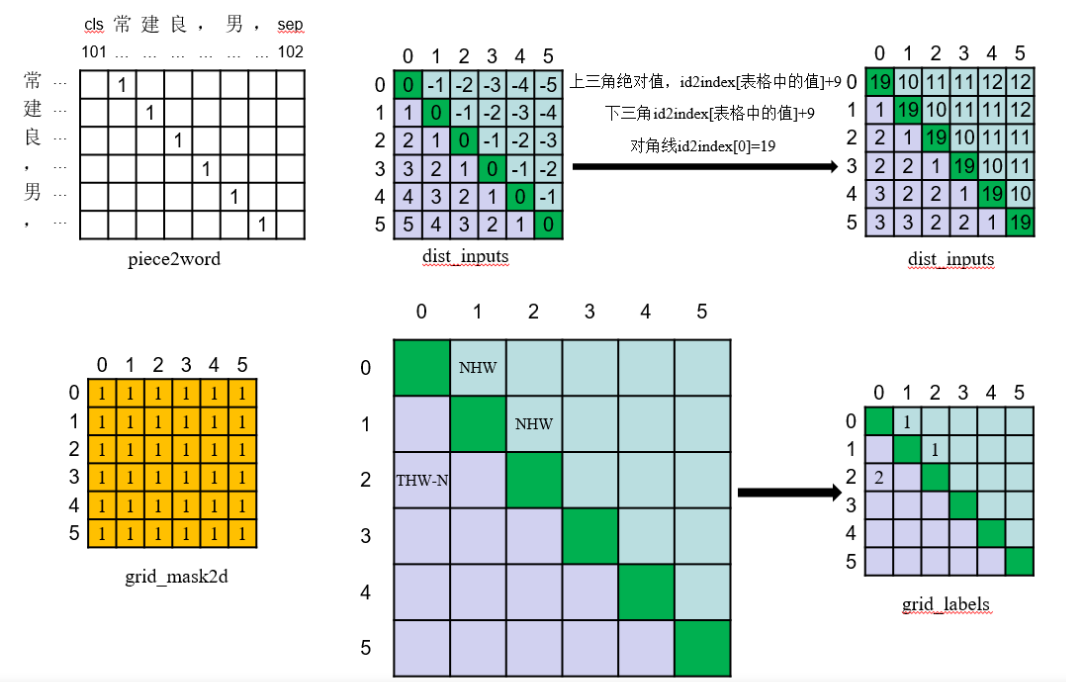
假设有句子:常建良,男
实体为:常建良(Name类型)
则pieces2word、pieces2word、grid_mask2d、grid_labels如下
id2index为
dis2idx = np.zeros((1000), dtype='int64')
dis2idx[1] = 1
dis2idx[2:] = 2
dis2idx[4:] = 3
dis2idx[8:] = 4
dis2idx[16:] = 5
dis2idx[32:] = 6
dis2idx[64:] = 7
dis2idx[128:] = 8
dis2idx[256:] = 9
模型代码
模型主类Model
class Model(BaseModel):
def __init__(self, use_bert_last_4_layers=False):
super().__init__()
self.use_bert_last_4_layers = use_bert_last_4_layers
self.bert = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, # segment_vocab_size=0,
output_all_encoded_layers = True if use_bert_last_4_layers else False)
lstm_input_size = self.bert.configs['hidden_size']
self.dis_embs = nn.Embedding(20, dist_emb_size)
self.reg_embs = nn.Embedding(3, type_emb_size)
self.encoder = nn.LSTM(lstm_input_size, lstm_hid_size // 2, num_layers=1, batch_first=True,
bidirectional=True)
conv_input_size = lstm_hid_size + dist_emb_size + type_emb_size
self.convLayer = ConvolutionLayer(conv_input_size, conv_hid_size, dilation, conv_dropout)
self.dropout = nn.Dropout(emb_dropout)
self.predictor = CoPredictor(label_num, lstm_hid_size, biaffine_size,
conv_hid_size * len(dilation), ffnn_hid_size, out_dropout)
self.cln = LayerNorm(lstm_hid_size, conditional_size=lstm_hid_size)
def forward(self, token_ids, pieces2word, dist_inputs, sent_length, grid_mask2d):
bert_embs = self.bert([token_ids, torch.zeros_like(token_ids)])
if self.use_bert_last_4_layers:
bert_embs = torch.stack(bert_embs[-4:], dim=-1).mean(-1) # 取最后四层的均值
length = pieces2word.size(1)
min_value = torch.min(bert_embs).item()
# 最大池化
_bert_embs = bert_embs.unsqueeze(1).expand(-1, length, -1, -1)
_bert_embs = torch.masked_fill(_bert_embs, pieces2word.eq(0).unsqueeze(-1), min_value)
word_reps, _ = torch.max(_bert_embs, dim=2)
# LSTM
word_reps = self.dropout(word_reps)
packed_embs = pack_padded_sequence(word_reps, sent_length.cpu(), batch_first=True, enforce_sorted=False)
packed_outs, (hidden, _) = self.encoder(packed_embs)
word_reps, _ = pad_packed_sequence(packed_outs, batch_first=True, total_length=sent_length.max())
# 条件LayerNorm
cln = self.cln(word_reps.unsqueeze(2), word_reps)
# concat
dis_emb = self.dis_embs(dist_inputs)
tril_mask = torch.tril(grid_mask2d.clone().long())
reg_inputs = tril_mask + grid_mask2d.clone().long()
reg_emb = self.reg_embs(reg_inputs)
conv_inputs = torch.cat([dis_emb, reg_emb, cln], dim=-1)
# 卷积层
conv_inputs = torch.masked_fill(conv_inputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
conv_outputs = self.convLayer(conv_inputs)
conv_outputs = torch.masked_fill(conv_outputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)
# 输出层
outputs = self.predictor(word_reps, word_reps, conv_outputs)
return outputs
ConvolutionLayer类
class ConvolutionLayer(nn.Module):
'''卷积层
'''
def __init__(self, input_size, channels, dilation, dropout=0.1):
super(ConvolutionLayer, self).__init__()
self.base = nn.Sequential(
nn.Dropout2d(dropout),
nn.Conv2d(input_size, channels, kernel_size=1),
nn.GELU(),
)
self.convs = nn.ModuleList(
[nn.Conv2d(channels, channels, kernel_size=3, groups=channels, dilation=d, padding=d) for d in dilation])
def forward(self, x):
x = x.permute(0, 3, 1, 2).contiguous()
x = self.base(x)
outputs = []
for conv in self.convs:
x = conv(x)
x = F.gelu(x)
outputs.append(x)
outputs = torch.cat(outputs, dim=1)
outputs = outputs.permute(0, 2, 3, 1).contiguous()
return outputs
CoPredictor类
class CoPredictor(nn.Module):
def __init__(self, cls_num, hid_size, biaffine_size, channels, ffnn_hid_size, dropout=0):
super().__init__()
self.mlp1 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)
self.mlp2 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)
self.biaffine = Biaffine(n_in=biaffine_size, n_out=cls_num, bias_x=True, bias_y=True)
self.mlp_rel = MLP(channels, ffnn_hid_size, dropout=dropout)
self.linear = nn.Linear(ffnn_hid_size, cls_num)
self.dropout = nn.Dropout(dropout)
def forward(self, x, y, z):
h = self.dropout(self.mlp1(x))
t = self.dropout(self.mlp2(y))
o1 = self.biaffine(h, t)
z = self.dropout(self.mlp_rel(z))
o2 = self.linear(z)
return o1 + o2
MLP类
class MLP(nn.Module):
'''MLP全连接
'''
def __init__(self, n_in, n_out, dropout=0):
super().__init__()
self.linear = nn.Linear(n_in, n_out)
self.activation = nn.GELU()
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.dropout(x)
x = self.linear(x)
x = self.activation(x)
return x
Biaffine类
class Biaffine(nn.Module):
'''仿射变换
'''
def __init__(self, n_in, n_out=1, bias_x=True, bias_y=True):
super(Biaffine, self).__init__()
self.n_in = n_in
self.n_out = n_out
self.bias_x = bias_x
self.bias_y = bias_y
weight = torch.zeros((n_out, n_in + int(bias_x), n_in + int(bias_y)))
nn.init.xavier_normal_(weight)
self.weight = nn.Parameter(weight, requires_grad=True)
def extra_repr(self):
s = f"n_in={self.n_in}, n_out={self.n_out}"
if self.bias_x:
s += f", bias_x={self.bias_x}"
if self.bias_y:
s += f", bias_y={self.bias_y}"
return s
def forward(self, x, y):
if self.bias_x:
x = torch.cat((x, torch.ones_like(x[..., :1])), -1)
if self.bias_y:
y = torch.cat((y, torch.ones_like(y[..., :1])), -1)
# [batch_size, n_out, seq_len, seq_len]
s = torch.einsum('bxi,oij,byj->boxy', x, self.weight, y)
# remove dim 1 if n_out == 1
s = s.permute(0, 2, 3, 1)
return s
参考资料
https://blog.csdn.net/HUSTHY/article/details/123870372
https://zhuanlan.zhihu.com/p/546602235
参照代码:
https://github.com/Tongjilibo/bert4torch/blob/master/examples/sequence_labeling/task_sequence_labeling_ner_W2NER.py