一、基本介绍
MapReduce是Hadoop的核心,是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(化简)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
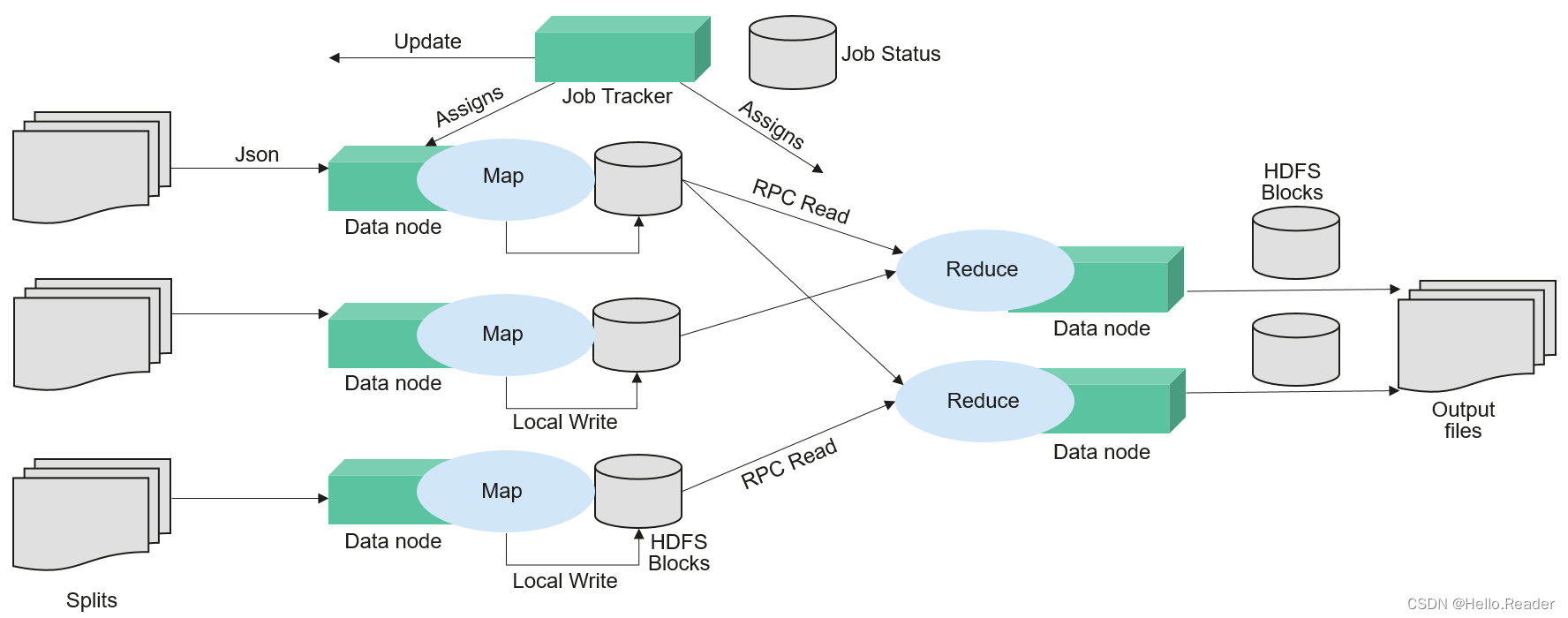
MapReduce是用于并行处理大数据集的软件框架。MapReduce的根源是函数性编程中的map和reduce函数。Map函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce函数接受Map函数生成的列表,然后根据它们的键缩小键/值对列表。MapReduce起到了将大事务分散到不同设备处理的能力,这样原本必须用单台较强服务器才能运行的任务,在分布式环境下也能完成。
更多信息,请参阅MapReduce教程。
二、MapReduce结构
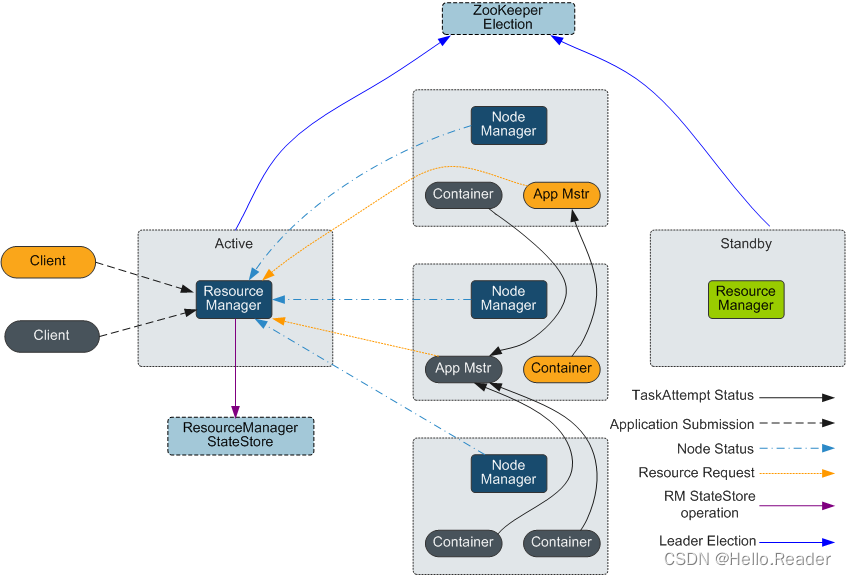
如下图所示,MapReduce通过实现YARN的Client和ApplicationMaster接口集成到YARN中,利用YARN申请计算所需资源。
三、MapReduce和HDFS的关系
- HDFS是Hadoop分布式文件系统,具有高容错和高吞吐量的特性,可以部署在价格低廉的硬件上,存储应用程序的数据,适合有超大数据集的应用程序。
- 而MapReduce是一种编程模型,用于大数据集(大于1TB)的并行运算。在MapReduce程序中计算的数据可以来自多个数据源,如Local
FileSystem、HDFS、数据库等。最常用的是HDFS,可以利用HDFS的高吞吐性能读取大规模的数据进行计算。同时在计算完成后,也可以将数据存储到HDFS。
四、MapReduce和YARN的关系
MapReduce是运行在YARN之上的一个批处理的计算框架。MRv1是Hadoop 1.0中的MapReduce实现,它由编程模型(新旧编程接口)、运行时环境(由JobTracker和TaskTracker组成)和数据处理引擎(MapTask和ReduceTask)三部分组成。该框架在扩展性、容错性(JobTracker单点)和多框架支持(仅支持MapReduce一种计算框架)等方面存在不足。MRv2是Hadoop 2.0中的MapReduce实现,它在源码级重用了MRv1的编程模型和数据处理引擎实现,但运行时环境由YARN的ResourceManager和ApplicationMaster组成。其中ResourceManager是一个全新的资源管理系统,而ApplicationMaster则负责MapReduce作业的数据切分、任务划分、资源申请和任务调度与容错等工作。