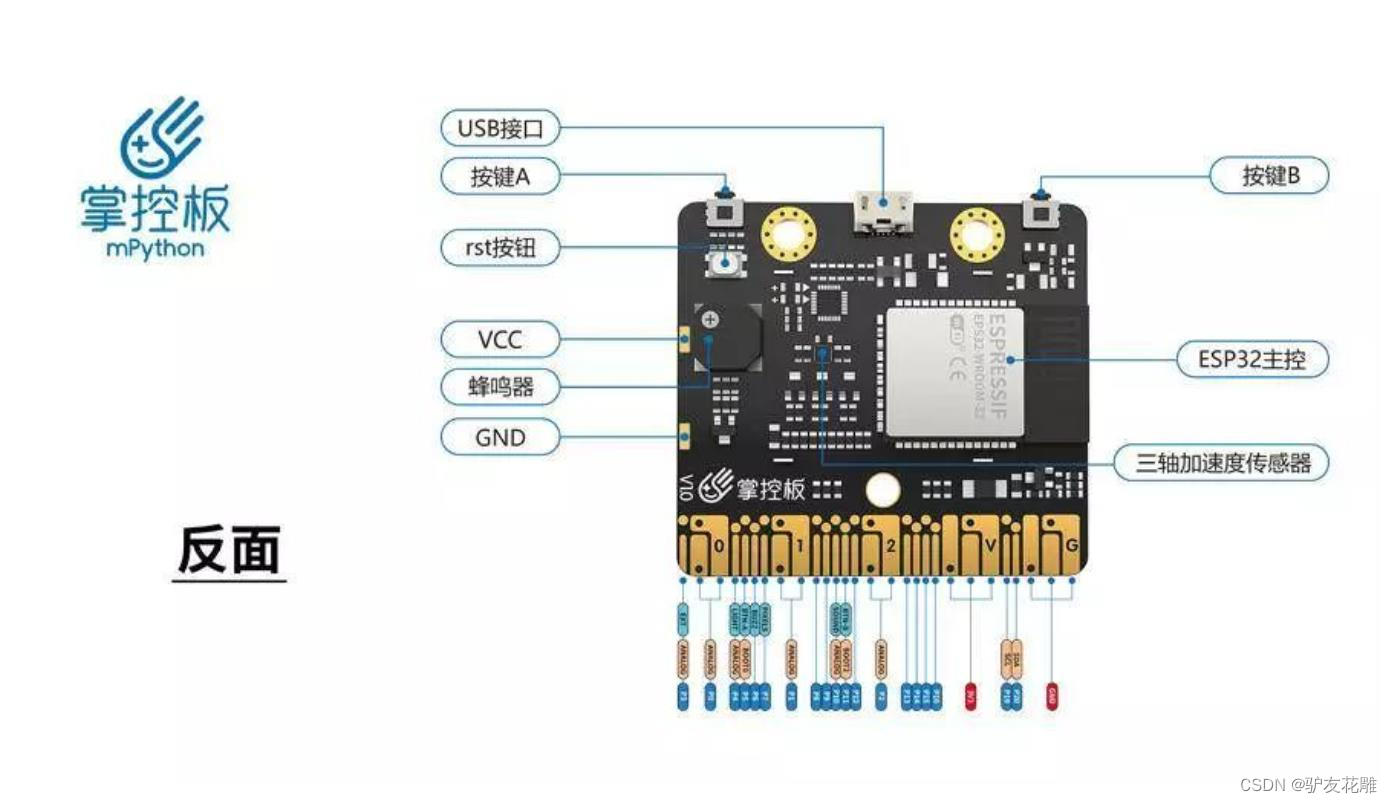
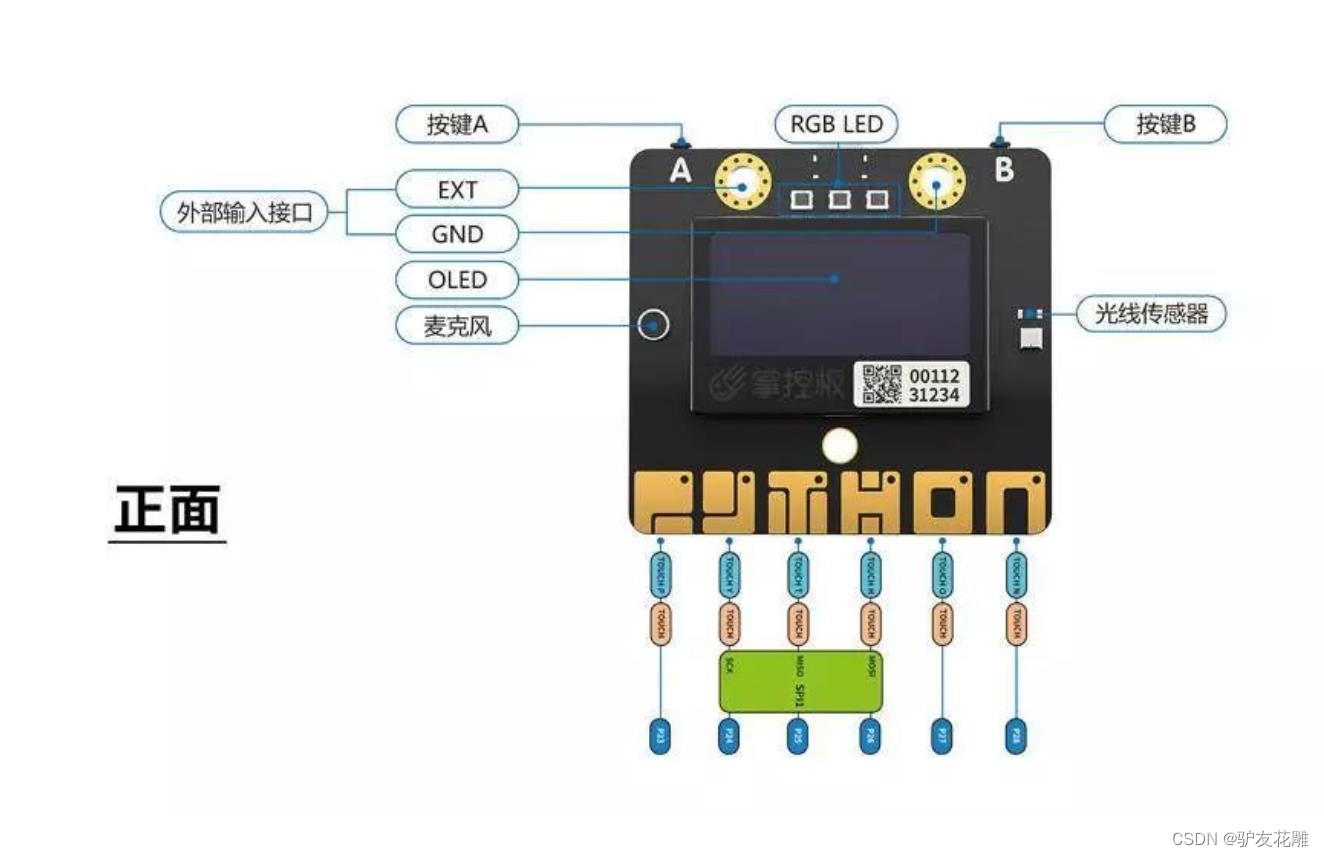
知识点:什么是掌控板?
掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED显示屏、RGB灯、加速度计、麦克风、光线传感器、蜂鸣器、按键开关、触摸开关、金手指外部拓展接口,支持图形化及MicroPython代码编程,可实现智能机器人、创客智造作品等智能控制类应用。

7、语音识别
说 ==语音合成(文字转为语音)
听 ==语音识别(语音转为文字)
语音识别是一门交叉学科。近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。 语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。中国物联网校企联盟形象得把语音识别比做为“机器的听觉系统”。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。 语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。语音识别技术车联网也得到了充分的引用,例如在翼卡车联网中,只需按一键通客服人员口述即可设置目的地直接导航,安全、便捷。

语音识别发展史
1952年贝尔研究所Davis等人研究成功了世界上第一个能识别10个英文数字发音的实验系统。1960年英国的Denes等人研究成功了第一个计算机语音识别系统。大规模的语音识别研究是在进入了70年代以后,在小词汇量、孤立词的识别方面取得了实质性的进展。进入80年代以后,研究的重点逐渐转向大词汇量、非特定人连续语音识别。在研究思路上也发生了重大变化,即由传统的基于标准模板匹配的技术思路开始转向基于统计模型 (HMM)的技术思路。此外,再次提出了将神经网络技术引入语音识别问题的技术思路。进入90年代以后,在语音识别的系统框架方面并没有什么重大突破。但是,在语音识别技术的应用及产品化方面出现了很大的进展。DARPA(Defense Advanced Research Projects Agency)是在70年代由美国国防部远景研究计划局资助的一项10年计划,其旨在支持语言理解系统的研究开发工作。到了80年代,美国国防部远景研究计划局又资助了一项为期10年的DARPA战略计划,其中包括噪声下的语音识别和会话(口语)识别系统,识别任务设定为“(1000单词)连续语音数据库管理”。到了90年代,这一DARPA计划仍在持续进行中。其研究重点已转向识别装置中的自然语言处理部分,识别任务设定为“航空旅行信息检索”。日本也在1981年的第五代计算机计划中提出了有关语音识别输入-输出自然语言的宏伟目标,虽然没能实现预期目标,但是有关语音识别技术的研究有了大幅度的加强和进展。1987年起,日本又拟出新的国家项目—高级人机口语接口和自动电话翻译系统。
语音识别在中国的发展
中国的语音识别研究起始于1958年,由中国科学院声学所利用电子管电路识别10个元音。直至1973年才由中国科学院声学所开始计算机语音识别。由于当时条件的限制,中国的语音识别研究工作一直处于缓慢发展的阶段。进入80年代以后,随着计算机应用技术在中国逐渐普及和应用以及数字信号技术的进一步发展,国内许多单位具备了研究语音技术的基本条件。与此同时,国际上语音识别技术在经过了多年的沉寂之后重又成为研究的热点,发展迅速。就在这种形式下,国内许多单位纷纷投入到这项研究工作中去。1986年3月中国高科技发展计划(863计划)启动,语音识别作为智能计算机系统研究的一个重要组成部分而被专门列为研究课题。在863计划的支持下,中国开始了有组织的语音识别技术的研究,并决定了每隔两年召开一次语音识别的专题会议。从此中国的语音识别技术进入了一个前所未有的发展阶段。
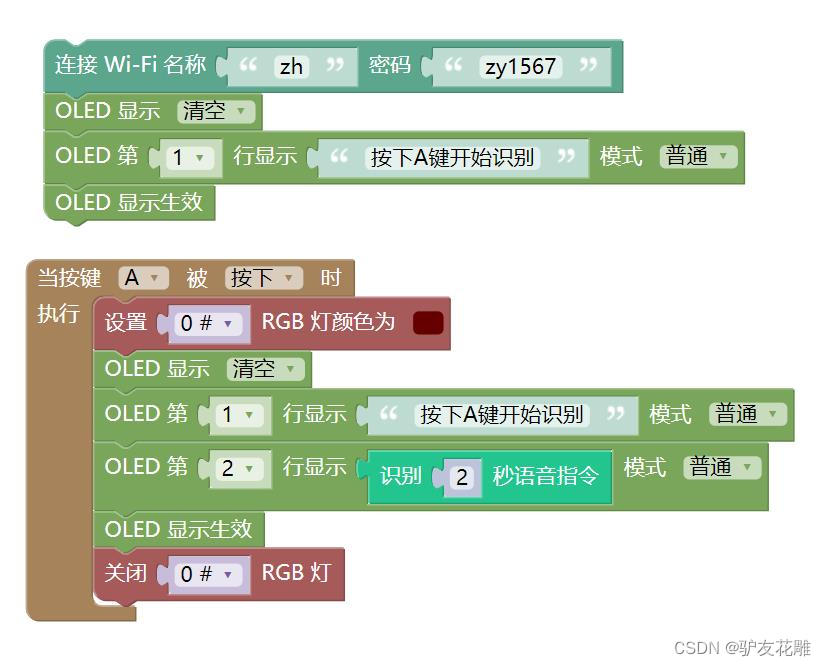
8、识别二秒语音指令(现录现识别)
#MicroPython动手做(25)——语音合成与语音识别
#识别二秒语音指令(现录现识别)
from mpython import *
import network
import time
import audio
import urequests
import json
import machine
import ubinascii
my_wifi = wifi()
my_wifi.connectWiFi("zh", "zy1567")
def on_button_a_down(_):
time.sleep_ms(10)
if button_a.value() == 1: return
rgb[0] = (int(102), int(0), int(0))
rgb.write()
time.sleep_ms(1)
oled.fill(0)
oled.DispChar("按下A键开始识别", 0, 0, 1)
oled.DispChar(get_asr_result(2), 0, 16, 1)
oled.show()
rgb[0] = (0, 0, 0)
rgb.write()
time.sleep_ms(1)
def get_asr_result(_time):
audio.recorder_init()
audio.record("temp.wav", int(_time))
audio.recorder_deinit()
_response = urequests.post("http://119.23.66.134:8085/file_upload",
files={"file":("temp.wav", "audio/wav")},
params={"appid":"1", "mediatype":"2", "deviceid":ubinascii.hexlify(machine.unique_id()).decode().upper()})
rsp_json = _response.json()
_response.close()
if "text" in rsp_json:
return rsp_json["text"]
elif "Code" in rsp_json:
return "Code:%s" % rsp_json["Code"]
else:
return rsp_json
button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down)
oled.fill(0)
oled.DispChar("按下A键开始识别", 0, 0, 1)
oled.show()
mPython X 图形编程
#MicroPython动手做(25)——语音合成与语音识别
#识别二秒语音指令(现录现识别)
https://v.youku.com/v_show/id_XNDY4MjY3NTgwOA==.html?spm=a2h0c.8166622.PhoneSokuUgc_1.dtitle

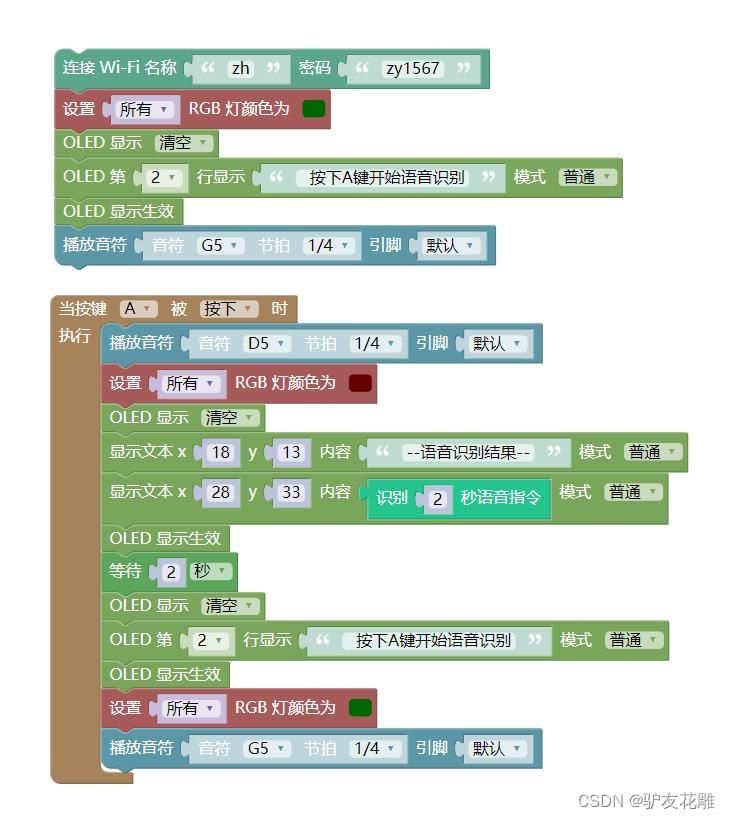
9、带提示音提示灯的简单语音识别系统
(红灯后识别二秒钟)
#MicroPython动手做(25)——语音合成与语音识别
#带提示音提示灯的简单语音识别系统(红灯后识别二秒钟)
from mpython import *
import network
import time
import music
import audio
import urequests
import json
import machine
import ubinascii
my_wifi = wifi()
my_wifi.connectWiFi("zh", "zy1567")
def on_button_a_down(_):
time.sleep_ms(10)
if button_a.value() == 1: return
music.play('D5:1')
rgb.fill((int(102), int(0), int(0)))
rgb.write()
time.sleep_ms(1)
oled.fill(0)
oled.DispChar("--语音识别结果--", 18, 13, 1)
oled.DispChar(get_asr_result(2), 28, 33, 1)
oled.show()
time.sleep(2)
oled.fill(0)
oled.DispChar(" 按下A键开始语音识别", 0, 16, 1)
oled.show()
rgb.fill((int(0), int(102), int(0)))
rgb.write()
time.sleep_ms(1)
music.play('G5:1')
def get_asr_result(_time):
audio.recorder_init()
audio.record("temp.wav", int(_time))
audio.recorder_deinit()
_response = urequests.post("http://119.23.66.134:8085/file_upload",
files={"file":("temp.wav", "audio/wav")},
params={"appid":"1", "mediatype":"2", "deviceid":ubinascii.hexlify(machine.unique_id()).decode().upper()})
rsp_json = _response.json()
_response.close()
if "text" in rsp_json:
return rsp_json["text"]
elif "Code" in rsp_json:
return "Code:%s" % rsp_json["Code"]
else:
return rsp_json
button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down)
rgb.fill((int(0), int(102), int(0)))
rgb.write()
time.sleep_ms(1)
oled.fill(0)
oled.DispChar(" 按下A键开始语音识别", 0, 16, 1)
oled.show()
music.play('G5:1')
mPython X 图形编程
带提示音提示灯的简单语音识别系统—实验视频
(红灯后识别二秒钟)
https://v.youku.com/v_show/id_XNDY4MzE1MjEyNA==.html?spm=a2h0c.8166622.PhoneSokuUgc_1.dtitle

10、语音控制开灯与关灯
——简单在线模式,反应有点慢,语音识别“开灯”,任意语音关灯。这个方案打开灯有点难,需要准确发音“开灯”二个字,反之关灯很容易,说什么都可以关灯,便于节约用电。
#MicroPython动手做(25)——语音合成与语音识别
#语音控制开灯与关灯(简单在线模式,反应有点慢)
from mpython import *
import network
import music
import time
import audio
import urequests
import json
import machine
import ubinascii
my_wifi = wifi()
my_wifi.connectWiFi("zh", "zy1567")
def on_button_a_down(_):
time.sleep_ms(10)
if button_a.value() == 1: return
rgb[1] = (int(102), int(0), int(0))
rgb.write()
time.sleep_ms(1)
if get_asr_result(2) == "开灯":
rgb.fill((int(51), int(102), int(255)))
rgb.write()
time.sleep_ms(1)
music.play('D5:1')
oled.fill(0)
oled.blit(image_picture.load('face/Objects/Light on.pbm', 0), 32, 0)
oled.show()
else:
rgb.fill( (0, 0, 0) )
rgb.write()
time.sleep_ms(1)
music.play('B5:1')
oled.fill(0)
oled.blit(image_picture.load('face/Objects/Light off.pbm', 0), 32, 0)
oled.show()
def get_asr_result(_time):
audio.recorder_init()
audio.record("temp.wav", int(_time))
audio.recorder_deinit()
_response = urequests.post("http://119.23.66.134:8085/file_upload",
files={"file":("temp.wav", "audio/wav")},
params={"appid":"1", "mediatype":"2", "deviceid":ubinascii.hexlify(machine.unique_id()).decode().upper()})
rsp_json = _response.json()
_response.close()
if "text" in rsp_json:
return rsp_json["text"]
elif "Code" in rsp_json:
return "Code:%s" % rsp_json["Code"]
else:
return rsp_json
image_picture = Image()
button_a.irq(trigger=Pin.IRQ_FALLING, handler=on_button_a_down)
oled.fill(0)
oled.DispChar(" 按下A键开始语音控制", 0, 16, 1)
oled.show()
music.play('G5:1')
rgb[1] = (int(0), int(51), int(0))
rgb.write()
time.sleep_ms(1)
mPython X 图形编程
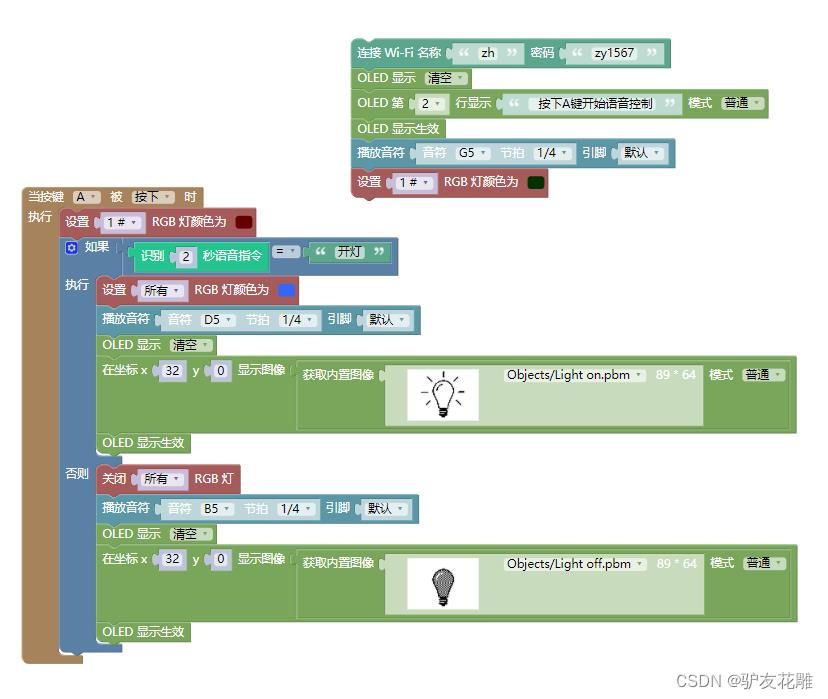
#MicroPython动手做(25)——语音合成与语音识别
#语音控制开灯与关灯(简单在线模式,反应有点慢)-视频
https://v.youku.com/v_show/id_XNDY4MzM5OTY1Ng==.html?spm=a2h0c.8166622.PhoneSokuUgc_1.dtitle

今天再次测试语音合成,不知为何一直报错,出错信息为:
刷入成功
Connection WiFi…
WiFi(zhz,-64dBm) Connection Successful, Config:(‘192.168.31.25’, ‘255.255.255.0’, '192.168
.31.34’, ‘192.168.31.34’)
(2020, 6, 15, 8, 28, 32, 0, 167)
Processing, please wait…
Traceback (most recent call last):
File “main.py”, line 24, in
File “xunfei.py”, line 208, in tts
File “uwebsockets/client.py”, line 62, in connect
Assertion Error: b’HTTP/1.1 403 Forbidden’
MicroPython v2.0.1-18-gbe8fbdd-dirty on 2020-04-24; mpython with ESP32
Type “help()” for more information.