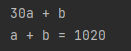介绍
这些令人着迷的对话机器人使用自然语言理解来理解输入。NLU 是自然语言处理的一个子集,使机器能够理解自然语言(文本/音频)。NLU 是大多数 NLP 应用程序(例如机器翻译、语音识别、构建聊天机器人等)中的关键组件。NLU 的基础是语言模型。
在本文中,我们将讨论 Open AI、GPT 及其变体的最先进语言模型,以及它如何导致 ChatGPT 的突破。本文涵盖的一些要点包括:
- 了解 ChatGPT 及其模型训练流程。
- 了解 GPT 架构的简史 - GPT 1、GPT 2、GPT 3 和 InstructGPT。
- 深入理解人类反馈强化学习(RHLF)。
GPT家族概述
最先进的语言模型架构是 Transformer。变压器的工作原理不亚于魔法。OpenAI 提出了这样一种 Transformer,即生成式预训练 Transformer 模型,俗称 GPT。
GPT是以自我监督的方式开发的。该模型在大量数据集上进行训练,以预测序列中的下一个单词。这称为休闲语言建模。然后,该语言模型在下游任务的监督数据集上进行微调。
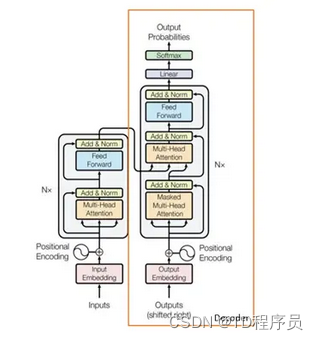

OpenAI 发布了三个不同版本的 GPT,即 GPT-1、GPT-2 和 GPT-3,以生成类似人类的对话。3 个版本的 GPT 大小不同。每个新版本都是通过扩大数据和参数来进行训练的。
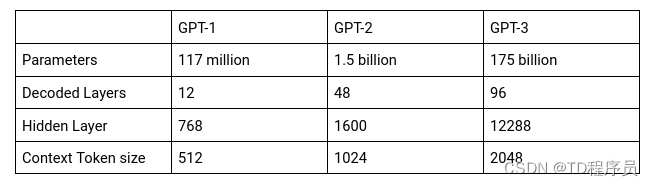

GPT-3 被称为自回归模型,经过训练只能通过查看过去的值来进行预测。GPT-3 可用于开发大型应用程序,例如搜索引擎、内容创建等等。但为什么GPT-3没能实现类人对话呢?让我们来看看吧。
为什么要指导GPT?
GPT-3 失败有两个主要原因。
GPT-3 的问题之一是模型输出与用户指令/提示不一致。简而言之,GPT-3 无法生成用户偏好的响应。
例如,给出提示“用几句话向 6 岁的孩子解释登月”,GPT-3 会生成如下图所示的不需要的响应。这种反应背后的主要原因是模型被训练来预测句子中的下一个单词。GPT-3 并未经过训练来生成人类偏好的反应。


另一个问题是,它可能会生成不安全和有害的评论,因为它无法控制文本。
为了解决这两个问题(对齐和有害评论),训练了一种新的语言模型来应对这些挑战。我们将在下一节中了解更多相关信息。
什么是InstructGPT?
InstructGPT 是一种语言模型,可生成用户首选的响应,以实现安全通信。因此,它被称为符合以下指令的语言模型。它使用一种称为“人类反馈强化学习”(RLHF) 的学习算法来生成更安全的响应。
来自人类反馈的强化学习是一种深度强化学习技术,它考虑了人类的学习反馈。人类专家通过从模型生成的响应列表中提供最可能的人类响应来控制学习算法。通过这种方式,代理可以模仿安全且真实的响应。
但为什么要根据人类反馈进行强化学习呢?为什么不使用传统的强化学习系统呢?
传统的强化学习系统需要定义奖励函数,以了解智能体是否朝着正确的方向前进,并旨在最大化累积奖励。但是,在现代强化学习环境中将奖励函数传达给代理非常具有挑战性。因此,我们不是为代理定义奖励函数,而是训练代理根据人类反馈学习奖励函数。这样,代理就可以学习奖励函数并理解环境的复杂行为。
在下一节中,我们将了解人工智能领域最热门的话题之一——ChatGPT。
ChatGPT 简介
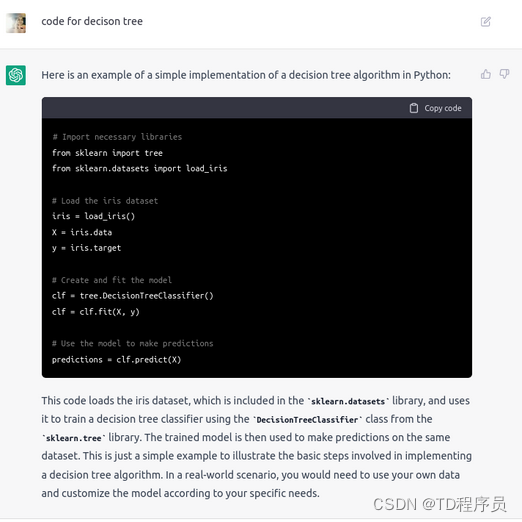
ChatGPT 现在是数据科学领域的热门话题。ChatGPT 只是一个模仿人类对话的聊天机器人。它可以回答向它提出的任何问题并记住之前发生的对话。例如,给出提示“决策树代码”,ChatGPT 会响应 Python 中决策树的实现,如下图所示。这就是 ChatGPT 的力量。最后我们会看到更多搞笑的例子。

根据 Open AI 的说法,ChatGPT 是 InstructGPT 的兄弟模型,它经过训练可以遵循提示中的说明并提供详细的响应。它是 InstructGPT 的修改版本,在模型训练过程中进行了更改。它可以记住之前发生的对话,然后做出相应的响应。
现在让我们看看 Instruct GPT 和 ChatGPT 有何不同。尽管纳入了来自人类反馈的强化学习,但 InstructGPT 并未完全对齐,因此仍然是有毒的。因此,这导致了 ChatGPT 的突破,数据收集设置发生了变化。


ChatGPT 是如何构建的?
ChatGPT 的训练方式与 InstructGPT 类似,但数据收集有所不同。现在让我们了解每个阶段的工作原理。
在第一步中,我们在包含一对提示和相关答案的数据集上微调 GPT-3。这是一项有监督的微调任务。相关答案由专家贴标者提供。
下一步,我们将学习奖励函数,帮助智能体决定什么是对的,什么是错的,然后朝着目标的正确方向前进。奖励函数是通过人类反馈学习的,从而确保模型生成安全、真实的响应。
以下是奖励建模任务涉及的步骤列表 -
- 针对给定的提示生成多个响应
- 人工贴标员会比较模型生成的提示列表,并将其从最好到最差进行排名。
- 然后使用该数据来训练模型。
在最后一步中,我们将使用近端策略优化算法(PPO)学习针对奖励函数的最优策略。PPO 是 Open AI 引入的一类新型强化学习技术。PPO 背后的想法是通过避免太大的策略更新来稳定代理训练。
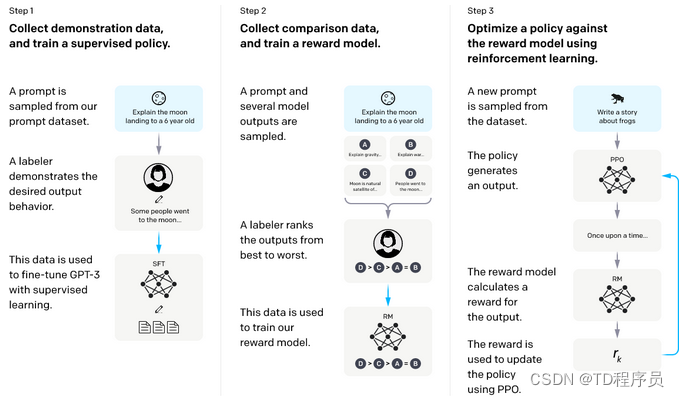

模型训练涉及的步骤
来源:https://openai.com/blog/chatgpt/
ChatGPT 的搞笑提示
现在,我们将看看 ChatGPT 生成的一些搞笑提示。
提示1:


提示2:
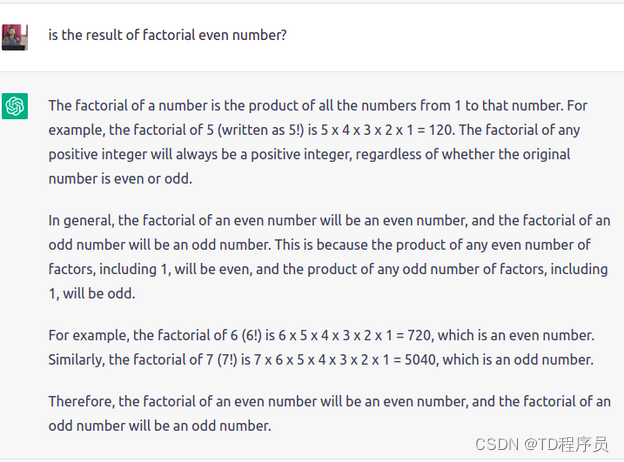

提示3:


结论
这将我们带到了文章的结尾。在本文中,我们讨论了 ChatGPT 以及如何使用深度强化学习技术对其进行训练。我们还介绍了 GPT 变体的简史以及它们如何导致 ChatGPT。