文章目录
- 1. 整体架构
- 2. 环境准备
- 3. 配置全局变量
- 4. 创建专属工作目录和存储桶
- 5. 创建 EMR Serverless Execution Role
- 6. 创建 EMR Serverless Application
- 7. 提交 Apache Hudi DeltaStreamer CDC 作业
- 7.1 准备作业描述文件
- 7.2 提交作业
- 7.3 监控作业
- 7.4 错误检索
- 7.5 停止作业
- 8. 结果验证
- 9. 评估与展望
Apache Hudi的DeltaStreamer是一种以近实时方式摄取数据并写入Hudi表的工具类,它简化了流式数据入湖并存储为Hudi表的操作,自 0.10.0 版开始,Hudi又在DeltaStreamer的基础上增加了基于Debezium的CDC数据处理能力,这使得其可以直接将Debezium采集的CDC数据落地成Hudi表,这一功能极大地简化了从源头业务数据库到Hudi数据湖的数据集成工作。本文发表于Apache Hudi公众号,本文地址:https://laurence.blog.csdn.net/article/details/132012360,转载请注明出处!
另一方面,得益于开箱即用和零运维的极致体验,越来越多的云上用户开始拥抱Serverless产品。Amazon云平台上的EMR是一个集成了多款主流大数据工具的计算平台,自6.6.0版本开始,EMR推出了 Serverless版本,开始提供无服务器的Spark运行环境,用户无需维护Hadoop/Spark集群,即可轻松提交Spark作业。
一个是“全配置”的Hudi工具类, 一个是“开箱即用”的Spark运行环境,两者结合在一起,无需编写CDC处理代码,无需构建Spark集群,仅通过一条命令,就可以轻松实现CDC数据入湖,这是一个非常吸引人的技术方案,本文我们就详细介绍一下这一方案的整体架构和实现细节。
1. 整体架构
Apache Huid在 0.10.0版引入的DeltaStreamer CDC是一整条CDC数据处理链路中的末端环节,为了能让大家清楚地理解DeltaStreamer在其中所处的位置和发挥的作用,我们有必要看一下完整架构:
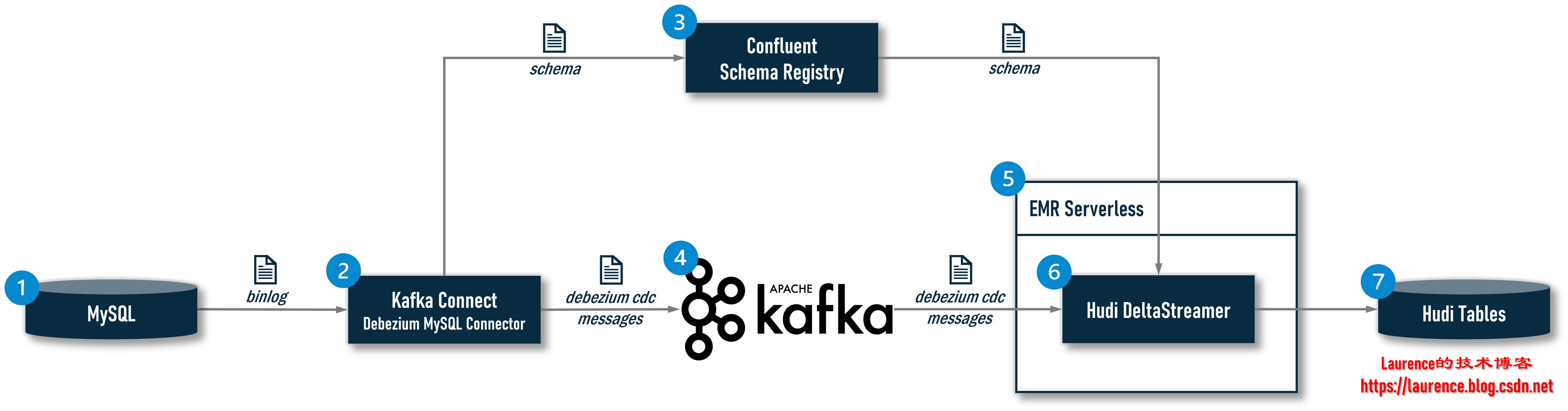
①:MySQL是一个业务数据库,是CDC数据的源头;
②:系统使用一个CDC摄取工具实时读取MySQL的binlog,业界主流的CDC摄取工具有:Debezium,Maxwell,FlinkCDC等,在该架构中,选型的是安装了Debezium MySQL Connector的Kafka Connect;
③:现在越来越多的CDC数据摄取方案开始引入Schema Registry用于更好的控制上游业务系统的Schema变更,实现更可控的Schema Evolution。在开源社区,较为主流的产品是Confluent Schema Registry,且目前Hudi的DeltaStreamer也仅支持Confluent这一种Schema Registry,所以该架构选型的也是它。引入Schema Registry之后,Kafka Connect在捕获一条记录时,会先在其本地的Schema Cache中查找是否已经存在对应的Schema,如果有,则直接从本地Cache中获得Schema ID,如果没有,则会将其提交给Schema Registry,由Schema Registry完成该Schema的注册并将生成的Schema ID返回给Kafka Connect,Kafka Connect会基于Schema ID对原始的CDC数据进行封装(序列化):一是将Schema ID添加到消息中,二是如果使用Avro格式传递消息,Kafka Connect会去除Avro消息中的Schema部分,只保留Raw Data,因为Schema信息已缓存在Producer和Consumer本地或可通过Schema Registry一次性获得,没有必要伴随Raw Data传输,这样可以大大减小Avro消息的体积,提升传输效率。这些工作是通过Confluent提供的Avro Converter(io.confluent.connect.avro.AvroConverter)完成的;
④:Kafka Connect将封装好的Avro消息投递给Kafka
⑤:EMR Serverless为DeltaStreamer提供Serverless的Spark运行环境;
⑥:Hudi的DeltaStreamer作为一个Spark作业运行在EMR Serverless环境中,它从Kafka读取到Avro消息后,会使用Confluent提供的Avro反序列化器(io.confluent.kafka.serializers.KafkaAvroDeserializer)解析Avro消息,得到Schema ID和Raw Data,反序列化器同样会先在本地的Schema Cache中根据ID查找对应的Schema,如果找到就根据这个Schema将Raw Data反序列化,如果没有找到,就向Schema Registry请求获取该ID对应的Schema,然后再进行反序列化;
⑦:DeltaStreamer将解析出来的数据写入存放在S3上的Hudi表,如果数据表不存在,会自动创建表并同步到Hive MetaStore中
2. 环境准备
限于篇幅,本文不会介绍①、②、③、④环节的构建工作,读者可以参考以下文档自行构建一套完整的测试环境:
①MySQL:如果仅以测试为目的,建议使用Debezium提供的官方Docker镜像,构建操作可参考其官方文档(下文将给出的操作示例所处理的CDC数据就是自于该MySQL镜像中的inventory数据库);
②Kafka Connect:如果仅以测试为目的,建议使用Confluent提供的官方Docker镜像,构建操作可参考其官方文档,或者使用AWS上托管的Kafka Connct:Amazon MSK Connect。需要提醒的是:Kafka Connect上必须安装Debezium MySQL Connector和Confluent Avro Converter两个插件,因此需要在官方镜像的基础上手动添加这两个插件;
③Confluent Schema Registry:如果仅以测试为目的,建议使用Confluent提供的官方Docker镜像,构建操作可参考其官方文档;
④Kafka:如果仅以测试为目的,建议使用Confluent提供的官方Docker镜像,构建操作可参考其官方文档,或者使用AWS上托管的Kafka:Amazon MSK
完成上述工作后,我们会获得“Confluent Schema Registry”和“Kafka Bootstrap Servers”两项依赖服务的地址,它们是启动DeltaStreamer CDC作业的必要条件,后续会以参数形式传递给DeltaStreamer作业。
3. 配置全局变量
环境准备工作就绪后,就可以着手第⑤、⑥、⑦部分的工作了。本文所有操作全部通过命令完成,以shell脚本形式提供给读者使用,脚本上会标注实操步骤的序号,如果是二选一操作,会使用字母a/b加以标识,部分操作还有示例供读者参考。为了使脚本具有良好的可移植性,我们将与环境相关的依赖项和需要用户自定义的配置项抽离出来,以全局变量的形式集中配置,如果您在自己的环境中执行本文操作,只需修改下面的全局变量即可,不必修改具体命令:
| 变量 | 说明 | 设定时机 |
|---|---|---|
| APP_NAME | 由用户为本应用设定的名称 | 提前设定 |
| APP_S3_HOME | 由用户为本应用设定的S3专属桶 | 提前设定 |
| APP_LOCAL_HOME | 由用户为本应用设定的本地工作目录 | 提前设定 |
| SCHEMA_REGISTRY_URL | 用户环境中的Confluent Schema Registry地址 | 提前设定 |
| KAFKA_BOOTSTRAP_SERVERS | 用户环境中的Kafka Bootstrap Servers地址 | 提前设定 |
| EMR_SERVERLESS_APP_SUBNET_ID | 将要创建的EMR Serverless Application所属子网ID | 提前设定 |
| EMR_SERVERLESS_APP_SECURITY_GROUP_ID | 将要创建的EMR Serverless Application所属安全组ID | 提前设定 |
| EMR_SERVERLESS_APP_ID | 将要创建的EMR Serverless Application的ID | 过程中产生 |
| EMR_SERVERLESS_EXECUTION_ROLE_ARN | 将要创建的EMR Serverless Execution Role的ARN | 过程中产生 |
| EMR_SERVERLESS_JOB_RUN_ID | 提交EMR Serverless作业后返回的作业ID | 过程中产生 |
接下来,我们将进入实操阶段,需要您拥有一个安装了AWS CLI并配置了用户凭证的Linux环境(建议使用Amazon Linux2),通过SSH登录后,先使用命令sudo yum -y install jq安装操作json文件的命令行工具:jq(后续脚本会使用到它),然后将以上全局变量悉数导出(请根据您的AWS账号和本地环境替换命令行中的相应值):
# 实操步骤(1)
export APP_NAME='change-to-your-app-name'
export APP_S3_HOME='change-to-your-app-s3-home'
export APP_LOCAL_HOME='change-to-your-app-local-home'
export SCHEMA_REGISTRY_URL='change-to-your-schema-registry-url'
export KAFKA_BOOTSTRAP_SERVERS='change-to-your-kafka-bootstrap-servers'
export EMR_SERVERLESS_APP_SUBNET_ID='change-to-your-subnet-id'
export EMR_SERVERLESS_APP_SECURITY_GROUP_ID='change-to-your-security-group-id'
以下是一份示例:
# 示例(非实操步骤)
export APP_NAME='apache-hudi-delta-streamer'
export APP_S3_HOME='s3://apache-hudi-delta-streamer'
export APP_LOCAL_HOME='/home/ec2-user/apache-hudi-delta-streamer'
export SCHEMA_REGISTRY_URL='http://localhost:8081'
export KAFKA_BOOTSTRAP_SERVERS='localhost:9092'
export EMR_SERVERLESS_APP_SUBNET_ID='subnet-0a11afe6dbb4df759'
export EMR_SERVERLESS_APP_SECURITY_GROUP_ID='sg-071f18562f41b5804'
至于 EMR_SERVERLESS_APP_ID、EMR_SERVERLESS_EXECUTION_ROLE_ARN、EMR_SERVERLESS_JOB_RUN_ID 三个变量将在后续的操作过程中产生并导出。
4. 创建专属工作目录和存储桶
作为一项最佳实践,我们先为应用程序(Job)创建一个专属的本地工作目录(即APP_LOCAL_HOME设定的路径)和一个S3存储桶(即APP_S3_HOME设定的桶),应用程序的脚本、配置文件、依赖包、日志以及产生的数据都统一存放在专属目录和存储桶中,这样会便于维护:
# 实操步骤(2)
mkdir -p $APP_LOCAL_HOME
aws s3 mb $APP_S3_HOME
5. 创建 EMR Serverless Execution Role
运行EMR Serverless作业需要配置一个IAM Role,这个Role将赋予EMR Serverless作业访问AWS相关资源的权限,我们的DeltaStreamer CDC作业应至少需要分配:
- 对S3专属桶的读写权限
- 对Glue Data Catalog的读写权限
- 对Glue Schema Registry的读写权限
您可以根据EMR Serverless的官方文档手动创建这个Role,然后将其ARN作为变量导出(请根据您的AWS账号环境替换命令行中的相应值):
# 实操步骤(3/a)
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='change-to-your-emr-serverless-execution-role-arn'
以下是一份示例:
# 示例(非实操步骤)
export EMR_SERVERLESS_EXECUTION_ROLE_ARN='arn:aws:iam::123456789000:role/EMR_SERVERLESS_ADMIN'
考虑到手动创建这个Role较为烦琐,本文提供如下一段脚本,可以在您的AWS账号中创建一个拥有管理员权限的Role:EMR_SERVERLESS_ADMIN,从而帮助您快速完成本节工作(注意:由于该Role具有最高权限,应谨慎使用,完成快速验证后,还是应该在生产环境中配置严格限定权限的专有Execution Role):
# 实操步骤(3/b)
EMR_SERVERLESS_EXECUTION_ROLE_NAME='EMR_SERVERLESS_ADMIN'
cat << EOF > $APP_LOCAL_HOME/assume-role-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EMRServerlessTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "emr-serverless.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
jq . $APP_LOCAL_HOME/assume-role-policy.json
export EMR_SERVERLESS_EXECUTION_ROLE_ARN=$(aws iam create-role \
--no-paginate --no-cli-pager --output text \
--role-name "$EMR_SERVERLESS_EXECUTION_ROLE_NAME" \
--assume-role-policy-document file://$APP_LOCAL_HOME/assume-role-policy.json \
--query Role.Arn)
aws iam attach-role-policy \
--policy-arn "arn:aws:iam::aws:policy/AdministratorAccess" \
--role-name "$EMR_SERVERLESS_EXECUTION_ROLE_NAME"
6. 创建 EMR Serverless Application
向EMR Serverless提交作业前,需要先创建一个EMR Serverless Application,这是EMR Serverless中的一个概念,可以理解为一个虚拟的EMR集群。在创建Application时,需要指定EMR的版本,网络配置,集群规模,预热节点等信息。通常,我们仅需如下一条命令就可以完成创建工作:
# 示例(非实操步骤)
aws emr-serverless create-application \
--name "$APP_NAME" \
--type "SPARK" \
--release-label "emr-6.11.0"
但是,这样创建出的Application是没有网络配置的,由于我们的DeltaStreamer CDC作业需要访问位于特定VPC中的Confluent Schema Registry和Kafka Bootstrap Servers,所以必须显式地为Application设定子网和安全组,以确保DeltaStreamer可以连通这两项服务。因此,我们需要使用以下命令创建一个带有特定网络配置的Application:
# 实操步骤(4)
cat << EOF > $APP_LOCAL_HOME/create-application.json
{
"name":"$APP_NAME",
"releaseLabel":"emr-6.11.0",
"type":"SPARK",
"networkConfiguration":{
"subnetIds":[
"$EMR_SERVERLESS_APP_SUBNET_ID"
],
"securityGroupIds":[
"$EMR_SERVERLESS_APP_SECURITY_GROUP_ID"
]
}
}
EOF
jq . $APP_LOCAL_HOME/create-application.json
export EMR_SERVERLESS_APP_ID=$(aws emr-serverless create-application \
--no-paginate --no-cli-pager --output text \
--release-label "emr-6.11.0" --type "SPARK" \
--cli-input-json file://$APP_LOCAL_HOME/create-application.json \
--query "applicationId")
7. 提交 Apache Hudi DeltaStreamer CDC 作业
创建好Application就可以提交作业了,Apache Hudi DeltaStreamer CDC是一个较为复杂的作业,配置项非常多,这一点从Hudi官方博客给出的示例中可见一斑,我们要做的是:将使用spark-submit命令提交的作业“翻译”成EMR Serverless的作业。
7.1 准备作业描述文件
使用命令行提交EMR Serverless作业需要提供一个json格式的作业描述文件,通常在spark-submit命令行中配置的参数都会由这个文件来描述。由于DeltaStreamer作业的配置项非常多,限于篇幅,我们无法一一做出解释,您可以将下面的作业描述文件和Hudi官方博客提供的原生Spark作业做一下对比,然后就能相对容易地理解作业描述文件的作用了。
需要注意的是,在执行下面的脚本时,请根据您的AWS账号和本地环境替换脚本中所有的<your-xxx>部分,这些被替换的部分取决于您本地环境中的源头数据库、数据表,Kakfa Topic以及Schema Registry等信息,每换一张表都需要调整相应的值,所以没有被抽离到全局变量中。
此外,该作业其实并不依赖任何第三方Jar包,其使用的Confluent Avro Converter已经集成到了hudi-utilities-bundle.jar中,这里我们特意在配置中声明--conf spark.jars=$(...)(参考示例命令)是为了演示“如何加载三方类库”,供有需要的读者参考。
# 实操步骤(5)
cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{
"name":"apache-hudi-delta-streamer",
"applicationId":"$EMR_SERVERLESS_APP_ID",
"executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN",
"jobDriver":{
"sparkSubmit":{
"entryPoint":"/usr/lib/hudi/hudi-utilities-bundle.jar",
"entryPointArguments":[
"--continuous",
"--enable-sync",
"--table-type", "COPY_ON_WRITE",
"--op", "UPSERT",
"--target-base-path", "<your-table-s3-path>",
"--target-table", "orders",
"--min-sync-interval-seconds", "60",
"--source-class", "org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource",
"--source-ordering-field", "_event_origin_ts_ms",
"--payload-class", "org.apache.hudi.common.model.debezium.MySqlDebeziumAvroPayload",
"--hoodie-conf", "bootstrap.servers=$KAFKA_BOOTSTRAP_SERVERS",
"--hoodie-conf", "schema.registry.url=$SCHEMA_REGISTRY_URL",
"--hoodie-conf", "hoodie.deltastreamer.schemaprovider.registry.url=${SCHEMA_REGISTRY_URL}/subjects/<your-registry-name>.<your-src-database>.<your-src-table>-value/versions/latest",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.topic=<your-kafka-topic-of-your-table-cdc-message>",
"--hoodie-conf", "auto.offset.reset=earliest",
"--hoodie-conf", "hoodie.datasource.write.recordkey.field=<your-table-recordkey-field>",
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field=<your-table-partitionpath-field>",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--hoodie-conf", "hoodie.datasource.write.hive_style_partitioning=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.database=<your-sync-database>",
"--hoodie-conf", "hoodie.datasource.hive_sync.table==<your-sync-table>",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields=<your-table-partition-fields>"
],
"sparkSubmitParameters":"--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.jars=<your-app-dependent-jars>"
}
},
"configurationOverrides":{
"monitoringConfiguration":{
"s3MonitoringConfiguration":{
"logUri":"<your-s3-location-for-emr-logs>"
}
}
}
}
EOF
jq . $APP_LOCAL_HOME/start-job-run.json
以下是一份示例:
# 示例(非实操步骤)
cat << EOF > $APP_LOCAL_HOME/start-job-run.json
{
"name":"apache-hudi-delta-streamer",
"applicationId":"$EMR_SERVERLESS_APP_ID",
"executionRoleArn":"$EMR_SERVERLESS_EXECUTION_ROLE_ARN",
"jobDriver":{
"sparkSubmit":{
"entryPoint":"/usr/lib/hudi/hudi-utilities-bundle.jar",
"entryPointArguments":[
"--continuous",
"--enable-sync",
"--table-type", "COPY_ON_WRITE",
"--op", "UPSERT",
"--target-base-path", "$APP_S3_HOME/data/mysql-server-3/inventory/orders",
"--target-table", "orders",
"--min-sync-interval-seconds", "60",
"--source-class", "org.apache.hudi.utilities.sources.debezium.MysqlDebeziumSource",
"--source-ordering-field", "_event_origin_ts_ms",
"--payload-class", "org.apache.hudi.common.model.debezium.MySqlDebeziumAvroPayload",
"--hoodie-conf", "bootstrap.servers=$KAFKA_BOOTSTRAP_SERVERS",
"--hoodie-conf", "schema.registry.url=$SCHEMA_REGISTRY_URL",
"--hoodie-conf", "hoodie.deltastreamer.schemaprovider.registry.url=${SCHEMA_REGISTRY_URL}/subjects/osci.mysql-server-3.inventory.orders-value/versions/latest",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.value.deserializer.class=io.confluent.kafka.serializers.KafkaAvroDeserializer",
"--hoodie-conf", "hoodie.deltastreamer.source.kafka.topic=osci.mysql-server-3.inventory.orders",
"--hoodie-conf", "auto.offset.reset=earliest",
"--hoodie-conf", "hoodie.datasource.write.recordkey.field=order_number",
"--hoodie-conf", "hoodie.datasource.write.partitionpath.field=order_date",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.MultiPartKeysValueExtractor",
"--hoodie-conf", "hoodie.datasource.write.hive_style_partitioning=true",
"--hoodie-conf", "hoodie.datasource.hive_sync.database=inventory",
"--hoodie-conf", "hoodie.datasource.hive_sync.table=orders",
"--hoodie-conf", "hoodie.datasource.hive_sync.partition_fields=order_date"
],
"sparkSubmitParameters":"--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.jars=$(aws s3 ls $APP_S3_HOME/jars/ | grep -o '\S*\.jar$'| awk '{print "'"$APP_S3_HOME/jars/"'"$1","}' | tr -d '\n' | sed 's/,$//')"
}
},
"configurationOverrides":{
"monitoringConfiguration":{
"s3MonitoringConfiguration":{
"logUri":"$APP_S3_HOME/logs"
}
}
}
}
EOF
jq . $APP_LOCAL_HOME/start-job-run.json
7.2 提交作业
准备好作业描述文件后,就可以正式提交作业了,命令如下:
# 实操步骤(6)
export EMR_SERVERLESS_JOB_RUN_ID=$(aws emr-serverless start-job-run \
--no-paginate --no-cli-pager --output text \
--name apache-hudi-delta-streamer \
--application-id $EMR_SERVERLESS_APP_ID \
--execution-role-arn $EMR_SERVERLESS_EXECUTION_ROLE_ARN \
--execution-timeout-minutes 0 \
--cli-input-json file://$APP_LOCAL_HOME/start-job-run.json \
--query jobRunId)
7.3 监控作业
作业提交后,可以在控制台查看作业运行状态。如果想在命令行窗口持续监控作业,可以使用如下脚本:
# 实操步骤(7)
now=$(date +%s)sec
while true; do
jobStatus=$(aws emr-serverless get-job-run \
--no-paginate --no-cli-pager --output text \
--application-id $EMR_SERVERLESS_APP_ID \
--job-run-id $EMR_SERVERLESS_JOB_RUN_ID \
--query jobRun.state)
if [ "$jobStatus" = "PENDING" ] || [ "$jobStatus" = "SCHEDULED" ] || [ "$jobStatus" = "RUNNING" ]; then
for i in {0..5}; do
echo -ne "\E[33;5m>>> The job [ $EMR_SERVERLESS_JOB_RUN_ID ] state is [ $jobStatus ], duration [ $(date -u --date now-$now +%H:%M:%S) ] ....\r\E[0m"
sleep 1
done
else
echo -ne "The job [ $EMR_SERVERLESS_JOB_RUN_ID ] is [ $jobStatus ]\n\n"
break
fi
done
7.4 错误检索
作业开始运行后,Spark Driver和Executor会持续生成日志,这些日志存放在配置的$APP_S3_HOME/logs路径下,如果作业失败,可以使用下面的脚本快速检索到错误信息:
# 实操步骤(8)
JOB_LOG_HOME=$APP_LOCAL_HOME/log/$EMR_SERVERLESS_JOB_RUN_ID
rm -rf $JOB_LOG_HOME && mkdir -p $JOB_LOG_HOME
aws s3 cp --recursive $APP_S3_HOME/logs/applications/$EMR_SERVERLESS_APP_ID/jobs/$EMR_SERVERLESS_JOB_RUN_ID/ $JOB_LOG_HOME >& /dev/null
gzip -d -r -f $JOB_LOG_HOME >& /dev/null
grep --color=always -r -i -E 'error|failed|exception' $JOB_LOG_HOME
7.5 停止作业
DeltaStreamer是一个持续运行的作业,如果需要停止作业,可以使用如下命令:
# 实操步骤(9)
aws emr-serverless cancel-job-run \
--no-paginate --no-cli-pager\
--application-id $EMR_SERVERLESS_APP_ID \
--job-run-id $EMR_SERVERLESS_JOB_RUN_ID
8. 结果验证
作业启动后会自动创建一个数据表,并在指定的S3位置上写入数据,使用如下命令可以查看自动创建的数据表和落地的数据文件:
# 实操步骤(10)
aws s3 ls --recursive <your-table-s3-path>
aws glue get-table --no-paginate --no-cli-pager \
--database-name <your-sync-database> --name <your-sync-table>
# 示例(非实操步骤)
aws s3 ls --recursive $APP_S3_HOME/data/mysql-server-3/inventory/orders/
aws glue get-table --no-paginate --no-cli-pager \
--database-name inventory --name orders
9. 评估与展望
本文,我们详细介绍了如何在EMR Serverless上运行Apapche Hudi DeltaStreamer将CDC数据接入到Hudi表中,这是一个主打“零编码”,“零运维”的超轻量解决方案。但是,它的局限性也很明显,那就是:一个DeltaStreamer作业只能接入一张表,这对于动辄就需要接入数百张甚至数千张表的数据湖来说是不实用的,尽管Hudi也提供了用于多表接入的MultiTableDeltaStreamer,但是这个工具类目前的成熟度和完备性还不足以应用于生产。此外,Hudi自0.10.0起针对Kafka Connect提供了Hudi Sink插件(目前也是仅支持单表),为CDC数据接入Hudi数据湖开辟了新的途径,这是值得持续关注的新亮点。
从长远来看,CDC数据入湖并落地为Hudi表是一个非常普遍的需求,迭代并完善包括DeltaStreamer、HoodieMultiTableDeltaStreamer和Kafka Connect Hudi Sink插件在内的多种原生组件在社区的呼声将会越来越强烈,相信伴随着Hudi的蓬勃发展,这些组件将不断成熟起来,并逐步应用到生产环境中。
关于作者:耿立超,架构师,著有 《大数据平台架构与原型实现:数据中台建设实战》一书,多年IT系统开发和架构经验,对大数据、企业级应用架构、SaaS、分布式存储和领域驱动设计有丰富的实践经验,个人技术博客:https://laurence.blog.csdn.net