DBT是什么:
按照官方的说法,DBT 是一个数据转换流编排工具。个人理解就是,DBT是帮你编排SQL用的,你可以按照DBT的结构,构建好一个SQL的pipeline,然后让DBT帮你执行这个pipeline。我这里说的SQL pipeline的意思就是,先执行SQL a,再执行SQL b,类似这种。个人理解这就是DBT最大也是最核心的功能!
因为在DBT中的操作基本都是关于SQL的操作,所以DBT才对外宣称自己是专门做ETL中的T(当然它也有支持一部分的python代码,但是貌似支队一小部分数据库提供支持)。
个人觉得如果公司内部现成已经有一套数据任务开发框架,或者使用的是 ali 的 dataworks 、网易的 easydata 之类的,貌似没必要强行再上DBT。如果你是个中小公司,没有现成的数据开发平台,或者你是个数据分析师,嫌弃商用数据开发平台使用成本太高而且数据想保存在公司本地电脑中,那么建议考虑一下DBT!
DBT还有一些特点:1. 把SQL开发像后端代码开发一样工程化,SQL工程存储在后端的代码仓库上,可以做到CI/CD。 2. 支持 jinja 宏函数,然后DBT定义了一套语法规范,抹平了一些SQL方言上的差异,做到一套DBT代码就可以在各个数据仓库上运行。当然对于这块功能我还是要打个问号的,后面研究的深入了再看看。 3. 无须写insert语句,直接写select语句即可,dbt会自动根据select建表,讲数据写入到数据库 4. 其他功能,后面慢慢说吧...
搭建第一个DBT工程:
这里说的DBT指的是开源的dbt core,另外还有一款闭源的收费产品叫 dbt cloud。
DBT是python代码编写的,所以想要使用dbt就要首先安装好python环境,个人使用的是3.10。
基于duckdb:
dbt官方的收费产品dbt cloud 仅支持 BigQuery、Databricks、Postgres 等十多个数据库适配器,其他例如 Doris、MySQL、Hive 等等都是社区各自自己提供的适配器(开源)支持dbt。
此处演示使用的数据库为duckdb。为什么是基于duckdb,是因为duckdb不需要安装,直接引个python包就好了。直接 pip install dbt-duckdb 安装好对应的python包即可,当然最好是在python虚拟环境中安装,防止与外部包冲突,同时安装dbt-duckdb 会自动把dbt-core 也安装好。
环境安装好之后,然后直接执行dbt init my_jaffle_shop 就会帮你创建好一个名叫my_jaffle_shop 的dbt demo工程,如下所示,dbt会自动帮你创建好目录结构。其中dbt-project.yml是整个dbt工程的配置文件,它里面说明dbt工程的一些环境变量的配置,这样dbt就知道如何去解析工程结构了(具体每项配置干嘛用的,后续再说):

同时在工程中还要新建一个文件叫profiles.yml,就是上面标红的第二个文件,整个文件是用于配置数据库连接信息用的,告诉dbt如何连接数据库。例如duckdb的配置如下所示:

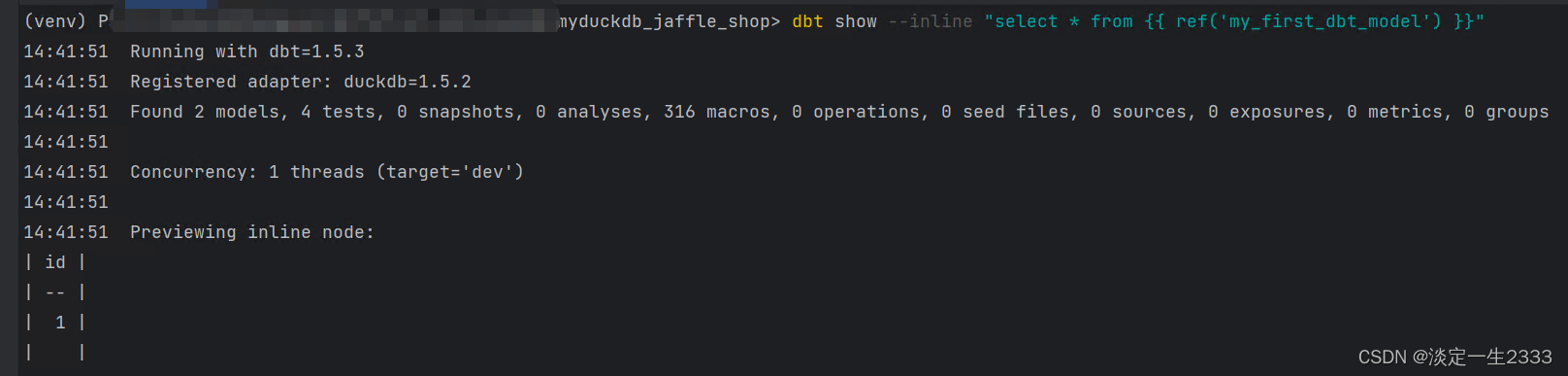
然后cd 到 myduckdb_jaffle_shop 目录下,执行 dbt run 命令,显示success,整个dbt工程就跑完了,数据就按demo工程中的SQL语句运行完毕写入到duckdb数据库中了:

使用命令行查看运行结果:
参考:
DBT是什么_dbt数据库_DBT中文社区的博客-CSDN博客
Quickstart for dbt Core from a manual install | dbt Developer Hub








![[Round#14 Illuminate with your bril]](https://img-blog.csdnimg.cn/a3ca2d9e3f8745d49cf78412f382e881.png)