以下仅为博主个人观点,如有错误欢迎批评指正。
前言后记都挺重要建议还是看一下吧。
文章目录
- 前言
- 经验模态分解
- EMD
- EEMD
- CEEMDAN
- 变分模态分解
- VMD
- 奇异谱分析
- SSA
- 后记
前言
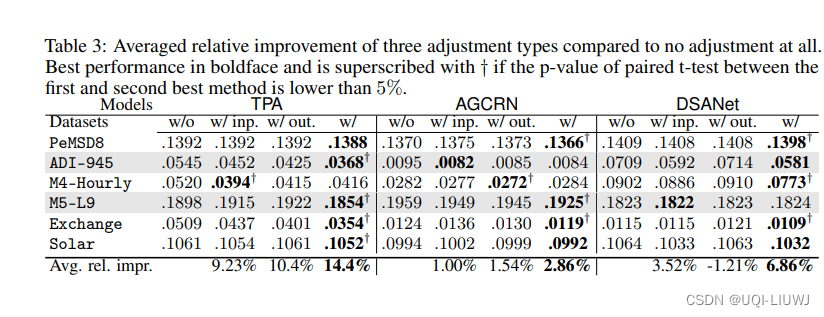
本篇文章将会介绍常用曲线分解方法(经验模态分解及其变种,变分模态分解,奇异谱分析)。我们使用如下数据。数据下载,提取码8848
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
data=pd.read_excel("data.xlsx").values[:,1].tolist()
plt.figure(figsize=(16,9));sns.set_style("darkgrid");plt.rcParams['font.family']='SimHei';plt.rcParams['font.sans-serif']=['SimHei']
plt.plot([i+1 for i in range(len(data))],data,linewidth=1)
plt.xticks([1,len(data)],["2011-01-04","2022-12-30"]);plt.xlabel("时间(单位:天)",size=12);plt.ylabel("收盘价(单位:元)",size=12);plt.title("沪深300每天收盘价曲线")
plt.savefig("figure",dpi=500)

文章侧重代码实践。知识理论给出超链,只要去学一定能懂。
经验模态分解
EMD
参考视频。参考文档。用途:处理非平稳的信号,将原信号分解成为多个不同频率信号以及残差,分解出来的信号被称为本征模态函数以及残差。想法:利用极值点的信息,极值点多频率就高;极值点少频率就低。优点:主观人为参数较少。关键:寻找本征模态函数,去看视频,视频讲解十分好的。分析:金融市场低频信号能够反映某种规律。
import pandas as pd
data=pd.read_excel("data.xlsx").values[:,1].tolist()
import numpy as np
data=np.array(data)
from PyEMD import EMD
emd=EMD()
emd.emd(data)
imfs,residue=emd.get_imfs_and_residue()
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16,9));sns.set_style("darkgrid");plt.rcParams['font.family']='SimHei';plt.rcParams['font.sans-serif']=['SimHei']
for i in range(imfs.shape[0]):
plt.subplot(imfs.shape[0]+1,1,i+1);plt.xticks([],[]);plt.ylabel("imf"+str(i+1))
plt.plot([i+1 for i in range(imfs.shape[1])],imfs[i].tolist())
plt.subplot(imfs.shape[0]+1,1,imfs.shape[0]+1);plt.xticks([1,len(data)],["2011-01-04","2022-12-30"]);plt.ylabel("residue")
plt.plot([i+1 for i in range(residue.shape[0])],residue.tolist())
plt.savefig("figure",dpi=500)

EEMD
EEMMD是什么??简述一下EEMD的流程:创建n个独立线程,每个线程添加随机噪声进入原有时序曲线从而得到新的时序曲线;对于每个线程所得到的新的时序曲线,用EMD分解;取个平均(每个线程所得分量对应相加再除以n)。为什么这么做??提高了鲁棒性。
import pandas as pd
data=pd.read_excel("data.xlsx").values[:,1].tolist()
import numpy as np
data=np.array(data)
from PyEMD import EEMD
eemd=EEMD()
eemd.eemd(data)
imfs,residue=eemd.get_imfs_and_residue()
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16,9));sns.set_style("darkgrid");plt.rcParams['font.family']='SimHei';plt.rcParams['font.sans-serif']=['SimHei']
for i in range(imfs.shape[0]):
plt.subplot(imfs.shape[0]+1,1,i+1);plt.xticks([],[]);plt.ylabel("imf"+str(i+1))
plt.plot([i+1 for i in range(imfs.shape[1])],imfs[i].tolist())
plt.subplot(imfs.shape[0]+1,1,imfs.shape[0]+1);plt.xticks([1,len(data)],["2011-01-04","2022-12-30"]);plt.ylabel("residue")
plt.plot([i+1 for i in range(residue.shape[0])],residue.tolist())
plt.savefig("figure",dpi=500)

CEEMDAN
理论大概是EEMD那套,然后有自己的改动。具体是啥没时间看,一般用就用这个吧。
import pandas as pd
data=pd.read_excel("data.xlsx").values[:,1].tolist()
import numpy as np
data=np.array(data)
from PyEMD import CEEMDAN
ceemdan=CEEMDAN()
ceemdan.ceemdan(data)
imfs,residue=ceemdan.get_imfs_and_residue()
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16,9));sns.set_style("darkgrid");plt.rcParams['font.family']='SimHei';plt.rcParams['font.sans-serif']=['SimHei']
for i in range(imfs.shape[0]):
plt.subplot(imfs.shape[0]+1,1,i+1);plt.xticks([],[]);plt.ylabel("imf"+str(i+1))
plt.plot([i+1 for i in range(imfs.shape[1])],imfs[i].tolist())
plt.subplot(imfs.shape[0]+1,1,imfs.shape[0]+1);plt.xticks([1,len(data)],["2011-01-04","2022-12-30"]);plt.ylabel("residue")
plt.plot([i+1 for i in range(residue.shape[0])],residue.tolist())
plt.savefig("figure",dpi=500)

还有一些其他东西。我在后记之中阐述。
变分模态分解
VMD
参考视频。参考文档。VMD的数学理论很强,没有兴趣没有时间,对它进行深入研究,所以这里跳过理论。VMD具有较好的抗噪能力,可以克服EMD的混叠问题。其他不管,会用就行。这里有些参数,我来讲一下吧。alpha[带宽限制]:经验取值为抽样点长度1.5-2.0倍,tau[噪声容限]:取0就好;K[分量个数]:这个真不好说,跟着感觉走吧。DC:合成信号有常量就取1;合成信号没常量取0,一般取0就好,不管。init:取1就好[均匀分布产生的随机数]。tol[控制误差常量大小]:取1e-7就好,可以更小或者更大。
import pandas as pd
data=pd.read_excel("data.xlsx").values[:,1].tolist()
import numpy as np
data=np.array(data)
from vmdpy import VMD
alpha,tau,K,DC,init,tol=data.shape[0]*1.75,0,10,0,1,1e-7
u,u_hat,omega=VMD(data,alpha,tau,K,DC,init,tol)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16,9));sns.set_style("darkgrid");plt.rcParams['font.family']='SimHei';plt.rcParams['font.sans-serif']=['SimHei']
for i in range(u.shape[0]):
plt.subplot(u.shape[0]+1,1,i+1);plt.xticks([],[]);plt.ylabel("imf"+str(i+1))
plt.plot([i+1 for i in range(u.shape[1])],u[i].tolist())
plt.savefig("figure",dpi=500)

奇异谱分析
SSA
流程以及理论部分:我们这里参考知乎。工程部分:通常一般用于解决非线性的时序数据。代码部分:奇异谱分析没有安装包,得自己写,所以流程读者请看代码;这里x是窗口长度[也是分解分量个数]。
def SSA(data,x):
windowlen=x;datalen=data.shape[0]
K=datalen-windowlen+1;X=np.zeros((windowlen,K))
for i in range(K):
X[:,i]=data[i:i+windowlen]
U,sigma,VT=np.linalg.svd(X,full_matrices=False)
for i in range(VT.shape[0]):
VT[i,:]*=sigma[i]
A=VT
REC=np.zeros((windowlen,datalen))
for i in range(windowlen):
for j in range(windowlen-1):
for m in range(j+1):
REC[i,j]+=A[i,j-m]*U[m,i]
REC[i,j]/=(j+1)
for j in range(windowlen-1,datalen-windowlen+1):
for m in range(windowlen):
REC[i,j]+=A[i,j-m]*U[m,i]
REC[i,j]/=windowlen
for j in range(datalen-windowlen+1,datalen):
for m in range(j-datalen+windowlen,windowlen):
REC[i,j]+=A[i,j-m]*U[m,i]
REC[i,j]/=(datalen-j)
return REC
import pandas as pd
data=pd.read_excel("data.xlsx").values[:,1].tolist()
import numpy as np
data=np.array(data)
REC=SSA(data,10)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16,9));sns.set_style("darkgrid");plt.rcParams['font.family']='SimHei';plt.rcParams['font.sans-serif']=['SimHei']
for i in range(REC.shape[0]):
plt.subplot(REC.shape[0]+1,1,i+1);plt.xticks([],[]);plt.ylabel("imf"+str(i+1))
plt.plot([i+1 for i in range(REC.shape[1])],REC[i].tolist())
plt.savefig("figure",dpi=500)

后记
1).经验模态分解变种不只3个(如:ICEEMDAN),读者下来可以自行进行研究。这里给出两篇文献,博主强烈建议去看。提取码8848。(看了就懂这类套路,其他文章没必要看)(接下我会阐述原因)
2).套路就是:1.选个分解方法进行曲线分解;2.选个预测方法预测分解曲线;3.每个分量的预测值全加起来就是最终的预测值。 以下是某论文流程,其实就是这个套路,其他论文也是一样。我推荐的写得很好,两篇文章都是走量。你能接触各种各样,分解方法预测方法。 其他文章真的水得我都不想再说话了。接下来我教你怎么来水文章(如果你想)。

3)模板:基于(优化算法-)分解方法-预测方法的某预测。例如:1.基于变分模态分解-误差反向传播神经网络下的上证指数预测。2.基于遗传优化-经验模态分解-循环神经网络下的风速预测。3.Global Tempreture Prediction Based on GA-VMD-LSTM。可产文章数量分析:智能优化数量为A,分解方法数量为B,预测方法数量为C,数据数量更多为D,则可水ABCD篇文章了。 这些文章我真见多,没有必要浪费时间。这些其实都还好吧,我还见过更加艹的。算了我是没有找到,不然高低得把流程图拿出来给各位开眼。大致就是:我比如哈:我使用EMD分解出了10条曲线,对于每条曲线再用VMD来分解(VMD取10吧),一共产生100条曲线,然后每条进行预测。(真小天才,我的评价是不如EMD-VND-EMD-……,时间复杂度一下就上去)
4)我就一本科生,别喷(很多事不成熟)。