文章目录
Flink用武之地
一、Event-driven Applications【事件驱动】
二、Data Analytics Applications【数据分析】
三、Data Pipeline Applications【数据管道】
Flink用武之地
应用场景 | Apache Flink
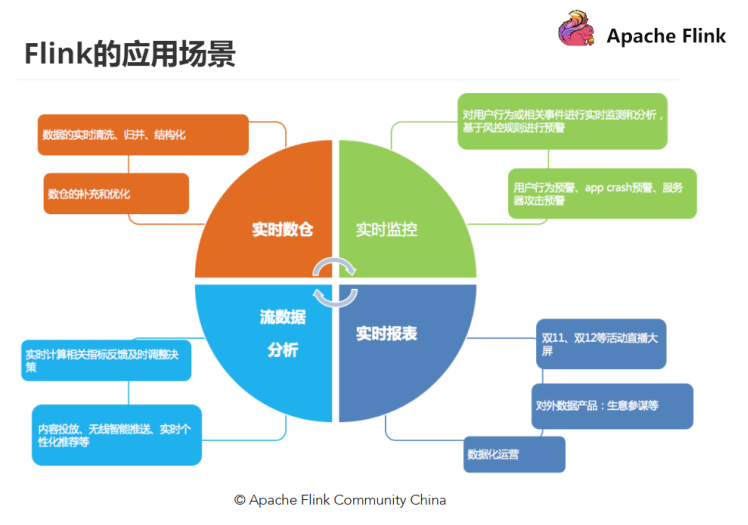
从很多公司的应用案例发现,其实Flink主要用在如下三大场景:
一、Event-driven Applications【事件驱动】
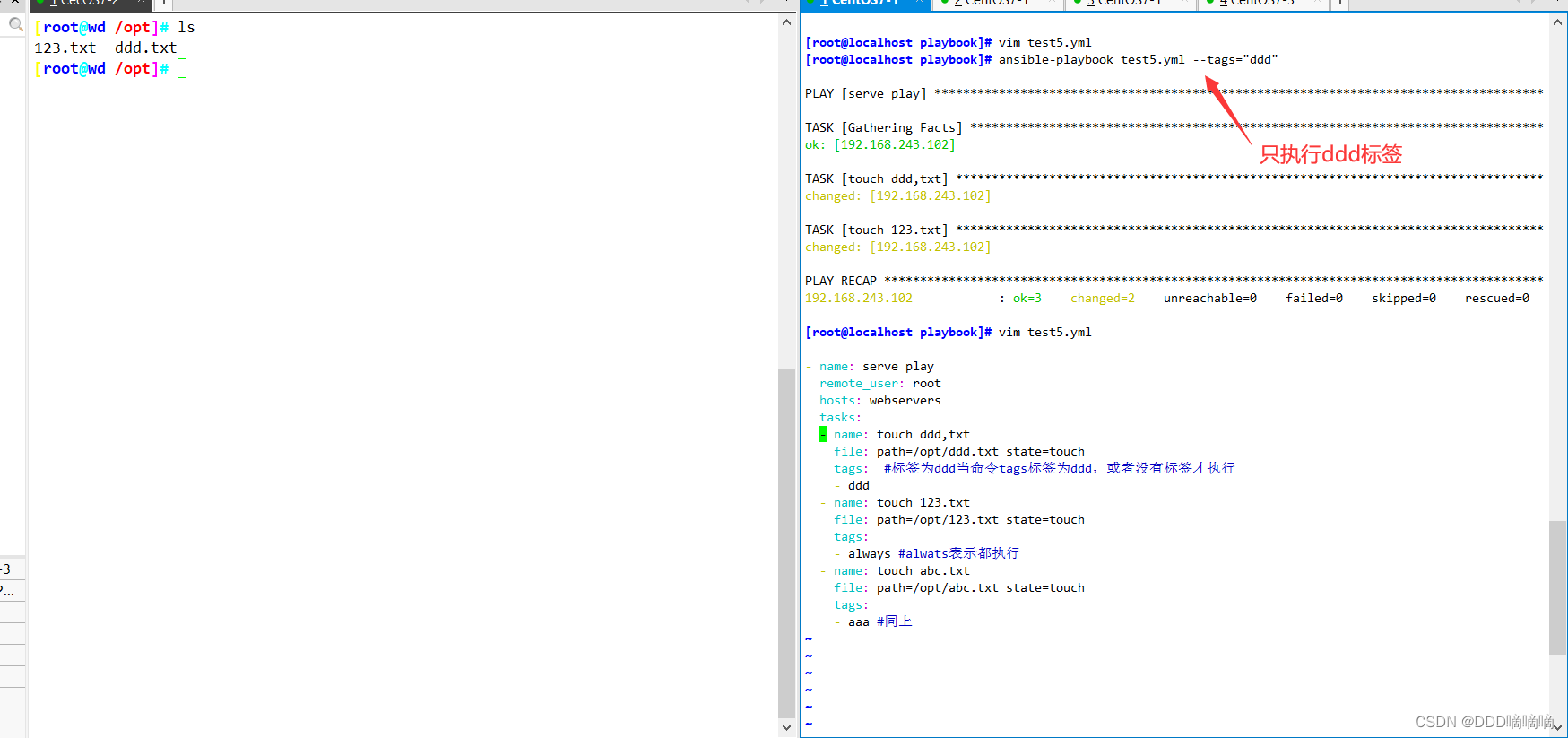
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。
在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。
系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
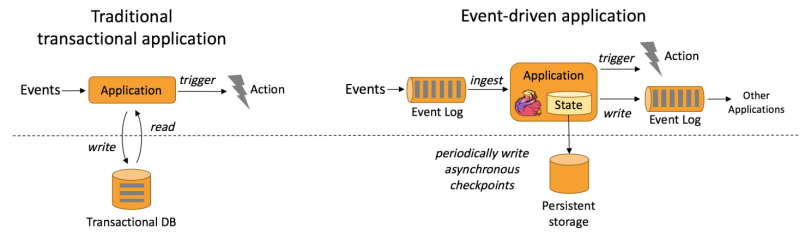
从某种程度上来说,所有的实时的数据处理或者是流式数据处理都应该是属于Data Driven,流计算本质上是Data Driven 计算。应用较多的如风控系统,当风控系统需要处理各种各样复杂的规则时,Data Driven 就会把处理的规则和逻辑写入到Datastream 的API 或者是ProcessFunction 的API 中,然后将逻辑抽象到整个Flink 引擎,当外面的数据流或者是事件进入就会触发相应的规则,这就是Data Driven 的原理。在触发某些规则后,Data Driven 会进行处理或者是进行预警,这些预警会发到下游产生业务通知,这是Data Driven 的应用场景,Data Driven 在应用上更多应用于复杂事件的处理。
典型实例:
- 欺诈检测(Fraud detection)
- 异常检测(Anomaly detection)
- 基于规则的告警(Rule-based alerting)
- 业务流程监控(Business process monitoring)
- Web应用程序(社交网络)

二、Data Analytics Applications【数据分析】
数据分析任务需要从原始数据中提取有价值的信息和指标。
如下图所示,Apache Flink 同时支持流式及批量分析应用。
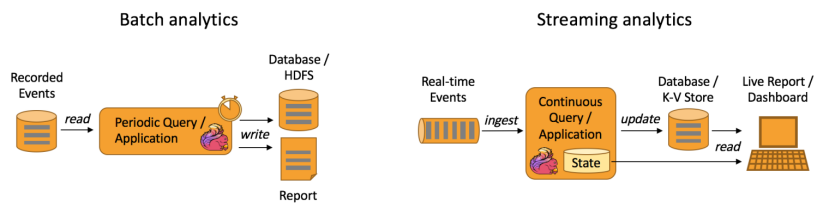
Data Analytics Applications包含Batch analytics(批处理分析)和Streaming analytics(流处理分析)
Batch analytics可以理解为周期性查询:Batch Analytics 就是传统意义上使用类似于Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表。比如Flink应用凌晨从Recorded Events中读取昨天的数据,然后做周期查询运算,最后将数据写入Database或者HDFS,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics可以理解为连续性查询:比如实时展示双十一天猫销售GMV(Gross Merchandise Volume成交总额),用户下单数据需要实时写入消息队列,Flink 应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
典型实例
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
三、Data Pipeline Applications【数据管道】
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。
ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。
但数据管道是以持续流模式运行,而非周期性触发。
因此数据管道支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。
例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。
此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。
下图描述了周期性ETL作业和持续数据管道的差异。
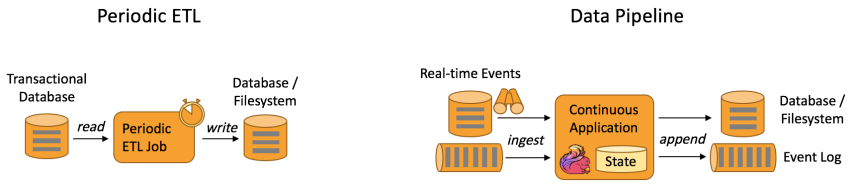
Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
Data Pipeline 的核心场景类似于数据搬运并在搬运的过程中进行部分数据清洗或者处理,而整个业务架构图的左边是Periodic ETL,它提供了流式ETL 或者实时ETL,能够订阅消息队列的消息并进行处理,清洗完成后实时写入到下游的Database或File system 中。
典型实例
- 电子商务中的持续 ETL(实时数仓)
当下游要构建实时数仓时,上游则可能需要实时的Stream ETL。这个过程会进行实时清洗或扩展数据,清洗完成后写入到下游的实时数仓的整个链路中,可保证数据查询的时效性,形成实时数据采集、实时数据处理以及下游的实时Query。
- 电子商务中的实时查询索引构建(搜索引擎推荐)
搜索引擎这块以淘宝为例,当卖家上线新商品时,后台会实时产生消息流,该消息流经过Flink 系统时会进行数据的处理、扩展。然后将处理及扩展后的数据生成实时索引,写入到搜索引擎中。这样当淘宝卖家上线新商品时,能在秒级或者分钟级实现搜索引擎的搜索。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨