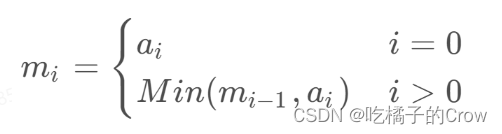欢迎来到人工智能的未来:生成式人工智能!您是否想知道机器如何学习理解人类语言并做出相应的反应?让我们来看看ChatGPT ——OpenAI 开发的革命性语言模型。凭借其突破性的 GPT-3.5 架构,ChatGPT 席卷了世界,改变了我们与机器通信的方式,并为人机交互开辟了无限可能。随着 ChatGPT 的竞争对手 Google BARD 最近推出,由 PaLM 2 提供支持,这场竞赛已经正式开始。在本文中,我们将深入探讨 ChatGPT 的内部工作原理、它是如何工作的、涉及哪些不同步骤,例如预训练和 RLHF,以及探索它如何理解和生成类似人类的文本具有非凡的准确性。
探索 ChatGPT 的内部运作方式,并探索它如何以极高的准确性理解和生成类似人类的文本。准备好对 ChatGPT 背后的尖端技术感到惊讶,并发现这种强大的语言模型的无限潜力。
本文的主要目标是 -
- 讨论 ChatGPT 模型训练涉及的步骤。
- 了解使用人类反馈强化学习 (RLHF) 的优势。
- 了解人类如何参与改进 ChatGPT 等模型。
ChatGPT 训练概述
ChatGPT 是一种针对对话进行优化的大型语言模型(LLM)。它使用人类反馈强化学习 (RLHF) 构建在 GPT 3.5 之上。它接受了大量互联网数据的训练。
构建 ChatGPT 主要涉及 3 个步骤 -
- 预培训法学硕士
- LLM(SFT)的监督微调
- 根据人类反馈进行强化学习 (RLHF)
第一步是在无监督数据上预训练 LLM (GPT 3.5),以预测句子中的下一个单词。这使得法学硕士能够学习文本的表示和各种细微差别。
预培训法学硕士
语言模型是预测序列中下一个单词的统计模型。大型语言模型是经过数十亿单词训练的深度学习模型。训练数据来自多个网站,如 Reddit、StackOverflow、Wikipedia、Books、ArXiv、Github 等。


我们可以看到上图并了解数据集的侧面和参数的数量。LLM 的预训练计算成本很高,因为它需要大量的硬件和庞大的数据集。在预训练结束时,我们将获得一个 LLM,可以在提示时预测句子中的下一个单词。例如,如果我们提示一个句子“玫瑰是红色的并且”,它可能会回复“紫罗兰是蓝色的”。下图描述了 GPT-3 在预训练结束时可以做什么:


我们可以看到该模型正在尝试完成句子而不是回答它。但我们需要知道答案而不是下一句话。实现这一目标的下一步可能是什么?让我们在下一节中看到这一点。
LLM 的监督微调
那么,我们如何让LLM回答问题而不是预测下一个单词呢?模型的监督微调将帮助我们解决这个问题。我们可以告诉模型对给定提示的期望响应并对其进行微调。为此,我们可以创建一个包含多种类型问题的数据集来询问对话模型。人工贴标者可以提供适当的响应,使模型理解预期的输出。这个由成对的提示和响应组成的数据集称为演示数据。现在,让我们看看演示数据中的提示示例数据集及其响应。


根据人类反馈进行强化学习 (RLHF)
现在,我们将了解 RLHF。在了解RLHF之前,我们先来看看使用RLHF的好处。
为什么选择RLHF?
经过监督微调后,我们的模型应该针对给定的提示给出适当的响应,对吧?很不幸的是,不行!我们的模型可能仍然无法正确回答我们提出的每个问题。它可能仍然无法评估哪个响应是好的,哪个响应不是。它可能必须过度拟合演示数据。让我们看看如果它过度拟合数据会发生什么。


我没有给它任何链接、文章或句子来总结。但它只是总结了一些东西就给了我,这是我始料未及的。
可能出现的另一问题是其毒性。尽管答案可能是正确的,但在伦理和道德上可能并不正确。例如,请看下面的图片,您可能以前见过。当询问下载电影的网站时,它首先回答说这是不道德的,但在下一个提示中,我们可以轻松地操纵它,如图所示。


好的,现在转到 ChatGPT 并尝试相同的示例。它给了你同样的结果吗?
为什么我们没有得到相同的答案?他们重新训练了整个网络吗?可能不会!RLHF 可能有一个小的微调。您可以参考这个美丽的要点了解更多原因。
奖励模式
RLHF 的第一步是训练奖励模型。该模型应该能够将提示的响应作为输入,并输出一个标量值来描述响应的好坏。为了让机器了解什么是好的响应,我们可以要求注释者用奖励来注释响应吗?一旦我们这样做,奖励不同注释者的反应可能会存在偏差。因此,模型可能无法学习如何奖励响应。相反,注释者可以对模型的响应进行排名,这将在很大程度上减少注释中的偏差。下图显示了来自 Anthropic 的 hh-rlhf 数据集的给定提示的选定响应和拒绝响应。




该模型尝试根据这些数据区分好的响应和坏的响应。
使用 RL 的奖励模型微调 LLM
现在,我们用近端策略近似(PPO)对法学硕士进行微调。在这种方法中,我们获得初始语言模型和微调迭代的当前迭代生成的响应的奖励。我们将当前语言模型与初始语言模型进行比较,以便语言模型不会偏离正确答案太多,同时生成整洁、干净且可读的输出。KL 散度用于比较两个模型,然后微调 LLM。
模型评估
在每个步骤结束时都会使用不同数量的参数不断评估模型。您可以在下图中看到这些方法及其各自的分数:


我们可以在上图中比较不同阶段的法学硕士与不同模型大小的表现。正如您所看到的,每个训练阶段后结果都有显着增加。
我们可以用人工智能 RLAIF 来替代 RLHF 中的人类。这显着降低了标签成本,并且有可能比 RLHF 表现更好。让我们在下一篇文章中讨论这个问题。
结论
在本文中,我们了解了如何训练 ChatGPT 等会话式 LLM。我们看到了训练 ChatGPT 的三个阶段,以及基于人类反馈的强化学习如何帮助模型提高其性能。我们也了解每个步骤的重要性,没有这些步骤,法学硕士将是不准确的。
经常问的问题
答:ChatGPT 从 Reddit、StackOverflow、Wikipedia、Books、ArXiv、Github 等多个网站获取数据。它使用这些数据来学习模式、语法和事实。
A. ChatGPT本身并不提供直接的赚钱方式。然而,个人或组织可以利用 ChatGPT 的功能来开发可以产生收入的应用程序或服务,例如博客、虚拟助理、客户支持机器人或内容生成工具。
答:ChatGPT 是一种针对对话而优化的大型语言模型。它接受提示作为输入并返回响应/答案。它使用GPT 3.5和人类反馈强化学习(RLHF)作为核心工作原理。
答:ChatGPT 在幕后使用深度学习和强化学习。它分三个阶段开发:预训练大型语言模型(GPT 3.5)、监督微调、人类反馈强化学习(RLHF)。