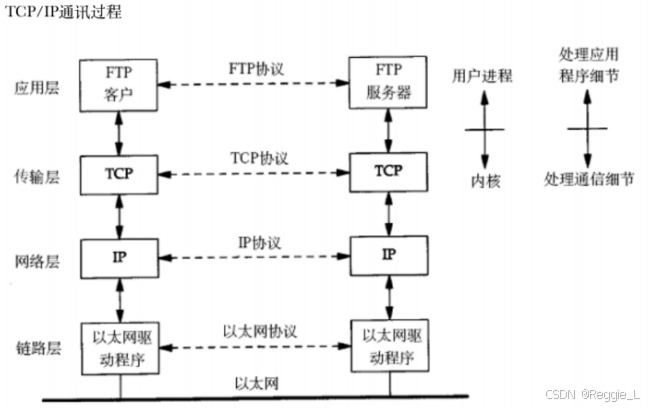
《亿级流量系统架构设计与实战》总结
1. 唯一ID的核心需求
• 全局唯一性:分布式系统中所有节点生成的ID不可重复。
• 趋势递增性(可选):ID按时间或序列递增,优化数据库写入性能。
• 高可用性:服务需7×24小时可用,支持故障自动恢复。
• 高性能:单节点QPS需达到数万至百万级别。
• 可扩展性:支持水平扩展以应对业务增长。
2. 单机递增方案
2.1 Redis INCR命令
• 原理:利用Redis原子操作INCR或INCRBY生成单调递增ID。
• 实现:
# 生成ID
redis-cli INCR my_counter
• 技术细节:
• 集群模式:通过Redis Cluster分片存储多个计数器(如user_id:1, order_id:2)。
• 持久化:开启AOF或RDB确保重启后ID不丢失。
• 优点:简单高效,延迟低(毫秒级)。
• 缺点:
• 依赖Redis集群,增加系统复杂度。
• 高并发下可能成为瓶颈(需维护长连接池)。
• 适用场景:低并发系统或作为其他方案的兜底。
2.2 数据库自增主键
• 原理:利用关系型数据库(如MySQL)的自增主键特性。
• 实现:
ALTER TABLE user AUTO_INCREMENT = 1000;
INSERT INTO user (name) VALUES ('Alice');
• 技术细节:
• 分库分表友好性:可通过MOD运算拆分表(如user_id % 1024)。
• 主从延迟:主从同步可能导致短暂ID不连续。
• 优点:绝对有序,天然事务支持。
• 缺点:
• 扩展性差,需预分配ID段或频繁修改表结构。
• 高并发写入易成为性能瓶颈。
• 适用场景:传统单体应用或低并发场景。
3. 分布式递增方案
3.1 Snowflake算法
• 核心组成:
long id = ((timestamp - twepoch) << timestampLeftOffset)
| (datacenterId << datacenterIdShift)
| (machineId << machineIdShift)
| sequence;
• 参数说明:
• timestamp:毫秒级时间戳(41位,支持约69年)。
• datacenterId:数据中心ID(5位,支持32个机房)。
• machineId:工作机器ID(5位,支持32台机器)。
• sequence:序列号(12位,同一毫秒内支持4096个ID)。
• 技术实现:
• 时钟回拨问题:记录历史时间戳,若发生回拨则抛出异常等待时钟同步。
• 位分配优化:根据业务需求调整各字段位数(如延长timestamp到42位)。
• 优点:
• 分布式生成,性能高(单机QPS可达百万)。
• ID趋势递增,利于数据库写入。
• 缺点:
• 依赖机器时钟,时钟回拨可能导致ID重复。
• 需手动分配datacenterId和machineId。
• 适用场景:高并发、需趋势递增的场景(如订单号、消息ID)。
3.2 Leaf(美团分布式ID生成服务)
• Leaf-segment方案:
• 原理:预分配ID号段(如1000~1999),客户端批量拉取号段。
• 架构:
Client → Leaf Server(号段分配) → DB(存储号段状态)
• 优化:支持号段预加载(如提前拉取下一个号段)。
• Leaf-snowflake方案:
• 原理:基于Snowflake算法,通过ZooKeeper选举Master节点分配machineId。
• 架构:
Client → Leaf Server(Snowflake节点) ← ZooKeeper(协调)
• 技术细节:
• 号段分配:支持号段长度动态调整(如从1000调整为10000)。
• 时钟回拨检测:Leaf-snowflake集成Snowflake的时钟回拨处理逻辑。
• 优点:
• 高可用,支持号段和Snowflake双模式切换。
• 支持号段/雪花模式混合部署。
• 缺点:
• 依赖外部存储(如DB/ZooKeeper)。
• 需部署中间件服务。
• 适用场景:中大规模分布式系统,需兼顾灵活性和高可用性。
4. 其他方案
4.1 UUID
• 原理:基于MAC地址、时间戳和随机数生成128位唯一标识。
• 实现:
UUID.randomUUID().toString() // 输出类似 "123e4567-e89b-12d3-a456-426614174000"
• 优点:本地生成,无依赖。
• 缺点:
• 无序导致数据库索引性能下降。
• 存储空间大(16字节)。
• 适用场景:离线系统或对顺序无要求的场景。
4.2 Redis Hash/Redisson
• 原理:利用Redis的Hash数据结构生成ID。
• 实现:
HSET my_hash field 1
HINCRBY my_hash field 1
• 优点:支持原子递增,可扩展多个Hash实例。
• 缺点:需维护Redis集群,性能低于原生INCR。
5. 方案对比与选型建议
| 方案 | 全局唯一性 | 趋势递增 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|---|
| Redis INCR | ✔️ | ✔️ | 高 | 中 | 低并发系统 |
| 数据库自增 | ✔️ | ✔️ | 低 | 高 | 传统单体应用 |
| Snowflake | ✔️ | ✔️ | 极高 | 中 | 高并发、需趋势递增的场景 |
| Leaf-segment | ✔️ | ❌ | 高 | 高 | 中大规模分布式系统 |
| Leaf-snowflake | ✔️ | ✔️ | 极高 | 高 | 需混合部署的复杂系统 |
6. 架构图示
6.1 Snowflake算法架构
Client → Time Service(获取时间戳)
↓
Machine ID(通过配置或ZooKeeper分配)
↓
Sequence Generator(本地计数器)
↓
ID合成器 → [timestamp << 22] | [machineId << 17] | [sequence]
6.2 Leaf分布式服务架构
Client → Leaf Client SDK → Leaf Server(HTTP/RPC接口)
↑ ↓
└─── ZooKeeper(协调Master选举) ────┘
7. 最佳实践
- 时钟回拨防御:
• 记录历史时间戳,若检测到回拨则抛出异常等待时钟同步。
• 使用NTP服务校准时钟,减少回拨概率。 - 分库分表友好:
• ID高位分配分片字段(如末尾N位表示分片号)。 - 预生成ID池:
• 对高并发场景预加载ID池(如提前生成10万ID缓存在本地)。
通过以上方案对比和技术实现细节,可根据业务场景选择最适合的唯一ID生成策略。对于大多数互联网业务,推荐使用Leaf-snowflake或Snowflake算法,兼顾性能与可用性。